



Next: The Key Expansion
Up: The public-key coprocessor based
Previous: The MixColumn transformation
The inverse
MixColumn transformation requires also a matrix multiplication in the field
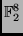 .
In an 8-bit CPU, this can be implemented in an efficient way for each column as follows:
.
In an 8-bit CPU, this can be implemented in an efficient way for each column as follows:
After reordering the equations we get:
As for the
MixColumn, the inverse transformation (needed for decryption) can also be defined to operate on the
16 bytes of the state in parallel.
The implementation is based on the previous definition of the
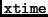 operation:
operation:
 |
 |
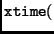 state state |
|
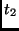 |
|
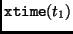 |
|
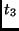 |
|
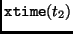 |
|
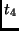 |
|
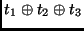 |
|
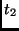 |
|
state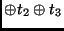 |
|
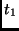 |
|
state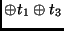 |
|
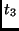 |
|
state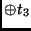 |
|
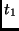 |
|
RotWord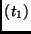 |
|
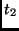 |
|
RotWord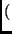 RotWord RotWord |
|
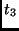 |
|
RotWordRotWordRotWord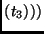 |
|
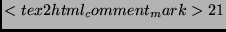 state state |
|
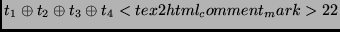 |
|
The total number of registers needed for the implementation of the inverse transformation in the coprocessor is 5,
where 4 temporal registers are used for intermediate results and one other register for the state itself.
Another way to implement the inverse
MixColumn transformation is by definition of the following two new operations:
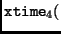 state state |
|
 state state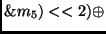 |
|
| |
|
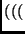 state state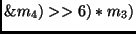 |
|
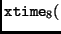 state state |
|
state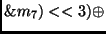 |
|
| |
|
state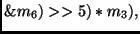 |
|
where
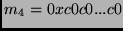 (16 bytes),
(16 bytes),
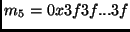 (16 bytes),
(16 bytes),
 (16 bytes),
(16 bytes),
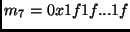 (16 bytes) and
(16 bytes) and
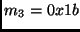 .
Therefore, the implementation of the inverse
MixColumn transformation can be redefined as follows:
.
Therefore, the implementation of the inverse
MixColumn transformation can be redefined as follows:
|
|
state |
|
 |
|
state |
|
 |
|
state |
|
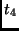 |
|
|
|
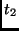 |
|
state |
|
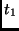 |
|
state |
|
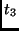 |
|
state |
|
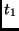 |
|
RotWord |
|
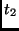 |
|
RotWordRotWord |
|
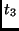 |
|
RotWordRotWordRotWord |
|
 |
|
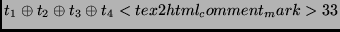 |
|
The advantage of this second implementation is that the operations
,
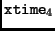 and
and
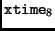 can be calculated in parallel from the state, avoiding the sequence of the first implementation. M
oreover, in the case that the AND operation is not available within the coprocessor,
this second solution allows to precompute all the AND values within the standard CPU
before loading the state into the coprocessor.
can be calculated in parallel from the state, avoiding the sequence of the first implementation. M
oreover, in the case that the AND operation is not available within the coprocessor,
this second solution allows to precompute all the AND values within the standard CPU
before loading the state into the coprocessor.
Next: The Key Expansion
Up: The public-key coprocessor based
Previous: The MixColumn transformation
Roger Fischlin
2002-09-25