Many field problems with appliance systems are caused by changes in the system's environment. These include system configuration changes and changes in the offered load. As described earlier, there is a lot of value in continuous monitoring of system statistics to notice shifts in metrics like average system load. Likewise, it is useful to track changes in the system's configuration, both explicit as well as implicit.
Automatic tracking of configuration changes is useful in finding the cause of appliance problems that occur after a system has been up and running correctly for some time. This technique also helps in prescribing solutions for the problems found by other auto-diagnosis methods. In many organizations, there are multiple administrators responsible for the IT infrastructure. Configuration change tracking allows for actions of one administrator that result in an appliance problem to be easily reversed by another administrator. This is also useful where administrative boundaries partition the network fabric and the clients from the filer.
The fundamental motivation behind automatic configuration change tracking is to automatically gather information that is asked for by human problem debuggers in a large majority of cases. Anyone familiar with the process of field debugging probably knows that one of the first questions that a customer reporting a problem gets asked by the problem solving expert is: ``What has changed recently?'' The answer to this is often only loosely accurate (especially in a multi-administrator environment), or even incorrect, depending on the skill level of the customer/user. Automatic configuration change tracking makes precise and comprehensive state change information available to the problem solver, i.e., the auto-diagnosis logic or a human expert.
Configuration changes are tracked by a special module of the appliance OS. As hinted above, configuration changes are of two types: the first type of changes are explicit, and correspond to state changes initiated by its operator. The second type of changes are implicit, e.g., an event of link-status loss and link-status regain when a cable is pulled out and re-inserted into one of a filer's network interface cards. The system logs both explicit and implicit changes. The amount of change information that needs to be kept around is a system design parameter, and may require some experience in getting to optimal for any particular appliance.
Given comprehensive configuration change information, when a problem occurs the various events between the last instance of time which was known to be problem free to the current event are examined and analyzed. The software logic to do this analysis, like the logic for continuous monitoring, is system specific and may need to be evolved over time. In some cases, the auto-diagnosis system can directly infer the cause for the field problem, and report this. In other cases, the set of all applicable configuration changes can be made available to the human debugging the system.
Note that it is not absolutely imperative to log all relevant configuration change information. (In fact, some configuration changes may not be easily visible to the appliance. For example, the path between a client and a filer may involve multiple routers, and it may be possible to change/re-configure one of these without the filer noticing any changes in its environment.) State change information is however only a set of hints that guide the problem diagnosis process and make it easier. If some relevant state change information is not logged, diagnosing the cause of a specific problem may become harder, but not necessarily impossible. In our experience, logging even a modestly-sized, carefully chosen set of configuration change information, is extremely valuable in the problem diagnosis process.
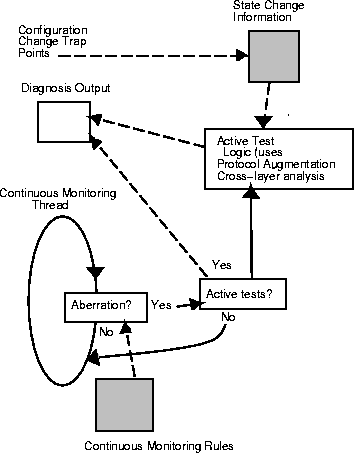
Figure 1 shows the role of the various auto-diagnosis techniques in the problem diagnosis process. In the figure, dashed lines indicate flow of data while solid lines indicate flow of control. The shaded rectangles indicate stores of data or logic rules. The unshaded rectangles indicate processing steps. Note that the problem diagnosis process uses all the techniques we described above. The techniques are complementary and designed to work with each other; they are not different types of procedures targeted to address disjoint problem sets.