
In this first experiment, we have configured the compressed cache using what we though would be nice parameters. We have used a 1Mbyte cache and a cleaning threshold of 50% of the cache. Using these values, we executed all the benchmarks and computed the speedup obtained when compared to the original swapping mechanism. Figure 4 presents these results.
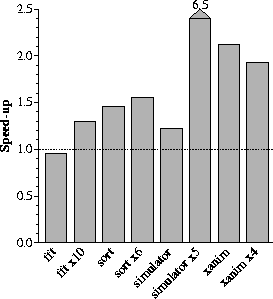
Figure 4:
Effect of the compressed swap on several workloads.
In this graph we can see that all benchmarks but one observe a speedup between 1.2 and 2.1. This means that these applications run, at least, a 20% faster than with the original swapping mechanism and there are even executions where the applications half their execution time. The two exceptions to this rule are fft and simulator x5.
The first one (fft) achieves a speedup of 0.96, which means that it runs slower than with the original system. This slowdown is due to two basic factors. The first one is that the compression ratio is not very good and most pages cannot be compressed less than 2048 bytes. This means that it is quite difficult to place more than one page per buffer or disk block. The second reason is that taking memory from the application for our data structures and cache buffers has a significant effect on the application. Without this memory, the working set of some parts does not fit in memory anymore and the application pages much more than with the original system.
The second exception to a reasonable speedup is the execution of 5 concurrent simulations (simulator x5). This benchmark achieves a speedup of 6.5. Such an impressive improvement is due to its incredible compression ratio. As pages compress so well, most swapped pages fit in the cache and nearly no disk access are needed.
These two exceptions will not be very frequent and we should expect a performance improvement between 20% to 100%, which is a significant gain.
Another unexpected result is the low speedup obtained by the simulator benchmark. As this benchmark compresses very well (6.7%), we expected to have a much more important speedup. The reason behind this behavior is the well behavior it has on the original system. As it swaps out many pages in very small periods of time, the original system can group them together before sending them to the disk and performs something similar to a batched write. For this reason, the gains we obtain by batching write operations together is also gained by the original system. This situation only happens in the original kernel when many pages are swapped out while writing the disk is busy. The kernel coalesces all these requests in a single one if contiguous. Anyway, this does not happen too often as we can see from the speedups obtained by the other benchmarks.