
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
USENIX 2002 Annual Technical Conference Paper
[USENIX 2002 Technical Program Index]
Bridging the Information Gap in Storage Protocol StacksTimothy E. Denehy, Andrea C. Arpaci-Dusseau, and Remzi H. Arpaci-Dusseau
Abstract:
The functionality and performance innovations in file systems and
storage systems have proceeded largely independently from each other over the
past years. The result is an information gap: neither has information
about how the other is designed or implemented, which can result in a high
cost of maintenance, poor performance, duplication of features, and
limitations on functionality. To bridge this gap, we introduce and evaluate a
new division of labor between the storage system and the file system. We
develop an enhanced storage layer known as Exposed RAID (ExRAID), which
reveals information to file systems built above; specifically, ExRAID exports
the parallelism and failure-isolation boundaries of the storage layer, and
tracks performance and failure characteristics on a fine-grained basis. To
take advantage of the information made available by ExRAID, we develop an
Informed Log-Structured File System (I.LFS). I.LFS is an extension of the
standard log-structured file system (LFS) that has been altered to take
advantage of the performance and failure information exposed by
ExRAID. Experiments reveal that our prototype implementation yields benefits
in the management, flexibility, reliability, and performance of the storage
system, with only a small increase in file system complexity. For example,
I.LFS/ExRAID can incorporate new disks into the system on-the-fly, dynamically
balance workloads across the disks of the system, allow for user control of
file replication, and delay replication of files for increased
performance. Much of this functionality would be difficult or impossible to
implement with the traditional division of labor between file systems and
storage.
|
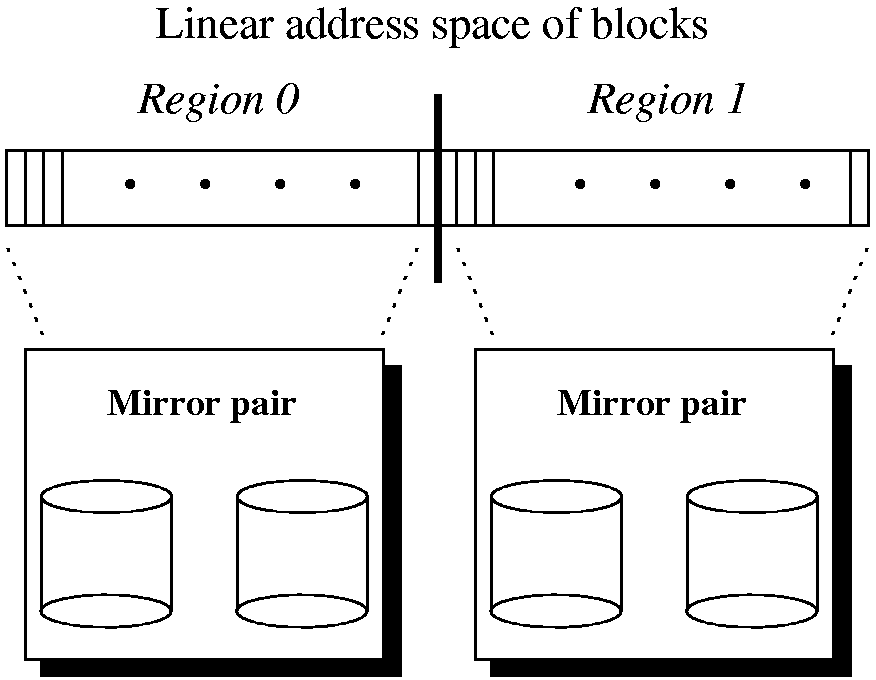 |
Within ExRAID, a region may represent more than just a single disk. For example, a region could be configured to represent a mirrored pair of disks, or even a RAID-5 collection. Thus, each region can be viewed as a configurable software-based RAID, and the entire ExRAID address space as a single representation of the conglomeration of such RAID subsystems. In such a scenario, some information is hidden from the file system, but cross-region optimizations are still possible, if more than one region exists. An example of an ExRAID configuration over mirrored pairs is shown in Figure 1.
Allowing each region to represent more than just a single disk has two primary benefits. First, if each region is configured as a RAID (such as a mirrored pair of disks), the file system is not forced to manage redundancy itself, though it can choose to do so if so desired. Second, this arrangement allows for backwards compatibility, as ExRAID can be configured as a single striped, mirrored, or RAID-5 region, thus allowing unmodified file systems to use it without change.
