Despite the use of splicing or handoff, a single front-end node limits the scalability of clusters that employ content-based request distribution. This section presents experimental results that quantify the scalability limits imposed by a conventional, single front-end node.
To measure the scalability of the splicing and TCP handoff mechanisms, we conducted experiments with the configurations depicted in Figure 1. Our testbed consists of a number of client machines, connected to a cluster server. The cluster nodes are 300MHz Intel Pentium II based PCs with 128MB of memory. All machines are configured with the FreeBSD-2.2.6 operating system.
The requests were generated by a HTTP client program designed for Web server benchmarking [8]. The program generates HTTP requests as fast as the Web server can handle them. Seven 166 MHz Pentium Pro machines configured with 64MB of memory were used as client machines. The client machines and all cluster nodes are connected via switched 100Mbps Ethernet. The Apache-1.3.3 [3] Web server was used at the server nodes.
For experiments with TCP handoff, a loadable kernel module was added to the OS of the front-end and back-end nodes that implements the TCP handoff protocol. The implementation of the TCP handoff protocol is described in our past work [6,26]. For splicing, a loadable module was added to the front-end node. Persistent connections were established between the front-end node and the back-end webservers for use by the splicing front-end.
In the first experiment, the clients repeatedly request the same Web page of a given size. Under this artificial workload, the LARD policy behaves like WRR: it distributes the incoming requests among all back-end nodes in order to balance the load.
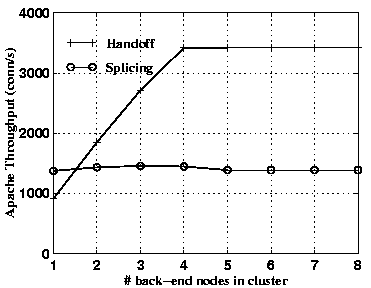
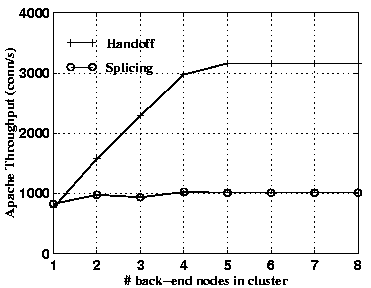
Figures 2 and 3 compare the cluster throughput with the handoff versus the splicing mechanism as a function of the number of back-end nodes in the cluster, and for requested Web page sizes of 6 KB and 13 KB, respectively. These two page sizes correspond to the extrema of the range of average HTTP transfer sizes reported in the literature [24,4]. Since the requested page remains cached in the servers' main memory with this synthetic workload, the server displays very high throughput, thus fully exposing scalability limitations in the front-end request distribution mechanism.
The results show that the TCP handoff mechanism scales to four back-end nodes, while splicing is already operating at front-end capacity with only one server node. In either case, the scalability is limited because the front-end CPU reaches saturation.
For the 6 KB files, the performance of splicing exceeds that of handoff at a cluster size of one node. The reason is that splicing uses persistent connections to communicate with the back-end servers, thus shifting the per-request connection establishment overhead to the front-end, which results in a performance advantage in this case. For larger cluster sizes and large files size, this effect is more than compensated by the greater efficiency of handoff, and by the fact that splicing saturates the front-end.
Additionally, it should be noted that with the larger page size (13 KB), the throughput with splicing degrades more than that with handoff (27% versus 7%, respectively). This is intuitive because with splicing, the higher volume of response data has to pass through the front-end, while with handoff, the front-end only incurs the additional cost of forwarding more TCP acknowledgments from the client to the back-ends.
In general, the maximal throughput achieved by the cluster with a single front-end node is fixed for any given workload. For example, the throughput with the handoff mechanism is determined by (a) the rate at which connections can be established and handed off to back-end nodes and (b) the rate at which TCP acknowledgments can be forwarded to back-end nodes. With slow back-end webservers and/or with workloads that cause high per-request overhead (e.g., frequent disk accesses) at the back-end nodes, the maximum throughput afforded by a back-end is lower and the front-end is able to support more back-end nodes before becoming a bottleneck. With efficient back-end webservers and/or workloads with low per-request overheads, a smaller number of back-ends can be supported.
The results shown above were obtained with a synthetic workload designed to expose the limits of scalability. Our next experiment uses a realistic, trace-based workload and explores the scalability of handoff and splicing under real workload conditions.
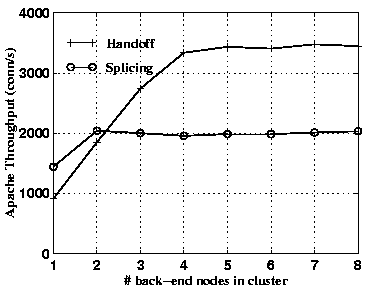
Figure 4 shows the achieved throughput using handoff versus splicing on a trace based workload derived from www.ibm.com's server logs (details about this trace are given in Section 6). As in the previous experiments, the handoff scales linearly to a cluster size of four nodes. The splicing mechanism scales to two back-end nodes on this workload. Thus, splicing scales better on this workload than on the previous, synthetic workload. The reason is that the IBM trace has an average page size of less than 3 KB2. Since splicing overhead is more sensitive to the average page size for the reasons cited above, it benefits from the low page size more than handoff.
The main result is that both splicing and handoff only scale to a small number of back-end nodes on realistic workloads. Despite the higher performance afforded by TCP handoff, its peak throughput is limited to about 3500 conn/s on the IBM trace and it does not scale well beyond four cluster nodes. In Section 6 we show that a software based layer-4 switch implemented using the same hardware can afford a throughput of up to 20,000 conn/s. Therefore, the additional overhead imposed by content-aware request distribution reduces the scalability of the system by an order of magnitude.
The limited scalability of content-aware request distribution cannot be easily overcome through the use of multiple front-end nodes. Firstly, employing multiple front-end nodes introduces a secondary load balancing problem among the front-end nodes. Mechanisms like round-robin DNS are known to result in poor load balance. Secondly, many content-aware request distribution strategies (for instance, LARD) require centralized control and cannot easily be distributed over multiple front-end nodes.
In Section 4 we describe the design of a scalable content-aware request distribution mechanism that maintains centralized control. Results in Section 6 indicate that this cluster is capable of achieving an order of magnitude higher performance than existing approaches.