


Next: 3.3 Preliminary Performance Analysis
Up: 3 FastReplica Algorithm
Previous: 3.1 Problem Statement
3.2 FastReplica in the Small
In this Section, we describe a core of FastReplica which is
directly applicable to a case when a set of recipient nodes
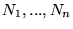 is small, e.g. in a range of 10-30 nodes.
File
is small, e.g. in a range of 10-30 nodes.
File 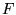 is divided in
is divided in 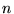 equal subsequent subfiles:
equal subsequent subfiles:
where
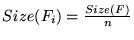 bytes for
each
bytes for
each 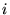 :
:
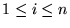 .
Step 1: Distribution Step.
The originator node
.
Step 1: Distribution Step.
The originator node 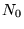 opens concurrent network connections to
nodes
, and sends to each recipient node
opens concurrent network connections to
nodes
, and sends to each recipient node 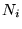 (
) the following items:
(
) the following items:
- a distribution list of nodes
 to which
subfile
to which
subfile  has to be sent on the next step;
has to be sent on the next step;
- subfile .
The activities taking place on the first step of the FastReplica
algorithm are shown in Figure 1. We will denote this step as a
distribution step.
Figure 1:
FastReplica in the small: distribution step.
 |
Step 2: Collection Step.
After receiving file , node opens 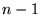 concurrent
network connections to remaining nodes in the group and send subfile to them as shown in Figure 2 for node
concurrent
network connections to remaining nodes in the group and send subfile to them as shown in Figure 2 for node 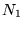 .
.
Figure 2:
FastReplica in the small: a set of outgoing connections
of node at collection step.
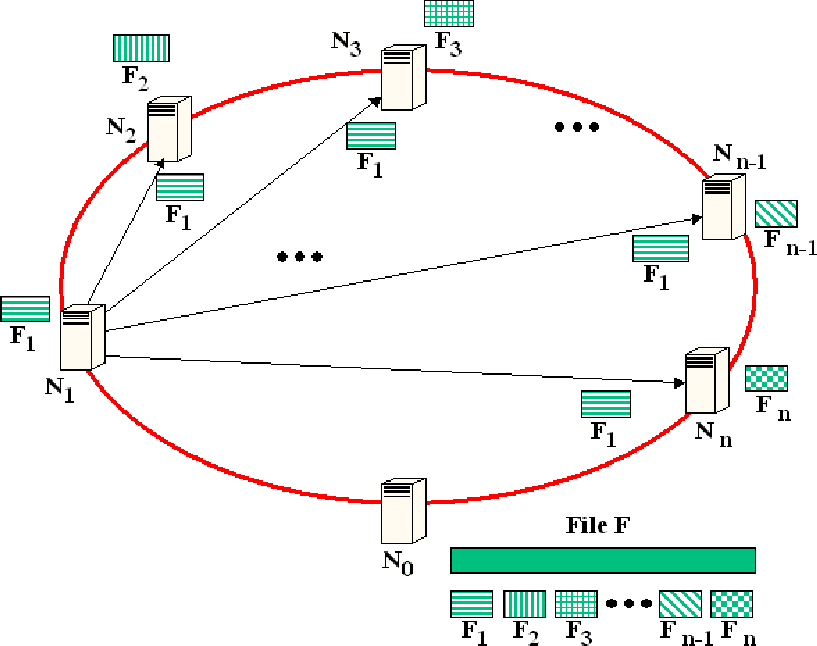 |
Figure 3:
FastReplica in the small: a set of incoming connections
of node at collection step.
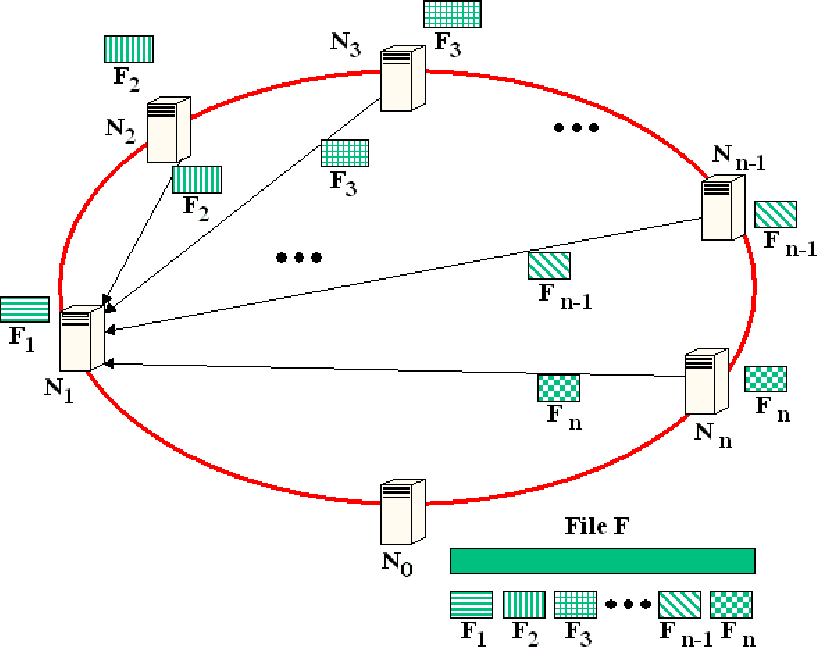 |
Similarly, Figure 3 shows the set of incoming
concurrent connections to node from the remaining nodes
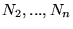 transferring the complementary subfiles
transferring the complementary subfiles
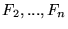 during the second logical step of the algorithm.
Thus at this step, each node has the following set of network
connections:
during the second logical step of the algorithm.
Thus at this step, each node has the following set of network
connections:
- there are outgoing connections from node : one
connection to each node
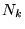 (
(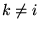 ) for sending the
corresponding subfile to node .
) for sending the
corresponding subfile to node .
- there are incoming connections to node : one
connection from each node () for sending
the corresponding subfile
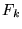 to node .
to node .
Thus at the end of this step, each node receives all subfiles
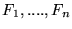 comprising the entire original file . We will denote
this step as a collection step.
In summary, the main idea behind FastReplica is that instead of
the typical replication of an entire file to nodes by using
Internet paths connecting the original node to the replication group,
the FastReplica algorithm exploits
comprising the entire original file . We will denote
this step as a collection step.
In summary, the main idea behind FastReplica is that instead of
the typical replication of an entire file to nodes by using
Internet paths connecting the original node to the replication group,
the FastReplica algorithm exploits 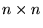 different
Internet paths within the replication group where each path is used
for transferring
different
Internet paths within the replication group where each path is used
for transferring 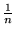 -th of the file. Thus, the
impact of congestion on any particular Internet path participating in
the schema is limited for a transfer of -th of
the file.
Additionally, FastReplica takes advantage of the upload and
download bandwidth of the recipient nodes.
-th of the file. Thus, the
impact of congestion on any particular Internet path participating in
the schema is limited for a transfer of -th of
the file.
Additionally, FastReplica takes advantage of the upload and
download bandwidth of the recipient nodes.
Next: 3.3 Preliminary Performance Analysis
Up: 3 FastReplica Algorithm
Previous: 3.1 Problem Statement