


Next: 2 Additional Related Work
Up: FastReplica: Efficient Large File
Previous: FastReplica: Efficient Large File
1 Introduction
Content Delivery Networks (CDNs) are based on a large-scale distributed
network of servers located closer to the edges of the Internet for
efficient delivery of digital content including various forms of
multimedia content. The main goal of the CDN's architecture is to
minimize the network impact in the critical path of content delivery
as well as to overcome a server overload problem that is a serious
threat for busy sites serving popular content.
For typical web documents (e.g. html pages and images) served via CDN,
there is no need for active replication of the original content at the
edge servers. The CDN's edge servers are the caching servers, and if
the requested content is not yet in the cache, this document is
retrieved from the original server, using the so-called pull
model. The performance penalty associated with initial document
retrieval from the original server, such as higher latency observed by
the client and the additional load experienced by the original server,
is not significant for small to medium size web documents.
For large documents, software download packages and media files, a
different operational mode is preferred: it is desirable to replicate
these files at edge servers in advance, using the so-called push
model. For large files it is a challenging, resource-intensive
problem, e.g. media files can require significant bandwidth and
download time due to their large sizes: 20 min media file encoded at
1 Mbit/s results in a file of 150 MBytes.
The sites supported for efficiency reasons by multiple mirror servers,
face a similar problem: the original content needs to be replicated
across the multiple, geographically distributed, mirror servers.
While transferring a large file with individual point-to-point
connections from an original server can be a viable solution in the case
of limited number of mirror servers (tenths of servers), this method
does not scale when the content needs to be replicated across a CDN
with thousands of geographically distributed machines.
Currently, the three most popular methods used for content
distribution (replication) in the Internet environment are:
- satellite distribution,
- multicast distribution,
- application-level multicast distribution.
With satellite distribution [8,21], the content
distribution server (or the original site) has a transmitting antenna.
The servers, to which the content should be replicated, (or the
corresponding Internet Data Centers, where the servers are located)
have a satellite receiving dish. The original content distribution
server broadcasts a file via a satellite channel. Among the shortcomings
of the satellite distribution method are that it requires special
hardware deployment and the supporting infrastructure (or service) is
quite expensive.
With multicast distribution, an application can send one
copy of each packet and address it to the group of nodes (IP
addresses) that want to receive it. This technique reduces network
traffic by simultaneously delivering a single stream of information to
hundreds/thousands of interested recipients. Multicast can be
implemented at both the data-link layer and the network layer.
Applications that take advantage of multicast technologies include
video conferencing, corporate communications, distance learning, and
distribution of software, stock quotes, and news. Among the shortcomings
of the multicast distribution method are that it requires a
multicast support in routers, which still is not widely
available across the Internet infrastructure.
Since the native IP multicast has not received wide-spread deployment,
many industrial and research efforts shifted to investigating and
deploying the application level multicast, where nodes across
the Internet act as intermediate routers to efficiently distribute
content along a predefined mesh or tree. A growing number of
researchers [7,9,12,13,17,10,6,14] have advocated this alternative approach, where all multicast
related functionality, including group management and packet
replication, is implemented at end systems. In this architecture,
nodes participating in the multicast group self organize themselves
into an scalable overlay structure using a distributed
protocol. Further, the nodes attempt to optimize the efficiency of the
overlay by adapting to changing network conditions and considering the
application level requirements.
An interesting extension for the end-system multicast is introduced
in [6], where authors, instead of using the end systems as
routers forwarding the packets, propose that the end-systems do actively
collaborate in informed manner to improve the performance of large
file distribution. The main idea is to overcome the limitation of the
traditional service models based on tree topologies where the transfer
rate to the client is defined by the bandwidth of the bottleneck link
of the path from the server. The authors propose to use additional
cross-connections between the end-systems to exchange the
complementary content these nodes have already received. Assuming that
any given pair of end-systems has not received exactly the same
content, these cross-connections between the end-systems can be used
to ``reconcile'' the differences in received content in order to
reduce the total transfer time.
