Chen et al. [7] proposed a single-writer, multiple-reader wait-free algorithm using the Compare-And-Swap (CAS) instruction. This instruction is used to atomically modify the states of control variables used to ensure that the writer never writes to a buffer currently in use by some readers. The CAS instruction is commonly used in non-blocking algorithms to coordinate accesses to shared buffers and is supported on most modern microprocessors. Even if an architecture does not support this instruction, it can be synthesized by using other system primitives or system support [5]. The instruction CAS(A,B,C) is defined to be equivalent to atomically executing ``if A equals B, then set A to C and return true, else return false.''
Chen's algorithm requires (P + 2) message buffers, where P is the number of reader tasks. There is a global variable, Latest, that indexes to the most recently written message buffer. Additionally, each reader has an entry in a usage array indicating the buffer it is using. When the reader reads, it first clears its entry, and then uses CAS to atomically set this to Latest if it is still cleared. It then reads back the value from its entry, and can then safely read from the indicated buffer. The writer has slightly more work to do. It first scans the usage array and selects a free buffer. It performs the write, updates Latest, and then must scan and set each reader entry that is cleared to Latest using CAS. This has been proven to ensure correct non-blocking IPC behavior in [7].
By taking into account the real-time properties of the communicating tasks,
we can divide the reader set into two sets: fast and slow reader sets. By
separating the reader set, we can reduce the space requirement from P + 2
to M + max(2, N), where M is the number of slow readers and N
is the number of buffers needed by the fast readers.
Section 3.4 describes how to compute M and N in
order to optimize for space. Because N is chosen to be less than, or
equal to, the number of fast readers (i.e., ![]() ), the improved
algorithm requires no more buffer space than the original algorithm. In
the worst case (i.e., all readers are slow readers), the improved algorithm
simply degenerates to the original algorithm. Furthermore, the execution
time overheads will be greatly reduced, since fast readers use the very
efficient NBW mechanism and the writer overhead is linear to the number of
slow readers only, rather than all readers. Therefore, both space and time
overheads can be reduced.
), the improved
algorithm requires no more buffer space than the original algorithm. In
the worst case (i.e., all readers are slow readers), the improved algorithm
simply degenerates to the original algorithm. Furthermore, the execution
time overheads will be greatly reduced, since fast readers use the very
efficient NBW mechanism and the writer overhead is linear to the number of
slow readers only, rather than all readers. Therefore, both space and time
overheads can be reduced.
The Improved Chen's algorithm is shown in Figure 3. NSReader is the number of slow readers. NBuffer is the total number of message buffers. Buff[] is the array of message buffers shared between the writer and readers. Latest is a control variable that indexes this array, indicating the most recently written message buffer. Reading[] is the usage array associated with the slow readers such that Reading[i] indicates which buffer entry the ith slow reader is currently reading.
The slow readers operate identically to the readers in Chen's algorithm. Just before the ith slow reader reads from the message buffer, Reading[i] is set to a value between 0 and NBuffer-1 to indicate the index of the buffer it will be reading. The writer will not overwrite this buffer slot as long as the slow reader is still using it. The slow reader first assigns Reading[i]=NBuffer to indicate that it is preparing to make a read operation. Then, it reads Latest, and attempts to set Reading[i] to this value atomically using CAS. If the writer has preempted the reader and completed a buffer write before this instruction, it would have already set Reading[i] to the new Latest value, and the reader's CAS would fail. In any case, by line 3, Reading[i] would have been atomically set to a buffer index that the writer will not use. So the slow reader simply reads the index and can now read from the indicated buffer safely.
The fast reader (not shown) is the same as in the NBW protocol. It relies only on temporal concurrency control, so it just reads Latest and uses the indicated buffer.
The Writer() process looks just like the one in Chen's algorithm. It calls GetBuff() to determine which buffer slot is safe to use next. After it writes the next message, it updates Latest and then modifies each Reading[i] using CAS if necessary.
The key difference lies in GetBuff() function, which is modified to
allow temporal concurrency control for fast readers. First, to prevent the
writer from interfering with slow readers, GetBuff() picks a buffer,
m, such that no slow reader is using it (i.e., for all i, Reading[i]![]() ). To protect the fast readers, as with the NBW
protocol, we must ensure that there are at least (N - 1) writes between
two consecutive writes to any particular buffer, where N is the buffer
depth required for temporal concurrency control (Section 2.2).
GetBuff() prevents the writer from interfering with the fast readers
by cyclically choosing buffer entries starting from Latest. When
NBuffer is chosen correctly (Section 3.4), even
if each slow reader is using a unique buffer, there will be enough buffers
(i.e., NBuffer - NSReader) left so that the cyclic selection will
ensure sufficient time between two consecutive writes to the same buffer,
satisfying the requirements for temporal concurrency control. Thus, the
writer will not interfere with either fast or slow readers.
). To protect the fast readers, as with the NBW
protocol, we must ensure that there are at least (N - 1) writes between
two consecutive writes to any particular buffer, where N is the buffer
depth required for temporal concurrency control (Section 2.2).
GetBuff() prevents the writer from interfering with the fast readers
by cyclically choosing buffer entries starting from Latest. When
NBuffer is chosen correctly (Section 3.4), even
if each slow reader is using a unique buffer, there will be enough buffers
(i.e., NBuffer - NSReader) left so that the cyclic selection will
ensure sufficient time between two consecutive writes to the same buffer,
satisfying the requirements for temporal concurrency control. Thus, the
writer will not interfere with either fast or slow readers.
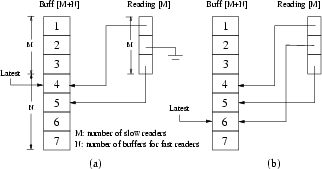
Let us illustrate this using the example shown in Figure 4. Assume that there are 20 readers, of which 3 are identified as slow readers. Assume further that relative execution frequencies of the fast readers and the writer are such that they require a 4-deep buffer to ensure temporal concurrency control. In this system, therefore, we need 7 message buffers (4 for the fast readers, and 1 for each of the slow readers), as compared to 22 buffers needed with the original Chen's algorithm. Figure 4(a) shows a particular execution state of the task set with Latest points to the 4th buffer slot. Since Reading[0] and Reading[2] point to the 4th and 5th buffer slots, the writer knows these may be in use, and will not use these buffers. Instead, it will cyclically select and write to the next available slot after Latest, the 6th buffer. The worst-case scenario occurs when the last slow reader now makes a read operation. It will now prevent the writer from using the 6th buffer. Even if the three slow readers never relinquish their buffers, the writer can continue to write cyclically to the remaining 4 buffers, with the repeating access pattern {7, 1, 2, 3, 7, ...}. This ensures that no buffer is used more frequently than every fourth write, satisfying the conditions for the fast readers.
The biggest drawback of Chen's algorithm lies in the complexity of the GetBuff() function and the expensive CAS instruction itself. As shown in Figure 3, there are three loops inside of this function. The first one loops NBuffer times, and the second one loops NSReader times. Finally, the last one can potentially loop NBuffer times again. Furthermore, the writer has a loop that executes CAS NSReader times. As the number of slow readers decreases, we expect the performance enhancement from the Improved Chen's algorithm, as compared to the original Chen's algorithm.