Although the segmented address space exposes the nature of the underlying disk system to the file system (either in part or in full), this knowledge is often not enough to make intelligent decisions about data placement or replication. Thus, the ExRAID layer exposes dynamic information about the state of each region to the file system above, and it is in this way that ExRAID distinguishes itself from traditional volume managers.
Two pieces of information are needed. First, the file system may desire to have performance information on a per-region basis. The ExRAID layer tracks queue lengths and current throughput levels, and makes these pieces of information available to the file system. Historical tracking of information is left to the file system.
Second, the file system may wish to know about the resilience of each region, i.e., when failures occur, and how many more failures a region can tolerate. Thus, ExRAID also presents this information to the file system. For example, in Figure 1, the file system would know that each mirror pair could tolerate a single disk failure, and would be informed when such a failure occurs. The file system could then take action, perhaps by directing subsequent writes to other regions, or even by moving important data from the ``bad'' region into other, more reliable portions of the ExRAID address space.
In our current implementation, ExRAID is implemented as a thin layer between the file system and the storage system. In order to implement a striped, mirrored, or RAID-5 region, we simply utilize the standard software RAID layer provided with NetBSD. However, our prototype ExRAID layer is not completely generalized as of this date, and thus in its current form would require some effort to allow a file system other than I.LFS to utilize it.
The segmented address space is built by interposing on the vnode strategy call, which allows us to remap requests from their logical block number within the virtual address space presented by ExRAID into a physical disk number and block offset, which can then be issued to underlying disk or RAID.
Dynamic performance information is collected by monitoring the current performance levels of reads and writes. In the prototype, region boundaries, failure information, and performance levels (throughput and queue length) are tracked in the low-levels of the file system. A more complete implementation would make the information available through an ioctl() interface to the ExRAID device. Also note that we focus primarily on utilizing the performance information in this paper.
We now describe the I.LFS file system. Our current design has four major pieces of additional functionality, as compared to the standard LFS: on-line expandability of the storage system, dynamic parallelism to account for performance heterogeneity, flexible user-managed redundancy, and lazy mirroring of writes. In sum total, these added features make the system more manageable (the administrator can easily add a new disk, without worry of configuration), more flexible (users have control over if replication occurs), and have higher performance (I.LFS delivers the full bandwidth of the system even in heterogeneous configurations, and flexible mirroring avoids some of the costs of more rigid redundancy schemes). For most of the discussion, we focus on the case that most separates I.LFS/ExRAID from a traditional RAID, where the ExRAID layer exposes each disk of the storage system as a separate region to I.LFS.
Design: The ability to upgrade a storage system incrementally is crucial. As the performance or capacity demands of a site increase, an administrator may need to add more disks. Ideally, such an addition should be simple to perform (e.g., a single command issued by the administrator, or an automatic addition when the disk is detected by the hardware), require no down-time (thus keeping availability of storage high), and immediately make the extra performance and capacity of the new disk available.
In older systems, on-line expansion is not possible. Even if the storage system could add a new disk on-the-fly, it is likely the case that an administrator would have to unmount the partition, expand it (perhaps with a tool similar to that described in [46]), and then re-mount the file system. Worse, some systems require that a new file system be built, forcing the administrator to restore data from tape. More modern volume managers [48] allow for on-line expansion, but still need file system support.
Thus, our I.LFS design includes the ability to incorporate new disks (really, new ExRAID regions) on-line with a single command given to the file system. No complicated support is necessitated across many layers of the system. If the hardware supports hot-plug and detection of new disks without a power-cycle, I.LFS can add new disks without any down time and thus reduction in data availability. Overall, the amount of work an administrator must put forth to expand the system is quite small.
Contraction is also important, as the removal of a region should be as simple as the addition of one. Therefore, we also incorporate the ability to remove a region on the fly. Of course, if the file system has been configured in a non-redundant manner, some data will likely be lost. The difference between I.LFS and a traditional system in this scenario is that I.LFS knows exactly which files are available and can deliver them to applications.
Implementation:
To allow for on-line expansion and contraction of storage, the file system
views regions that have not yet been added as extant and yet fully
utilized; thus, when a new region is added to the system, the blocks of that
disk are made available for allocation, and the file system will immediately
begin to write data to them. Conversely, a region that is removed is viewed as
fully allocated. This technique is general and could be applied to other file
systems, and similar ideas have been used elsewhere [16].