In our work, we consider a geographically distributed network of
servers and a problem of content distribution across it. Our focus is
on distributing large size files such as software packages or stored
streaming media files (also called as on-demand streaming media). We
propose a novel algorithm, called FastReplica, for efficient and
reliable replication of large files. There are a few basic ideas
exploited in FastReplica. In order to replicate a large file
among 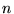 nodes ( is in the range of 10-30 nodes), the original
file is partitioned into subfiles of equal size and each subfile
is transferred to a different node in the group (this way, we
introduce a ``guaranteed'', predictable difference in received content
as compared to [6]). After that, each node propagates its
subfile to the remaining nodes in the group. Thus instead of the
typical replication of an entire file to nodes by using
Internet paths connecting the original node to the replication group,
FastReplica exploits
nodes ( is in the range of 10-30 nodes), the original
file is partitioned into subfiles of equal size and each subfile
is transferred to a different node in the group (this way, we
introduce a ``guaranteed'', predictable difference in received content
as compared to [6]). After that, each node propagates its
subfile to the remaining nodes in the group. Thus instead of the
typical replication of an entire file to nodes by using
Internet paths connecting the original node to the replication group,
FastReplica exploits 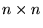 diverse Internet paths within
the replication group where each path is used for transferring
diverse Internet paths within
the replication group where each path is used for transferring 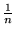 -th of the file (in such a way, similarly to [6], we exploit
explicitly the additional cross-connections between the end-systems to
exchange the complementary content these nodes have already received).
The paper is organized as follows. Section 2 describes
additional related work. In Section 3.2, we introduce a core
(an induction step) of the algorithm, called FastReplica in the
small, and demonstrate its work in the small-scale environment, where
a set of nodes in a replication set is rather small and limited,
e.g. 10 - 30 nodes. In Section 3.3, we perform a
preliminary analysis of FastReplica in the small and its
potential performance benefits, and outline the configurations and
network conditions when FastReplica may be inefficient. Then in
Section 3.4, using FastReplica in the small as the
induction step, we design a scalable FastReplica algorithm which
can be used for replication of large files to a large number of nodes.
Finally, in Section 3.5, we show how to extend the
algorithm for resilience to nodes' failures.
Through experiments on a prototype implementation, we analyze the
performance of FastReplica in the small in a wide-area testbed
in Section 4. For comparison reasons, we introduce
Multiple Unicast and Sequential Unicast schemas. Under
Multiple Unicast, the source node simultaneously transfers the entire
file to all the recipient nodes via concurrent connections. This
schema is traditionally used in the small-scale environment.
Sequential Unicast schema approximates the file distribution under IP
multicast. The experiments show that FastReplica significantly
reduces the file replication time. On average, it outperforms
Multiple Unicast by
-th of the file (in such a way, similarly to [6], we exploit
explicitly the additional cross-connections between the end-systems to
exchange the complementary content these nodes have already received).
The paper is organized as follows. Section 2 describes
additional related work. In Section 3.2, we introduce a core
(an induction step) of the algorithm, called FastReplica in the
small, and demonstrate its work in the small-scale environment, where
a set of nodes in a replication set is rather small and limited,
e.g. 10 - 30 nodes. In Section 3.3, we perform a
preliminary analysis of FastReplica in the small and its
potential performance benefits, and outline the configurations and
network conditions when FastReplica may be inefficient. Then in
Section 3.4, using FastReplica in the small as the
induction step, we design a scalable FastReplica algorithm which
can be used for replication of large files to a large number of nodes.
Finally, in Section 3.5, we show how to extend the
algorithm for resilience to nodes' failures.
Through experiments on a prototype implementation, we analyze the
performance of FastReplica in the small in a wide-area testbed
in Section 4. For comparison reasons, we introduce
Multiple Unicast and Sequential Unicast schemas. Under
Multiple Unicast, the source node simultaneously transfers the entire
file to all the recipient nodes via concurrent connections. This
schema is traditionally used in the small-scale environment.
Sequential Unicast schema approximates the file distribution under IP
multicast. The experiments show that FastReplica significantly
reduces the file replication time. On average, it outperforms
Multiple Unicast by 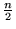 times, where is the number of
nodes in the replication set. Additionally, FastReplica
demonstrates better or comparable performance against file
distribution under Sequential Unicast.
While we observed significant performance benefits under
FastReplica in our experiments, these results are sensitive to a
system configuration and bandwidth of the paths between the nodes.
Since FastReplica in the small represents an induction
step of the general FastReplica algorithm, these performance
results set the basis for performance expectations of FastReplica
in the large.
times, where is the number of
nodes in the replication set. Additionally, FastReplica
demonstrates better or comparable performance against file
distribution under Sequential Unicast.
While we observed significant performance benefits under
FastReplica in our experiments, these results are sensitive to a
system configuration and bandwidth of the paths between the nodes.
Since FastReplica in the small represents an induction
step of the general FastReplica algorithm, these performance
results set the basis for performance expectations of FastReplica
in the large.
Next: 2 Additional Related Work
Up: FastReplica: Efficient Large File
Previous: FastReplica: Efficient Large File