In its current form the NetApp Auto-diagnosis System consists of a continuous monitoring subsystem and a set of diagnostic commands. ONTAP's continuous monitoring logic consists of a thread that wakes up every minute and performs a series of checks on statistics that are maintained by various ONTAP subsystems. These checks may flag the system as being in an ERROR state. This logic is currently hard-coded into ONTAP (as C code tightly integrated into the kernel) and needs to be tuned with every maintenance release. Threshold values and most constants used by this logic are read from a file present root filesystem of the filer3. This logic does not yet perform any output for direct user consumption; nor does this logic execute any active tests. Instead this output is logged internally in ONTAP for consumption by the various diagnostic commands, which also execute any active tests that are needed. Since in ONTAP all commands are implemented in the same address space as the kernel, it is straightforward for the data gathered by continuous monitoring to be accessed by the diagnostic commands. Likewise, it is easy for the active test logic to be executed by the diagnostic commands.
When the customer or a support person debugging a field problem suspects that the problem lies in the networking portion of ONTAP, she executes the netdiag command. The netdiag command analyzes the information logged by the continuous monitoring subsystem, performing any active tests that may be called for and reports the results of this analysis, and some recommendations on how to fix any detected problems, to the user. Our plan is to have the computation of the various diagnostic commands be performed automatically after the next few releases of ONTAP.
The checks that ONTAP's continuous monitoring system performs and the various thresholds used by this logic have been defined using data from a variety of sources of collected knowledge. These include FAQs compiled by the NetApp engineering and customer support organizations over the years, troubleshooting guides compiled by NetApp support, historical data from NetApp's customer call record and engineering bug databases, information from advanced ONTAP system administration and troubleshooting courses that are offered to NetApp's customers, and ideas contributed by some problem debugging experts at NetApp.
The specific monitoring rules and the values of various constants and thresholds used by the monitoring logic and even the list of problems that ONTAP's auto-diagnosis subsystem will address when complete is fairly extensive; due to space considerations we will not cover this information in full detail. Instead, we will restrict the following discussion to some common networking problems that ONTAP currently attempts to auto-diagnose. We will describe the set of problems targeted by this logic and illustrate its operation with two examples.
At the link layer, ONTAP attempts to diagnose Ethernet duplex and speed mismatches, Gigabit auto-negotiation mismatches, problems due to incorrect setting of store and forward mode on some network interface cards (NICs), link capacity problems, EtherChannel load balancing problems and some common hardware problems. At the IP layer, ONTAP can diagnose common routing problems and problems related to excessive fragmentation. At the transport layer, ONTAP can diagnose common causes of poor TCP performance. At the system level, ONTAP can diagnose problems due to inconsistent information in different configuration files, unavailability or unreachability of important information servers such as DNS and NIS servers, and insufficient system resources for the networking code to function at the load being offered to it.
To see how the techniques described in the previous section are used, consider the link layer diagnosis logic. The continuous monitoring system monitors the different event statistics such as total packets in, total packets out, incoming packets with CRC errors, collisions, late collisions, deferred transmissions etc., that are maintained by the various NIC device drivers. Assume that the continuous monitoring logic notices a large number of CRC errors. Usually, this will also be noticed as poor application-level performance.
Without auto-diagnosis, the manner in which this field problem is handled depends on the skill level and the debugging approach of the person addressing the problem. Some people will simply assume bad hardware and swap the NIC. Other people will first check for a duplex mismatch (if the NIC is an Ethernet NIC) by looking at the duplex settings of the NIC and the corresponding switch port, and if no mismatch is found may try a different cable and a different switch port in succession before swapping the NIC.
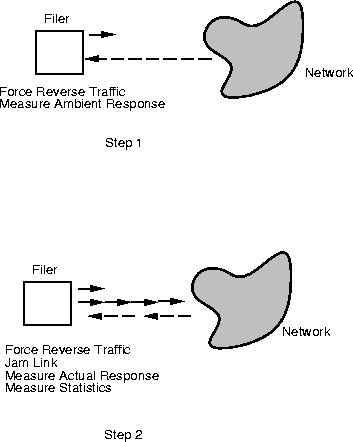
With the netdiag command, this process is much more formal and precise (Figure 2). The netdiag command first executes a protocol augmentation based test for detecting if there is a duplex mismatch. Specifically, the command forces some ``reverse traffic'' from the other machines on the network to the filer using a variety of different mechanisms in turn until one succeeds. These mechanisms include an ICMP echo-request broadcast, layer 2 echo-request broadcast and TCP/UDP traffic to well-known ports for hosts in the ARP cache of the filer. First the ambient rate of packet arrival at the filer using whatever mechanism that generated sufficient return traffic is measured (Figure 2, Step 1). Next this reverse traffic is initiated again using the same mechanism as before and the suspect outgoing link is jammed with back-to-back packets destined to the filer itself (which will be discarded by the switch). The reverse traffic rate is then measured, along with the number of physical level errors during the jam interval (Figure 2, Step 2). If there is indeed a duplex mismatch, these observations are sufficient to discover it, since the reverse rate will interfere with the forward flow inducing certain types of errors only if the duplex settings are not configured correctly. In this case, the netdiag command prints information on how to fix the mismatch.
If the reason behind the duplex mismatch is a recent change to the filer's configuration parameters, this information will also be inferred by the auto-diagnosis logic and printed for the benefit of the user. If the NIC in question noticed a link-down-up event in the recent past and no CRC errors had been seen before that event, the netdiag command will print out this information as it could indicate a switch port setting change, or a cable change or a switch port change event which might have triggered off the mismatch. This extra information, which is made possible by automatic configuration change tracking, is important because it helps the customer discover the cause of the problem and ensure that it does not repeat. This problem may have been caused by, for example, two administrators inadvertently acting at cross-purposes. If there is no duplex mismatch, the netdiag command prints a series of recommendations, such as changing the cable, switch port and the NIC, in the precise order in which they should be tried by the user. The order itself is based on historical data regarding the relative rates of occurrence of these causes.
As another example, consider the TCP auto-diagnosis logic. ONTAP's TCP continuously monitors the movement of each peer's advertised window and the exact timings of data and acknowledgment packet arrivals. A number of rules (which are described in detail in a forthcoming paper) are used to determine if the peer, or the network, or even the filer is the bottleneck factor in data transfer. For instance, if the filer is sending data through a Gigabit interface but the receiver client does not advertise a window that is large enough for the estimated delay-bandwidth product of the connection, the client is flagged as ``needing reconfiguration''. If the receiver did initially (at the beginning of the connection) advertise a window that was sufficiently large, but subsequently this window shrank, this indicates that the client is unable to keep up with protocol processing at the maximum rate supported by the network, and this situation is flagged.
Cross-layer analysis is used to make the TCP logic aware as to what time-periods of a TCP connection are ``interesting'' from the point of view of performance auto-diagnosis of the type described in the previous paragraph. For example, the beginning of a large NFS read may indicate the beginning of an ``interesting'' time period for an otherwise idle TCP connection. Protocol augmentation (using ICMP ping based average RTT measurement) is used to estimate the delay-bandwidth product of the path to various clients.