More specifically, because a log-structured file system is composed of a collection of LFS segments, it is natural to expand capacity within I.LFS by adding more free segments. To implement this functionality, the newfs_ilfs program creates an expanded LFS segment table for the file system. The entries in the segment table record the current state of each segment. When a new ExRAID region is added to the file system, the pertinent information is added to the superblock, and an additional portion of the segment table is activated. This approach limits the number of regions that can be added to a fixed number (currently, 16); for more flexible growth, the segment table could be placed in its own file and expanded as necessary.
Design: One problem introduced by the flexibility an administrator has in growing a system is the increased potential for performance heterogeneity in the disk subsystem; in particular, a new disk or ExRAID segment may have different performance characteristics than the other disks of the system. In such a case, traditional striping and RAID schemes do not work well, as they all assume that disks run at identical rates [4,10].
Traditionally, the presence of multiple disks is hidden by the storage layer from the file system. Thus, current systems must handle any disk performance heterogeneity in the storage layer - the file system does not have enough information to do so itself. The research community has proposed schemes to deal with static disk heterogeneity [3,10,32,52], though many of these solutions require careful tuning by an administrator. As Van Jacobsen notes, ``Experience shows that anything that needs to be configured will be misconfigured'' [18].
Further complicating the issue is that the delivered performance of a device could change over time. Such changes could result from workload imbalances, or perhaps from the ``fail-stutter'' nature of modern devices, which may present correct operation but degraded performance to clients [5]. Even if more advanced heterogeneous data layout schemes are utilized, they will not work well under dynamic shifts in performance.
To handle such static and dynamic performance differences among disks, we include a dynamic segment placement mechanism within I.LFS [4]. A segment can logically be written to any free space in the file system; we exploit this by writing segments to ExRAID regions in proportion to their current rate of performance, exploiting the dynamic state presented to the file system by ExRAID. By doing so, we can dynamically balance the write load of the system to account for static or dynamic heterogeneity in the disk subsystem. Note that if performance of the disks is roughly equivalent, this dynamic scheme will degenerate to standard RAID-0 striping of segments across disks.
This style of dynamic placement could also be performed in a more traditional storage system (e.g., AutoRAID has the basic mechanisms in place to do so [51]). However, doing so unduly adds complexity into the system, as both the file system and the storage system have to track where blocks are placed; by pushing dynamic segment placement into the file system, overall complexity is reduced, as the file system already tracks where the blocks of a file are located.
Implementation:
The original version of LFS allocates segments sequentially based on
availability; in other words, all free segments are treated equally. To
better manage parallelism among disks in I.LFS, we develop a segment indirection technique. Specifically, we modify the ilfs_newseg() routine to
invoke a data placement strategy. The ilfs_newseg() routine is used to find the
next free segment to write to; here, we alter it to be ``region aware'', and
thus allow for a more informed segment-placement decision. By choosing disks
in accordance with their performance levels (information provided by ExRAID),
the load across a set of heterogeneously-performing regions can be balanced.
The major advantage of our decision to implement this functionality within the ilfs_newseg() routine is that it localizes the knowledge of multiple disks to a very small portion of the file system; the vast majority of code in the file system is not aware of the region boundaries within the disk address space, and thus remains unchanged. The slight drawback is that the decision of which region to place a segment upon is made early, before the segment has been written to; if the performance level of the disk changes as the segment fills in a significant way, the placement decision could potentially be a poor one. In practice, we have not found this to be a performance problem.
Design: Typically, redundancy is implemented in a one-size-fits-all manner, as a single RAID scheme (or two, as in AutoRAID) is applied to all the blocks of the storage system. The file system is typically neither involved nor aware of the details of data replication within the storage layer. This traditional approach is limiting, as much semantic information is available in the file system as well as in smart users or applications, which could be exploited to improve performance or better utilize capacity.
Thus, in I.LFS, we explore the management of redundancy strictly within the file system, as managing redundancy in the file system provides greater flexibility and control to users. In our current design, we allow users or applications to select whether a file should be made redundant (in particular, if it should be mirrored). If a file is mirrored, users pay the cost in terms of performance and capacity. If a file is not mirrored, performance increases during writes to that file, and capacity is saved, but the chances of losing the file are increased. Turning off redundancy is thus well-suited for temporary files, files that can easily be regenerated, or swap files.
Because I.LFS performs the replication, better accounting is also possible, as the system knows exactly which files (and hence which users) are using which physical blocks. In contrast, with a traditional file system mounted on top of an advanced storage system such as AutoRAID [51], users are charged based on the logical capacity they are using, whereas the true usage of storage depends on access patterns and usage frequency.
