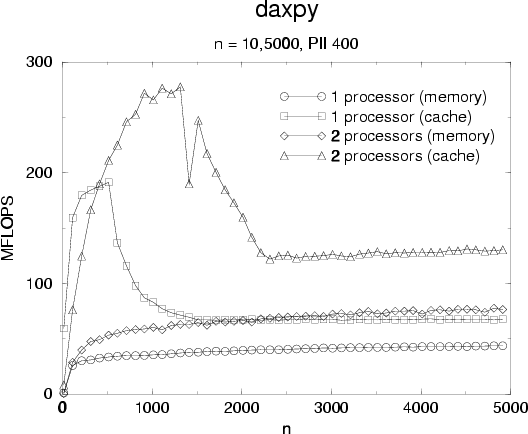
Performances results for daxpy are presented figure ![[*]](cross_ref_motif.png) and
acceleration is showed . Observed results are typical for
level 1 operations: we observe a peak when data fits into L1 cache and a
smooth decrease when data does not fits in L1 but remains in L2. Performance
from main memory is driven by memory bandwidth. Acceleration is quite good for
large vectors especially when datas are in cache.
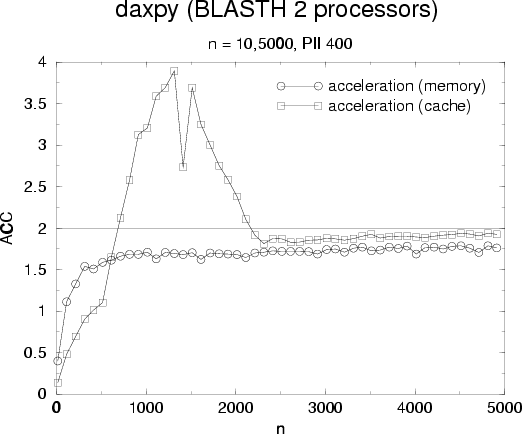
and
acceleration is showed . Observed results are typical for
level 1 operations: we observe a peak when data fits into L1 cache and a
smooth decrease when data does not fits in L1 but remains in L2. Performance
from main memory is driven by memory bandwidth. Acceleration is quite good for
large vectors especially when datas are in cache.
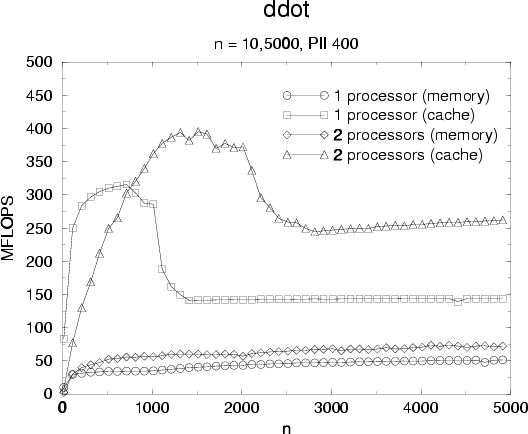
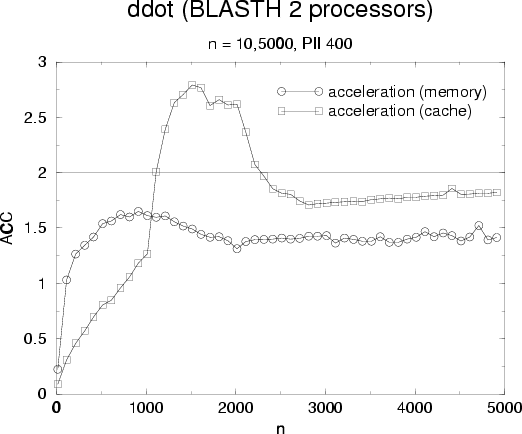
Performance results for ddot are showed figure and
figure for acceleration. Comments on performances results are the
same as for daxpy but we observed that scaling is not as good as for daxpy:
cache operation scaling is roughly 1.8 but remains good.
On the other side memory operation scaling in poor (![]() ). To understand
that we make some memory bandwidth measurements with very large vectors to
not consider time spent in synchronization and the results are presented in
table : we see that single processor ddot use more than half of
the theoretical peak memory bandwidth (the system uses pc100 SDRAM allowing
800e6 B/s
memory bandwidth) and dual processor uses up to 75% of available bandwidth
which seems very good for the test system.
). To understand
that we make some memory bandwidth measurements with very large vectors to
not consider time spent in synchronization and the results are presented in
table : we see that single processor ddot use more than half of
the theoretical peak memory bandwidth (the system uses pc100 SDRAM allowing
800e6 B/s
memory bandwidth) and dual processor uses up to 75% of available bandwidth
which seems very good for the test system.
|
The daxpy and ddot BLAS show good acceleration with the blasth library when
datas are present into cache memory, this behavior is in fact common to all
level 1 operations since each component of vectors is used only one time in
computation (no temporal locality). Operations on small vectors (![]() )
will not scale due synchronization cost compared to the small number of
floating point operations issued (n or 2.n for level 1 BLAS). The memory
bandwidth is the key point for scalability when datas are out of cache which is
always true for very large data sets.
)
will not scale due synchronization cost compared to the small number of
floating point operations issued (n or 2.n for level 1 BLAS). The memory
bandwidth is the key point for scalability when datas are out of cache which is
always true for very large data sets.