




This section describes preliminary experiments that were undertaken to reduce the number of unsupported assumptions and design decisions, and to test the extent to which pessimistic conclusions of certain earlier studies [4, 19] apply to this study.
Unfortunately, the data needed for the experiments described in this section is not present in well known existing logs such those from DEC [8], Boston University, Berkeley [15], and AT&T. Accordingly, we had to gather our own logs. A separate trace was gathered at AT&T Labs over several months in 1999. A ``snooping'' proxy produced, for every GET request, the following information: requesting client; URL; IMS request or not; Referer field, if present; time request was received by snooper; time first response byte was received; time last response byte was received; status code; Content-type field; lengths of header and content; time to expiration, and how computed; the number of embedded URLs; and whether the response would be cached and, if not, why not. In addition, all pages were permanently logged, including in cases where an unaltered proxy would not have cached it. It was necessary to log content because some experiments described in this section need it. For example, Experiment E determines, among other things, whether the URL of a referenced page is embedded as a hyperlink in any page accessed within the previous 30 seconds.
The trace consists of 92,518 references generated by members of the author's department (6 clients) over a span of about 5 months. All clients were attached to the same high speed LAN at 10Mb/sec. The LAN is attached to the Internet via a partial DS3. Drawing traces from a high speed environment is desirable because inter-reference times are likely to reflect the user's actual think time rather than bandwidth limitations of the local environment.
Experiments A and B, respectively, address the assumptions in [19] that ``prefetching can only begin after the client's first contact with that server'' and that ``query events and events with cgi-bin in their URL cannot be either prefetched or cached.'' Neither prohibition applies to this work. How significant are the effects of lifting these prohibitions?
Experiment A. The experimental question is: in those cases where one page refers to another, what fraction of referenced links (and bytes) are from sites different from the site of the referring page?
Analysis was done by parsing site information from the URLs. Sites are deemed to be different if both their names and IP addresses differ at the moment that the log analysis program runs. In some cases, months elapsed between the gathering of log data and the last run of the analysis program. It is assumed that during that time very few host pairs flip-flop between being same and different.
The results are that 28.9% of referenced hyperlinks, representing 19.9% of bytes, are to URLs on other servers. This seems high, and might reflect references skewed to commercial sites packed with advertisements on other sites.
Prefetch-ability in this work is not the same as cache-ability in the
literature. The reason is that the prefetcher brings pages into a
client-specific cache. Because the cache is not shared, it is
possible to cache cookies, query URLs and dynamic content. Studies of
techniques for shared caches exclude such pages, with considerable
effect. For example, one study [14] found that, in
one sample, 43.1% of documents were uncacheable, mostly because of
cookies (30.2%), query URLs (9.9%), obvious dynamic content
(5.4%), and explicit cache-control prohibitions (9.1%).
Experiment B. The experimental question is: what fraction of referenced links (and bytes) are query URLs or ``obvious'' dynamic content?
The definition of ``obvious dynamic content'' is derived from the one most often seen in the literature: a URL is assumed to specify dynamic content if it contains cgi. This heuristic is outmoded, as there are ever more tools for producing dynamic content, and these tools produce URLs by a variety of conventions, not just cgi-bin. The effect of using an old heuristic is that the proportion of dynamic content is underestimated, meaning that we err on the conservative side.
The results are that 16.3% of referenced hyperlinks, representing 18.2% of bytes, are to query URLs or to URLs containing cgi.
The results of experiments A and B are not meant to challenge or invalidate conclusions such as those in [19], because the bounds in that paper were developed under conditions that are unrealistically favorable. These results are meant to show merely that the theoretical limit to latency improvement via prefetching is probably higher than 60%, for two reasons. First, [19] assumes a shared cache and therefore does not prefetch certain pages that can be prefetching into a private cache. Second, [19] excludes the possibility of prefetching from a ``new'' site.
Prefetching is not a purely algorithmic problem. Even given an oracle that could predict future accesses perfectly, prefetching results might be imperfect if a page were demanded during the time between the prediction of its need and its arrival. In such a case prefetching might still lower the observed latency, but conventionally such partial success is counted as a prefetching failure.