Because redundancy schemes are usually implemented within the RAID storage system (where no notion of a file exists), our scheme would not easily be implemented in a traditionally-layered system. The storage system is wholly unaware of which blocks constitute a file and therefore cannot receive input from a user as to which blocks to replicate; only if both the file system and storage system were altered could such functionality be realized. In the future, it would be interesting to investigate a range of policies on top of our redundancy mechanisms that automatically apply different redundancy strategies according to the class of a file, akin to how the Elephant file system segregates files for different versioning techniques [33].
 |
Implementation:
To accomplish our goal of per-file redundancy, we decided to utilize separate
and unique meta-data for original and redundant files. This approach is
natural within the file system as it does not require changes to on-disk data
structures.
In our implementation, we use a straight-forward scheme that assigns even inode numbers to original files and odd inode numbers to their redundant copies. This method has several advantages. Because the original and redundant files have unique inodes, the data blocks can be distributed arbitrarily across disks (given certain constraints described below), thus allowing us to use redundancy in combination with our other file system features. Also, the number of LFS inodes is unlimited because they are written to the log, and the inode map is stored in a regular file which is expanded as necessary. The prime disadvantage of our approach is that it limits redundancy to one copy, but this could easily be extended to an N-way mirroring scheme by reserving N i-numbers per file.
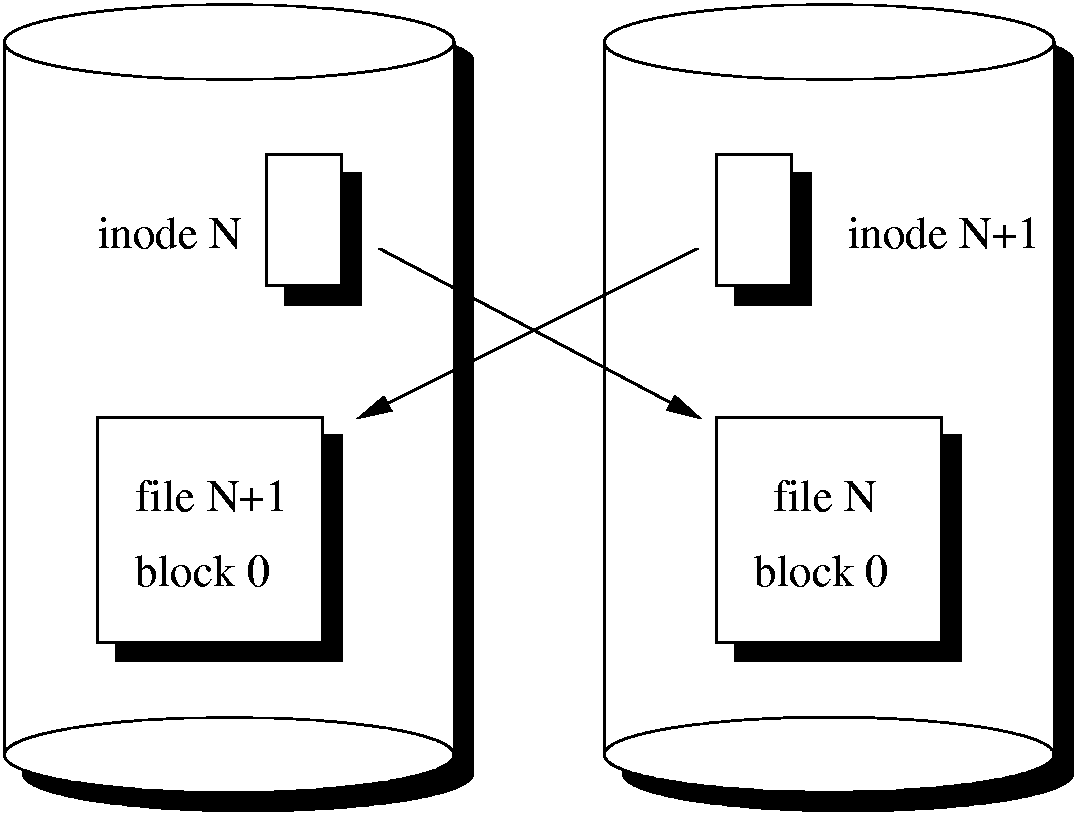
One problem introduced by our decision to utilize separate inodes to track the primary and mirrored copy of a file is what we refer to as the ``crossed pointer'' problem. Figure 2 illustrates the difficulty that can arise. Simply requiring each component of a file (e.g., the inode, indirect blocks, and data blocks) be replicated is not sufficient to guarantee that all data can be recovered easily under a single disk failure. Instead, we must ensure that each data block is reachable under a disk failure; a block being reachable implies that a pointer chain to it exists.
