
To determine the performance impact of disk I/O, we must
estimate the average response time RS from storage.
We model each storage server as a simple queuing center,
parameterized for k disks;
to simplify the presentation, we assume that the storage servers
in the utility are physically homogeneous.
Given a stable request mix,
we estimate the utilization of a storage server
at a given IOPS request load ![]() as
as
![]() ,
where
,
where ![]() is its saturation throughput in IOPS for
that service's file set and workload profile.
We determine
is its saturation throughput in IOPS for
that service's file set and workload profile.
We determine ![]() empirically for a given request mix.
A well-known response time formula then predicts the average storage
response time as:
empirically for a given request mix.
A well-known response time formula then predicts the average storage
response time as:
| (3) |
 |
This model does not reflect variations in cache behavior within the
storage server, e.g., from changes to M or ![]() .
Given the heavy-tailed nature of Zipf distributions,
Web server
miss streams tend to show poor locality
when the Web server cache (M) is reasonably
provisioned [14].
.
Given the heavy-tailed nature of Zipf distributions,
Web server
miss streams tend to show poor locality
when the Web server cache (M) is reasonably
provisioned [14].
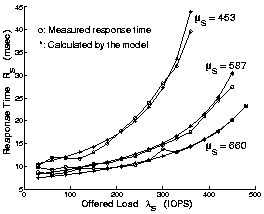
Figure 4 shows that this model closely approximates storage server behavior at typical utilization levels and under low-locality synthetic file access loads (random reads) with three different fileset sizes (T). We used the FreeBSD Concatenated Disk Driver (CCD) to stripe the filesets across k=4 disks, and the fstress tool [2] to generate the workloads and measure RS.
Since storage servers may be shared,
we extend the model to
predict RS when the
service receives an allotment ![]() of storage server resources,
representing the maximum storage throughput in IOPS
available to the service within its share.
of storage server resources,
representing the maximum storage throughput in IOPS
available to the service within its share.
| (4) |
This formula assumes that some scheduler enforces
proportional shares
![]() for storage.
Our prototype uses Request Windows [18] to approximate
proportional sharing. Other approaches to differentiated
scheduling for storage [23,33] are also applicable.
for storage.
Our prototype uses Request Windows [18] to approximate
proportional sharing. Other approaches to differentiated
scheduling for storage [23,33] are also applicable.