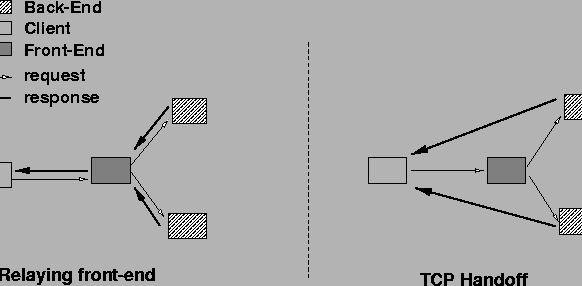
A simple client-transparent mechanism for supporting content-aware request distribution is a relaying front-end depicted in Figure 1. An HTTP proxy running on the front-end accepts client connections, and maintains persistent connections with all the back-end nodes. When a request arrives on a client connection, the connection is assigned according to a request distribution strategy (e.g., LARD), and the proxy forwards the client's request message on the appropriate back-end connection. When the response arrives from the back-end node, the front-end proxy forwards the data on the client connection, buffering the data if necessary. The principal advantage of this approach is its simplicity and the ability to be deployed without requiring any modification of the operating system kernel on any cluster node. The primary disadvantage, however, is the overhead incurred in forwarding all the response data from the back-ends to the clients, via the proxy application.
TCP splicing [15,12] is an optimization of the front-end relaying approach where the data forwarding at the front-end is done directly in the operating system kernel. This eliminates the expensive copying and context switching operations that result from the use of a user-level application. While TCP splicing has lower overhead than front-end relaying, the approach still incurs high overhead because all HTTP response data must be forwarded via the front-end node. TCP splicing requires modifications to the OS kernel of the front-end node.
The TCP handoff [26] mechanism was introduced to enable the forwarding of back-end responses directly to the clients without passing through the front-end as an intermediary. This is achieved by handing off the TCP connection established with the client at the front-end to the back-end where the request was assigned. TCP handoff effectively serializes the state of the existing client TCP connection at the front-end, and instantiates a TCP connection with that given starting state at the chosen back-end node. The mechanism remains transparent to the clients in that the data sent by the back-ends appears to be coming from the front-end and any TCP acknowledgments sent by the client to the front-end are forwarded to the appropriate back-end. TCP handoff requires modifications to both the front-end and back-end nodes, typically via a loadable kernel module that plugs into a general-purpose UNIX system.
While TCP handoff affords substantially higher scalability than TCP splicing by virtue of eliminating the forwarding overhead of response data, our experiments with a variety of trace-based workloads indicate that its scalability is in practice still limited to cluster sizes of up to ten nodes. The reason is that the front-end must establish a TCP connection with each client, parse the HTTP request header, make a strategy decision to assign the connection, and then serialize and handoff the connection to a back-end node. The overhead of these operations is substantial enough to cause a bottleneck with more than approximately ten back-end nodes on typical Web workloads.