This section addresses the scalability problem with content-aware request distribution. We identify the bottlenecks and propose a configuration that is significantly more scalable.
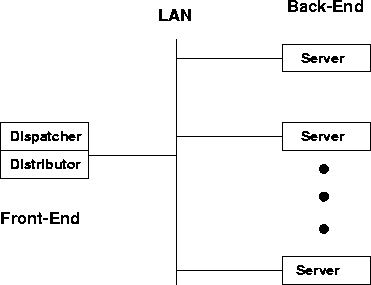
Figure 5 shows the main components comprising a cluster configuration with content-aware request distribution and a single front-end. The dispatcher is the component that implements the request distribution strategy; its task is to decide which server node should handle a given request. The distributor component interfaces with the client and implements the mechanism that distributes the client requests to back-end nodes; it implements either a form of TCP handoff or the splicing mechanism. The server component represents the server running at the back-end and is responsible for processing HTTP client requests.
A key insight is that (1) the bulk of the overhead at the front-end node is incurred by the distributor component, not the dispatcher; and, (2) the distributor component can be readily distributed since its individual tasks are completely independent, while it is the dispatcher component that typically requires centralized control. It is intuitive then, that a more scalable request distribution can be achieved by distributing the distributor component over multiple cluster nodes, while leaving the dispatcher centralized on a dedicated node.
Experimental results show that for TCP handoff, the processing
overhead for handling a typical connection is nearly 300 ![]() sec for
the distributor while it is only 0.8
sec for
the distributor while it is only 0.8 ![]() sec for the dispatcher. With
splicing, the overhead due to the distributor is larger than 750
sec for the dispatcher. With
splicing, the overhead due to the distributor is larger than 750
![]() sec and increases with the average response size. One
would expect then, that distributing the distributor component while
leaving only the dispatcher centralized should increase the
scalability of the request distribution by an order of magnitude. Our
results presented in Section 6 confirm this reasoning.
sec and increases with the average response size. One
would expect then, that distributing the distributor component while
leaving only the dispatcher centralized should increase the
scalability of the request distribution by an order of magnitude. Our
results presented in Section 6 confirm this reasoning.
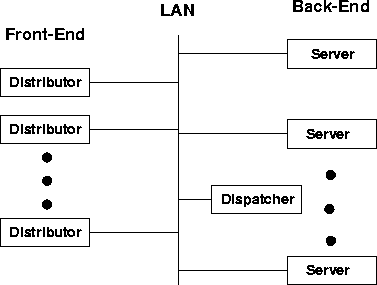
Figure 6 shows a cluster configuration where the distributor component is distributed across several front-end nodes while the dispatcher resides on a dedicated node. In such a configuration with multiple front-end nodes, a choice must be made as to which front-end should receive a given client request. This choice can be made either explicitly by the user with strategies like mirroring3, or in a client transparent manner using DNS round-robin. However, these approaches are known to lead to poor load balancing [20], in this case among the front-end nodes.
Another drawback of the cluster configuration shown in Figure 6 is that efficient partitioning of cluster nodes into either front-end or back-end nodes depends upon the workload and is not known a priori. For example, for workloads that generate significant load on the back-end nodes (e.g, queries for online databases), efficient cluster utilization can be achieved by using a few front-end nodes and a large number of back-end nodes. For other workloads, it might be necessary to have a larger number of front-end nodes. A suboptimal partitioning, relative to the prevailing workload, might result in low cluster utilization, i.e, either the front-end nodes become a bottleneck when the back-end nodes are idle or vice versa.
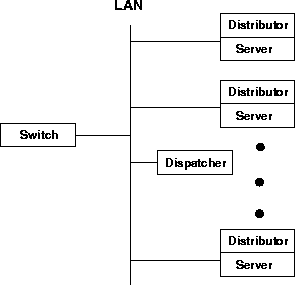
Figure 7 shows an alternate cluster design where the distributor components are co-located with the server components. As each cluster node hosts both the distributor and the server components, the cluster can be efficiently utilized irrespective of the workload. As in the cluster of Figure 6, the replication of the distributor component on multiple cluster nodes eliminates the bottleneck imposed by a centralized distributor. In addition, a front-end consisting of a commodity layer-4 switch is employed that distributes incoming client requests to one of the distributor components running on the back-end nodes, in such a way that the load among the distributors is balanced.
Notice that the switch employed in this configuration does not perform content-aware request distribution. It merely forwards incoming packets based on layer-4 information (packet type, port number, etc.). Therefore, a highly scalable, hardware based commercial Web switch product can be used for this purpose [21,11]. In Section 6, we present experimental results with a software based layer-4 switch that we developed for our prototype cluster.
A potential remaining bottleneck with this design is the centralized dispatcher. However, experimental results presented in Section 6 show that a centralized dispatcher implementing the LARD policy can service up to 50,000 conn/s on a 300MHz Pentium II machine. This is an order of magnitude larger than the performance of clusters with a single front-end, as shown in Section 3.
In the next section, we provide a detailed description of our prototype implementation. In Section 6 we present experimental results that demonstrate the performance of our prototype.