Although the methods discussed so far ensure that a process experiences no performance loss during its execution, there still remains the issue of resynchronization latencies when transitioning power states of the nodes before a process is executed. As mentioned earlier, with RDRAM, switching a device from Nap to Standby mode requires 225 ns, which is not a very long time, but is nontrivial, as it would be incurred on every context switch. If this latency is not properly handled and hidden, it could, as a result of increased runtimes, erode the energy savings and undermine the techniques described above.
One possible solution is that at every scheduling point, we find not
only the best process ![]() to run, but also the second best process
to run, but also the second best process ![]() .
Before making a context switch to process
.
Before making a context switch to process ![]() , we transition the union
of the nodes in
, we transition the union
of the nodes in ![]() and
and ![]() to Standby mode. The idea
here is that with a high probability, at the next scheduling point, we
will either continue execution of process
to Standby mode. The idea
here is that with a high probability, at the next scheduling point, we
will either continue execution of process ![]() or switch to process
or switch to process ![]() .
Effectively, the execution time of the current executing
process will mask the resynchronization latency for the next process.
Of course, the cost here is that more nodes need to be in Standby mode
than needed for the current process, incurring greater energy costs,
but, with a high probability, performance degrading latencies are
eliminated.
.
Effectively, the execution time of the current executing
process will mask the resynchronization latency for the next process.
Of course, the cost here is that more nodes need to be in Standby mode
than needed for the current process, incurring greater energy costs,
but, with a high probability, performance degrading latencies are
eliminated.
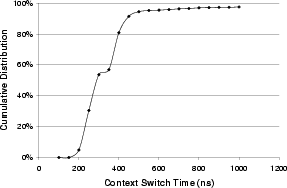
A second solution is more elegant, has lower computational and energy overheads, and uses the context switching time to naturally mask resynchronization latencies. This is based on the fact that context switching takes time, due to loading new page tables and modifying internal kernel data structures, even before the next process's memory pages are touched. We instrumented the Linux 2.4.18 kernel to measure the portion of context switching time in the scheduler function after deciding which process to execute next, but before beginning its execution. The cumulative distribution of context switch times on a Pentium 4 processor clocked at 1.6 GHz is shown in Figure 4. From the figure, we can see that over 90% of all context switches take longer than 225 ns, and therefore, can fully mask the resynchronization latency for transitioning nodes from Nap to Standby mode. The sharp increase in the cumulative distribution function between 175 and 225 ns indicates that we only pay a few tens of nanoseconds for the other less than 10% of context switches. This approach, therefore, hides most of the latency without incurring additional energy penalties.
With faster processors in the future, the cumulative distribution function of context switch times shifts left, making the second solution less attractive as the latencies will less likely be masked. The first solution proposed is more general and may be applied without any hardware constraints, but at a higher energy overhead. In reality, however, even as processor frequencies are rapidly increasing, context switch times improve rather slowly, so the second solution is viable under most circumstances.