Experiment C1 determines the distribution of the time interval between referring and referred-to pages. Since Web data expires after a while, another timing issue is the distribution of expiration intervals. Because prefetched data can expire before it is demanded, prefetching too far in advance is also a problem. Experiment C2 determines the distribution of expiration times.
Experiment C1. The experimental question is: in those cases where one page refers to another, what is the distribution of the time between (1) the end of the transfer of the referer and (2) the beginning of the transfer of the referee? This is the amount of time available to the prefetcher.
 <\center>
<\center>
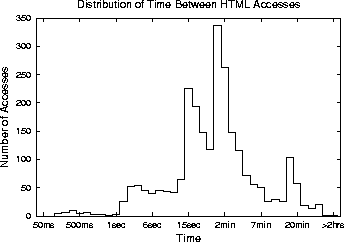
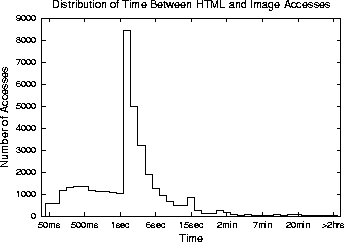
The results are broken down into two categories: HTML referencing HTML (Figure 1), and HTML content referencing image content (Figure 1). The breakdown is intended to capture the difference between references to embedded hyperlinks and images, respectively. As shown, the browser-generated references to embedded images happen much more quickly than user-generated references to hyperlinks. The median inter-reference time between two HTML pages is 52 seconds, while inter-reference time between an HTML page and an image page is 2.25 seconds. However, a significant fraction of images (32.3%) are requested within one second or less of the referencing HTML page. This suggests that when an HTML page is prefetched, its embedded images should be prefetched too. Doing so substantially increases the penalty for being wrong.
 <\center>
<\center>
 <\center>
<\center>
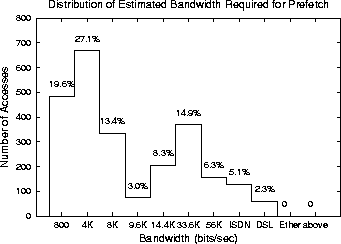
Figure 3 is the distribution of ``total page size'' divided by inter-reference time. That is, references in the log were analyzed to determine the size of an HTML page plus all its embedded images, whether or not they were actually referenced -- an overestimate of what is needed to completely prefetch a page. Then this number was divided by the time between when that page's referrer was loaded and when the page was requested. This quotient is the maximum amount of data a prefetcher would have to deliver divided by the amount of time available to it: the bandwidth needed to prefetch one page. The median bandwidth is around 5KB/sec, safely within the capacity of even a dialup modem, suggesting that several pages could be prefetched while remaining within bandwidth constraints.
Experiment C2. The experimental question is: what is the distribution of expiration times, and how are the times computed? Prefetching can be harmful if prefetched content expires before it is demanded.
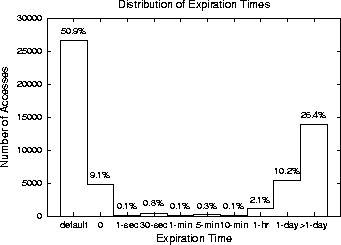
As Figure 4 shows, the most common expiration time is zero (60.0%). Typically (50.9%), zero is determined by default because the server has provided no information (Expires or Last-modified headers) upon which to base an estimate. The rest of the time (9.1%), the server has provided identical Expires and Date headers.
Strictly speaking, a zero expiration time should doom prefetching because prefetched content will be expired once it is demanded from the cache. However, since the meaning of a zero expiration time is ``use only once,'' in our implementation we take the following steps. First, as explained in Section 4.1, a special header (Prefetch: Prefetch) is present in prefetched pages. The cache freshness-check code has been altered to ignore an explicit zero expiration (i.e., Expires = Date) when such a page has the prefetch header. When a such a page is eventually read, the cached page is re-written with the current time in the expires field and the Prefetch: Prefetch header overwritten.
The median non-zero expiration time (more than one day) far exceeds the average inter-reference time (52 seconds), indicating that too-early prefetching is not a practical concern. The median expiration time is so large because in many cases expiration is based only upon Last-modified headers, and many pages have not been modified in months.
