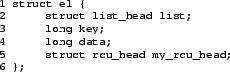
Although RCU has been used in a great many interesting and surprising ways, one of the most straightforward is as a replacement for reader-writer locking. In this section, we present this analogy, protecting the simple doubly-linked-list data structure shown in Figure 6 with reader-writer locks and then with RCU, comparing the results. This structure has a struct list_head that is manipulated by the standard Linux list-manipulation primitives, a search key, and a single integer for data. The RCU primitive call_rcu() requires some space in the data element, which is supplied by the my_rcu_head field.
The reader-writer-lock/RCU analogy substitutes primitives as shown in Table 1. The asterisked primitives are no-ops in non-preemptible kernels; in preemptible kernels, they suppress preemption, which is an extremely cheap operation on the local task structure. Note that since neither rcu_read_lock() nor rcu_read_unlock block irq or softirq contexts, it is necessary to add primitives for this purpose where needed. For example, read_lock_irqsave must become rcu_read_lock() followed by local_irq_save().
Deletion from the list is illustrated by the upper section of Table 2. The write_lock() and write_unlock() are replaced by spin_lock() and spin_unlock(), respectively, the list_del() is replaced by list_del_rcu(), and my_free() is replaced by call_rcu(). The call_rcu() will, after a grace period elapses, pass p to function my_free(), using the struct rcu_head in the my_rcu_head field to keep track of the deferred function call and argument.
|
Insertion into the list is illustrated by the second section of Table 2. Again, the write_lock() and write_unlock() are replaced by the simple spinlock primitives spin_lock() and spin_unlock(), respectively. The list_add_tail() is replaced by list_add_tail_rcu(). The rest of the code remains the same.
Searching the list is illustrated by the third section of Table 2. Locking is handled by the caller, so the two variants differ only in that the list_for_each() is replaced by list_for_each_rcu().
Searching the list for read-only access is illustrated by the last section of Table 2. The only difference is that the read_lock() and read_unlock() primitives are replaced by rcu_read_lock() and rcu_read_unlock(), respectively. Again, the bulk of the code remains the same for both cases.
Although this analogy can be quite compelling and useful, there are some caveats:
Where it applies, this analogy can deliver full parallelism with almost no increase in complexity. For example, Section 4 shows how applying this analogy to System V IPC yields order-of-magnitude speedups with a very small increase in code size and complexity.
RCU has also been used as a lazy barrier synchronization mechanism, as a mode-change control mechanism, as well as for more sophisticated list maintenance. Retrofitting existing code with RCU as shown above can produce significant performance gains, but of course the best results are obtained by designing RCU into the algorithms and code from the start.
Other methods have been proposed for eliminating locking [Herlihy93], and, when combined with more recent refinements [Michael02a,Michael02b], these methods are practical in some circumstances. However, they still require expensive atomic operations on shared storage, resulting in pipeline stalls, cache thrashing, and memory contention, even for read-only accesses.