


Next: Role Correlation
Up: Role Classification
Previous: Forming Groups
Merging Groups
The aforementioned group formation algorithm that uses a simple definition of
similarity tends to produce too many groups in many situations.
Consider, for example, the network in Figure 1
modified so that Sales-1 communicates with the Mail and
SalesDatabase servers but not the Web server. The grouping
algorithm in Section 4 will create two groups for the sales
hosts, one that only contains Sales-1 and one that contains the
rest of the sales hosts. This might be appropriate, but it is
probably not what a network administrator would want.
The group merging phase builds on the results generated by the group
formation phase. It merges groups that are similar in connection
habits in a way that allows users to control the process so that more
meaningful results can be achieved.
During the grouping phase, we merge two groups if
they meet the following two requirements:
- Similarity requirement.
- The similarity measure between
the two groups exceeds a user-specified threshold.
- Connection requirement.
- The average number of
connections of each group is comparable.
The algorithm repeatedly merges two groups that meet the two
requirements and have the highest similarity measure until no groups
can be merged. The K value of a newly merged group is set to the
minimum number of connections a host in the group has.
Figure 3:
Pseudo-code for determining the similarity and connection
requirements.
|
|
Figure 3 depicts the pseudo-code for determining the
average connection requirement and the similarity requirement. The
procedure MEETCONNECTIONREQ decides whether the two groups,
G1 and G2, meet the connection requirement. This requirement keeps
a group with a large number of connections from merging with another
group with a much smaller number of connections.
The procedure MEETSIMILARITYREQ determines whether the two
groups meet the similarity requirement. Shi and Slo,
Shi > Slo, are similarity thresholds that can be set by the
user to control the merging process. Which threshold is used depends
upon whether
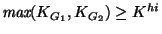 , where
Khi is a constant intended to define whether a KG value is
``high.'' The similarity threshold for merging groups is higher for
groups with a high KG value, those groups whose member hosts share
a high number of common neighbors. This is because merging
two groups can change the relationships between other groups in a way
that induces additional undesirable merges.
Again, consider the groups in the example network illustrated in
Figure 1. Notice that if N is large, the similarity
measure between the SalesDatabase group and the Mail and
Web group will be large. Similarly, for large M, the
SourceRevisionControl group will be highly similar to the Mail
and Web group. If all three groups were to merge, it would
effectively cause the sales group and the engineering group to merge,
resulting in a partitioning with two groups: one containing all the
servers, and one containing all other hosts. In most situations, this
grouping would be undesirable since the network administrators lose the
important separation between the Sales machines and the Eng
machines. For these reasons, groups with high KG values are required
to have a higher similarity measure to merge. We discuss how best to
choose the constants in Section 6.
SIMILARITY computes the similarity s (between 0 and 100) of
connection patterns between two groups. CP(x1, x2) returns the
total number of connections between x1 and x2, where xi could
either be a host or a group. Two groups are considered similar if they
have many common neighboring groups and similar average numbers of
connections. For example, if the set of neighbors of G1 is a
subset of the set of neighbors of G2, it increases the desirability
of merging these two groups. However, if the average numbers of
connections of G1 and G2 are quite different, the desirability
of merging them is lessened.
, where
Khi is a constant intended to define whether a KG value is
``high.'' The similarity threshold for merging groups is higher for
groups with a high KG value, those groups whose member hosts share
a high number of common neighbors. This is because merging
two groups can change the relationships between other groups in a way
that induces additional undesirable merges.
Again, consider the groups in the example network illustrated in
Figure 1. Notice that if N is large, the similarity
measure between the SalesDatabase group and the Mail and
Web group will be large. Similarly, for large M, the
SourceRevisionControl group will be highly similar to the Mail
and Web group. If all three groups were to merge, it would
effectively cause the sales group and the engineering group to merge,
resulting in a partitioning with two groups: one containing all the
servers, and one containing all other hosts. In most situations, this
grouping would be undesirable since the network administrators lose the
important separation between the Sales machines and the Eng
machines. For these reasons, groups with high KG values are required
to have a higher similarity measure to merge. We discuss how best to
choose the constants in Section 6.
SIMILARITY computes the similarity s (between 0 and 100) of
connection patterns between two groups. CP(x1, x2) returns the
total number of connections between x1 and x2, where xi could
either be a host or a group. Two groups are considered similar if they
have many common neighboring groups and similar average numbers of
connections. For example, if the set of neighbors of G1 is a
subset of the set of neighbors of G2, it increases the desirability
of merging these two groups. However, if the average numbers of
connections of G1 and G2 are quite different, the desirability
of merging them is lessened.
Next: Role Correlation
Up: Role Classification
Previous: Forming Groups
Godfrey Tan
2003-04-01
