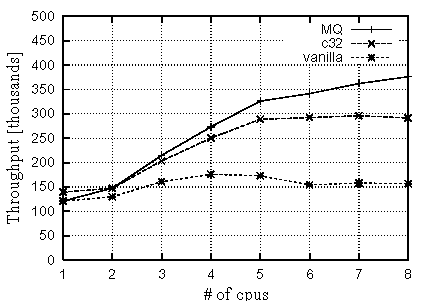
Figure 10 shows the throughput performance on the standard kernel (vanilla), 32 coloring kernel (c32), and multi-queue scheduler kernel (MQ).
As expected, c32 shows significantly better throughput than vanilla. Vanilla kernel slightly scales up to 4 CPUs, but its throughput performance starts dropping from 5 CPUs upward. On the contrary, c32 scales up to 6 CPUs which provides 89.6% throughput improvement compared to vanilla. MQ gains the best throughput among these three kernels.
As similar in WebBench, we collected information for L2 cache miss ratio and lock statistics. The results are shown in Table 7 and 8, respectively. We can see that there is a substantial reduction in L2 cache miss ratio on any number of CPUs, leading to speedup of the run queue traversal. This result shows that the lock hold time is reduced from 40us to 14us on the 8 CPUs system by the coloring scheme. The lock contention is also decreased from 85.8% on vanilla to 69.7% on c32. The run queue lock contention of Chat micro benchmark is higher than that of WebBench.