Our main design considerations for Wrapfs were:
The first five points are discussed below. Performance is addressed in detail in Section 5.
As shown in Figure 1, Wrapfs is independent of the host system's vnode interface. Since most UNIX-like systems (including those that currently support Wrapfs) have static vnode interfaces, this means that Wrapfs cannot introduce fundamentally new vnode operations.1 (Limited new functionality can be added using new ioctl(2) calls.) Our stackable file system architecture can, however, manipulate data, names, and attributes of files. We let Wrapfs users manipulate any of these.
The most obvious manipulation Wrapfs users want to do is of file data; that is useful for many applications, for example in encryption file systems. The next most likely item to manipulate is the file name. For example, an encryption file system can encrypt file names as well as data. A file system that translates between Unix and MS-DOS style file names can uniquely map long mixed-case Unix file names to 8.3-format upper-case names.
Finally, there are file attributes that users might want to change. For example, a file system can ensure that all files within it are world readable, regardless of the individual umask used by the users creating them. This is useful in directories where all files must be world-readable (such as html files served by most Web servers). Another file system might prevent anyone from setting the uid bit on executables, as a simple form of intrusion avoidance.
The aforementioned list of examples is not exhaustive, but only a hint of what can be accomplished with level of flexibility that Wrapfs offers. Wrapfs's developer API is summarized in Table 1 and is described below.
The system call interface offers two methods for reading and writing file data. The first is by using the read and write system calls. The second is via the MMAP interface. The former allows users to manipulate arbitrary amounts of file data. In contrast, the MMAP interface operates on a file in units of the native page size. To accommodate the MMAP interface, we decided to require file system developers using Wrapfs to also manipulate file data on whole pages. Another reason for manipulating only whole pages was that some file data changes may require it. Some encryption algorithms work on fixed size data blocks and bytes within the block depend on preceding bytes.
All vnode calls that write file data call a function encode_data before writing the data to the lower level file system. Similarly, all vnode calls that read file data call a function decode_data after reading the data from the lower level file system. These two functions take two buffers of the same size: one as input, and another as output. The size of the buffer can be defined by the Wrapfs developer, but it must be an even multiple of the system's page size, to simplify handling of MMAP functions. Wrapfs passes other auxiliary data to the encode and decode functions, including the file's attributes and the user's credentials. These are useful when determining the proper action to take. The encode and decode functions return the number of bytes manipulated, or a negative error code.
All vnode functions that manipulate file data, including the MMAP ones, call either the encode or decode functions at the right place. Wrapfs developers who want to modify file data need not worry about the interaction between the MMAP, read, and write functions, about file or page locks, reference counts, caches, status flags, and other bookkeeping details; developers need only to fill in the encode and decode functions appropriately.
Wrapfs provides two file name manipulating functions: encode_filename and decode_filename. They take in a single file name component, and ask the Wrapfs developer to fill in a new encoded or decoded file name of any length. The two functions return the number of bytes in the newly created string, or a negative error code. Wrapfs also passes to these functions the file's vnode and the user's credentials, allowing the function to use them to determine how to encode or decode the file name. Wrapfs imposes only one restriction on these file name manipulating functions. They must not return new file names that contain characters illegal in Unix file names, such as a null or a ``/''.
The user of Wrapfs who wishes to manipulate file names need not worry about which vnode functions use file names, or how directory reading (readdir) is being accomplished. The file system developer need only fill in the file name encoding and decoding functions. Wrapfs takes care of all other operating system internals.
For the first prototype of Wrapfs, we decided not to force a specific API call for accessing or modifying file attributes. There are only one or two places in Wrapfs where attributes are handled, but these places are called often (i.e., lookup). We felt that forcing an API call might hurt performance too much. Instead, we let developers inspect or modify file attributes directly in Wrapfs's source.
There are two important issues relating to the extension of the Wrapfs API to user-level: mount points and ioctl calls.
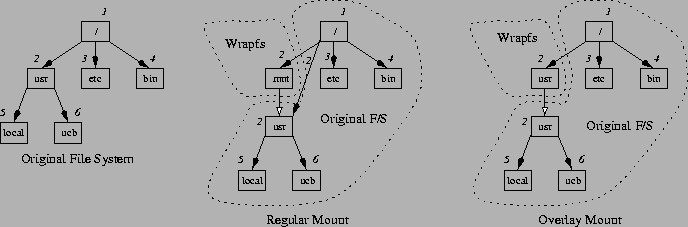
Wrapfs can be mounted as a regular mount or an overlay mount. The choice of mount style is left to the Wrapfs developer. Figure 2 shows an original file system and the two types of mounts, and draws the boundary between Wrapfs and the original file system after a successful mount.
In a regular mount, Wrapfs receives two pathnames: one for the mount point (/mnt), and one for the directory to stack on (the mounted directory /usr). After executing, for example, mount -t wrapfs /mnt /usr, there are two ways to access the mounted-on file system. Access via the mounted-on directory (/usr/ucb) yields the lower level files without going through Wrapfs. Access via the mount point (/mnt/ucb), however, goes through Wrapfs first. This mount style exposes the mounted directory to user processes; it is useful for debugging purposes and for applications (e.g., backups) that do not need the functionality Wrapfs implements. For example, in an encryption file system, a backup utility can backup files faster and safer if it uses the lower file system's files (ciphertext), rather than the ones through the mount point (cleartext).
In an overlay mount, accomplished using mount -t wrapfs -O /usr, Wrapfs is mounted directly on top of /usr. Access to files such as /usr/ucb go though Wrapfs. There is no way to get to the original file system's files under /usr without passing through Wrapfs first. This mount style has the advantage of hiding the lower level file system from user processes, but may make backups and debugging harder.
The second important user-level issue relates to the ioctl(2) system call. Ioctls are often used to extend file system functionality. Wrapfs allows its user to define new ioctl codes and implement their associated actions. Two ioctls are already defined: one to set a debugging level and one to query it. Wrapfs comes with lots of debugging traces that can be turned on or off at run time by a root user. File systems can implement other ioctls. An encryption file system, for example, can use an ioctl to set encryption keys.
When Wrapfs is used on top of a disk-based file system, both layers cache their pages. Cache incoherency could result if pages at different layers are modified independently. A mechanism for keeping caches synchronized through a centralized cache manager was proposed by Heidemann[5]. Unfortunately, that solution involved modifying the rest of the operating system and other file systems.
Wrapfs performs its own caching, and does not explicitly touch the caches of lower layers. This keeps Wrapfs simpler and more independent of other file systems. Also, since pages can be served off of their respective layers, performance is improved. We decided that the higher a layer is, the more authoritative it is: when writing to disk, cached pages for the same file in Wrapfs overwrite their UFS counterparts. This policy correlates with the most common case of cache access, through the uppermost layer. Finally, note that a user process can access cached pages of a lower level file system only if it was mounted as a regular mount (Figure 2). If Wrapfs is overlay mounted, user processes could not access lower level files directly, and cache incoherency for those files is less likely to occur.