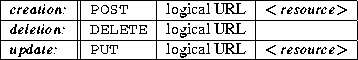The Web++ servlet provides a support for resource replica creation, deletion and update. The replica management actions are carried on top of HTTP POST, DELETE and PUT operations with the formats shown in Figure 8.
After receiving POST, DELETE or PUT requests, the servlet creates a new copy of the resource, deletes the resource or updates the resource specified by the logical URL depending on the type of operation. In addition, if the operation is either POST or DELETE, the servlet also updates its local replication directory to reflect either creation or destruction of its replica. The servlet also propagates the update to other servers using the algorithm described in [41] that guarantees eventual consistency of the replication directories. We assume that such an exchange will occur only among the servers within the same administrative domain (for scalability and security reasons). Servers in separate administrative domains can still help each other to resolve the logical URL references by exporting a name service that can be queried by servers outside of the local administrative domain. The name service can be queried by sending an HTTP GET request to a well known URL. The logical URL to be resolved is passed as an argument in the URL.
The Web++ servlet provides the basic operations for creation, destruction and update of replicated resource. Such operations can be used as basic building blocks for algorithms that decide if a new replica of a resource should be created, on which server it should be created or how the replicas should be kept consistent in the presence of updates. Web++ provides a framework within which such algorithms can be implemented. In particular, each of the servlet handlers for POST, DELETE and PUT operations can invoke user-supplied methods (termed pre-filters and post-filters) either before or after the handler is executed. Any of the operations mentioned above can be implemented as a pre or post filter. Algorithms that dynamically decide whether the system should be expanded with an additional server have been described in [9,42]. Algorithms that dynamically determine near optimal placement of replicated resources within a network have been studied in [5,43]. Finally, algorithms for replica consistency maintenance have been described in [24,40,8]. However, in order to apply them to the Web these algorithms need to be extended with new performance metrics as well as take into account the hierarchical structure of the Internet. Study of such algorithms exceeds the scope of this paper.