The naive approach to prefetching based on embedded links [5, 26, 24] is to prefetch all embedded links or some number of them, without regard to the likelihood of use. Experiment D determines that some pages can have a very large number of embedded links, representing many bytes. Experiment D. The experimental question is: what is the distribution of the number of links per page, how many bytes do these links represent, and what fraction of links/bytes are actually accessed?
As the snooper recorded the content of each page, it also parsed the pages and logged each embedded URL and its reference type (HREF, IMG SRC, etc.). The log analyzer determined which of these URLs were later accessed from that page. It also determined the size of each embedded HREF URL and its embedded images by calling a utility similar to the popular webget. Therefore, the sizes were determined, in some cases, weeks or months after the fact. It is assumed that size changes occurring the interim are negligible, or at least not substantially skewed in one direction or another.
The average number of links per page is 22.6. The average size of these links is 7760 bytes. The fraction of links and bytes accessed is very low (5.4% and 3.8%, respectively), again perhaps because of commercial portal sites that are packed with links. These results reinforce the importance of accurate prefetch predictions.
Some prior work (e.g., [2, 13, 25]) has used Markov modeling to make reference predictions. A Markov prediction algorithm makes no use of structure information such as the Referer field, but instead regards earlier references as an unstructured string drawn from the ``alphabet'' of page IDs and attempts to discover patterns in the string. Recurrence of the initial part of a detected pattern triggers prefetching of the remainder of the pattern string. Markov algorithms seek patterns within a ``window'' of prior references, where the window typically is measured by time or number of references.
The two advantages of the Markov approach are that it does not depend upon the Referer field (which may not always be present) and that it can discover non-intuitive patterns. However, there are significant disadvantages to Markov algorithms. One is that such algorithms often have a high cost, measured in storage and compute time. The reason is that a Markov algorithm typically represents pages as graph nodes and accesses as weighted graph edges. With no structure to guide the search for patterns, predictive ability is improved by enlarging the window: retaining as many nodes as possible and searching as many paths as possible. Second, naive implementations of Markov algorithms have trouble aging their data. We hypothesize that Markov algorithms suffer a third drawback of being too general -- they discover patterns that, to a large degree, are already obvious in the HTML of recently accessed pages and might be more simply extracted therefrom.
Experiment E compares the fraction of Markov ``dependencies'' among pages (that is, patterns where an access to page X tends to be closely followed by an access to page Y) that are also embedded links within recently referenced HTML pages.
Experiment E. The experimental question is: what fraction of ``dependent'' pages/bytes might also be easily detectable as embedded links? Two definitions of dependency are taken from much-cited works, [2] and [25]. Two references represent a dependency if they are made by the same client within a certain time or a certain number of prior references, respectively. As explained below, only a certain class of dependencies is considered. The results are shown in Figure 5.
| Time (sec) | 10 | 30 | 60 | 120 |
| Embedded | 70.0% | 74.6% | 76.0% | 77.2% |
| References | 1 | 3 | 5 | 10 |
| Embedded | 39.6% | 66.3% | 73.2% | 78.3% |
The experiment computed, for every URL accessed, whether that URL was present as an embedded link within an HTML page that was previously referenced either within a certain time interval (10, 30, 60, and 120 seconds), or within a certain number of prior HTML pages (1, 3, 5, and 10). For each case, the table reports the fraction of URLs that were present as embedded links in those earlier HTML pages.
The interpretation of these results is not straightforward. First, there is no single ``Markov algorithm'' to compare to. For example, a Markov algorithm will declare two references to be dependent if they occur consecutively with more than a certain probability. Varying the threshold probability yields different algorithms. Second, Markov-based algorithms can find dependencies between any two pages, not just between an HTML page and another page. Therefore, Experiment E sheds some light on Markov algorithms versus our approach of examining links embedded in HTML, but it is not a definitive evaluation.
Experiment E considers only dependencies X ->Y, where X is an HTML page. In this subset of dependencies that a Markov algorithm might find, the results indicate that the (presumably) simpler method of inspecting HTML can locate a high percentage of dependencies. For instance, 39.6% of such dependencies can be discovered by inspecting only the single prior HTML page; 70.0% can be discovered by inspecting the HTML pages that were referenced in the preceding 10 seconds. These results are conservative, since it is not certain that any particular Markov algorithm would succeed in locating 100% of the dependencies.