


Next: 3 FastReplica Algorithm
Up: FastReplica: Efficient Large File
Previous: 1 Introduction
2 Additional Related Work
The recent work on content distribution can be largely divided into
three categories: (a) infrastructure based content distribution, (b)
overlay network based distribution [7,9,12,13,17,10,6,14], and (c) peer-to-peer content
distribution [11,16,1,24].
Our work is directly related to the infrastructure based content
distribution network (CDN) (e.g. Akamai), which employs a dedicated
set of machines to reliably and efficiently distribute content to
clients on behalf of the server. While the entire collection of nodes
in a CDN setting may be varying, we assume that the set of
currently active nodes is known. The sites supported by multiple
mirror servers are referred to the same category. Existing research
on CDNs and server replication has primarily focused on either
techniques for efficient redirection of user requests to appropriate
servers or content/server placement strategies for reducing the
latency of end-users.
A more recent idea is to access multiple servers in parallel to reduce
downloading time or to achieve fault tolerance. Several research
papers in this direction exploited the benefits of path
diversity between the clients and the site's servers with
replicated content. Authors in [20], demonstrate the improved
response time observed by the client for a large file download through
the dynamic parallel access schema to replicated content at mirror
servers. Digital Fountain [4] applies Tornado codes to
achieve a reliable data download. Their subsequent work [5]
reduces the download times by having a client receive a Tornado
encoded file from multiple mirror servers. The target application of
their approach is bulk data transfer.
While CDNs were originally intended for static web content, they have
been applied for delivery of streaming media as well. Delivering
streaming media over the Internet is challenging due to a number of
factors such as high bit rates, delay and loss sensitivity. Most of
the current work in this direction concentrates on how to improve the
media delivery from the edge servers (or mirror servers) to the end
clients.
In order to improve streaming media quality,
the latest work in this direction [3,15] proposes streaming
video from multiple edge servers (or mirror sites), and in particular,
by combining the benefits of multiple description coding
(MDC) [2] with Internet path diversity. MDC codes a media
stream into multiple complementary descriptions. These descriptions
have the property that if either description is received it can be
used to decode the baseline quality video, and multiple descriptions
can be used to decode improved quality video.
One of the basic assumptions in the research papers referred to above
is that the original content is already replicated across the edge
(mirror) servers. The goal of our paper is to address the content
distribution within this infrastructure (and not to the clients of
this infrastructure). In this work, we propose a method to
efficiently replicate the content (represented by large files) from a
single source to a large number of servers in a scalable and reliable
way. We exploit ideas of partitioning the original file and using
diverse Internet paths between the recipient nodes to speedup the
distribution of an original large file over Internet.
In the paper, we partition the original file in 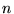 equal subsequent
subfiles and apply FastReplica to replicate them. This part of
the algorithm can be modified accordingly to the nature of the file. For
example, for a media file encoded with MDC, different descriptions can
be treated as subfiles, and FastReplica can be applied to
replicate them. Taking into account the nature of MDC (i.e. that
either description received by the recipient node can be used to
decode the baseline quality video), the part of the FastReplica
algorithm dealing with nodes failure can be simplified.
equal subsequent
subfiles and apply FastReplica to replicate them. This part of
the algorithm can be modified accordingly to the nature of the file. For
example, for a media file encoded with MDC, different descriptions can
be treated as subfiles, and FastReplica can be applied to
replicate them. Taking into account the nature of MDC (i.e. that
either description received by the recipient node can be used to
decode the baseline quality video), the part of the FastReplica
algorithm dealing with nodes failure can be simplified.
Next: 3 FastReplica Algorithm
Up: FastReplica: Efficient Large File
Previous: 1 Introduction