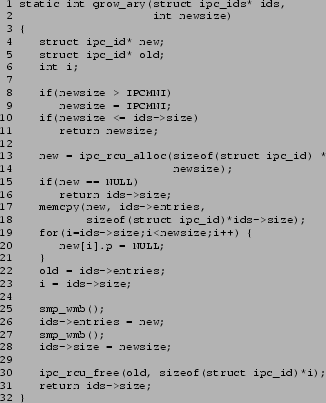
If a large number of semaphores are created, the kernel will need to expand the ipc_id array. Use of RCU dictates that this expansion occur in parallel with ongoing searching by ipc_lock(). The function grow_ary(), shown in Figure 13, implements this expansion.
Lines 8-11 do limit checking. Lines 13-21 allocate the new array, copy the old array to the first part of the new array, and initialize the remainder of the new array. Lines 22 and 23 retain the size of the old array and a pointer to it. Line 25 is a memory barrier that prevents the CPU and the compiler from reordering the array initialization with the assignment of the pointer. Any such reordering could cause other CPUs to see uninitialized segments of the array, possibly crashing (or worse!). Line 26 switches the pointer over to the new array, but any accesses at this point will recognize only the old entries as valid, since the size is still the old size. Line 27 is a memory barrier that prevents the CPU and the compiler from reordering the assignment of the size to precede the pointer assignment. If such a reordering were to occur while a user was attempting to access an erroneously larger semid, the kernel would run off the end of the old array, again, possibly crashing. Line 28 updates the size, so that new semaphores with larger semids may now be accommodated. Line 30 invokes ipc_rcu_free(), which frees the old structure after a full grace period has elapsed. Note that ipc_rcu_free() returns immediately, having used call_rcu() to queue the old array for a later kfree(). Finally, Line 31 returns the new size of the array.
Note that no deleted flag is needed here, since the old version of the array is kept valid throughout the grace period. Any semaphore in existence at the start of the racing access that is still in existence when the racing access completes will still be correctly referenced by the old array. Note that the racing access must by definition complete before the grace period ends - otherwise, it is not a grace period.
This tolerance of stale data is typical of ID-to-address mappings, and of routing tables as well.