Consider the example in the figure: a file with inode number N is replicated within inode number N+1. Inode N is located on the first disk, as is the first data block of the mirror copy (file N+1). Inode N+1 is on the other disk, as is the first data block of the primary copy (file N). However, if either disk fails, the first data block is not easily recovered, as the inode on the surviving disk points to the data block on the failed disk. In some file systems, this would be a fatal flaw, as the data block would be unrecoverable. In LFS, it is only a performance issue, as the extra information found within segment summary blocks allows for full recovery; however, a disk crash would mandate a full scan of the disk to recover all data blocks.
There are a number of possible remedies to the problem. For example, one could perform an explicit replication of each inode and all other pointer-carrying structures, such as indirect blocks, doubly-indirect blocks, and so forth. However, this would require the on-disk format to change, and would be inefficient in its usage of disk space, as each inode and indirect block would have four logical copies in the file system.
Instead, we take a much simpler approach of divide and conquer. The disks of the system are divided into two sets. When writing a redundant file to disk, I.LFS decides which set the primary copy should be placed within; the redundant copy is placed within the other set. Thus, because no pointers cross from either set into the other, we can guarantee that a single failure will cause no harm (in fact, we can tolerate any number of failures to disks in that set).
Finally, incorporating redundancy into I.LFS also presents us with a difficult implementation challenge: how should we replicate the data and inodes within the file system, without re-writing every routine that creates or modifies data on disk? We develop and apply recursive vnode invocation to ease the task. We embellish most I.LFS vnode operations with a short recursive tail; therein, the routine is invoked recursively (with appropriate arguments) if the routine is currently operating on an even i-number and therefore on the primary copy of the data, and if the file is designated for redundancy by the user. For instance, when a file is created using ilfs_create(), a recursive call to ilfs_create() is used to create a redundant file. The recursion is broken within the call to perform the identical operation to the redundant file.
Design: User-controlled replication allows users to control if replication occurs, but not when. As has been shown in previous work, many potential benefits arise in allowing flexible control over when redundant copies are made or parity is updated [9]. Delaying parity updates has been shown to be beneficial in RAID-5 schemes to avoid the small-write problem [34], and could also reduce load under mirrored schemes. Implementing such a feature at the file system level allows the user to decide the window of vulnerability for each file, as losing data in certain files may likely be more tolerable than in others. Note that either of these enhancements would be difficult to implement in a traditional system, as the information required resides in both the file system and RAID, necessitating non-trivial changes to both.
In I.LFS, we incorporate lazy mirroring into our user-controlled replication scheme. Thus, users can designate a file as non-replicated, immediately replicated, or lazily replicated. By choosing a lazy replica, the user is willing to increase the chance of data loss for improved performance. Lazy mirroring can improve performance for one of two reasons. First, by delaying file replication, the file system may reduce load under a burst of traffic and defer the work of replication to a later period of lower system load. Second, if a file is written to disk and then deleted before the replication occurs, the cost of replication is removed entirely. As most systems buffer files in memory for a short period of time (e.g., 30 seconds), and file lifetimes have recently been shown to be longer than this on average [28], this second scenario may be more common than previously thought.
Implementation:
Lazy mirroring is implemented in I.LFS as an embellishment to the file-system
cleaner. For files that are designated as lazy replicas, an extra bit is set
in the segment usage table indicating their status. When the cleaner scans a
segment and finds blocks that need to be replicated, it simply performs the
replication directly, making sure to place replicated blocks so as to avoid
the ``crossed pointer'' problem, and associates them with the mirrored
inode. When the replication is complete, the bit is cleared. Currently, the
file system replicates files after a 2-minute delay, though in the future this
could be set directly by the user or application.
In this section, we present an evaluation of ExRAID and I.LFS. Experiments are performed upon an Intel-based PC with 128 MB of physical memory. The main processor is a 1-GHz Intel Pentium III Xeon, and the system houses four 10,000 RPM Seagate ST318305LC Cheetah 36XL disks (which we will refer to as the ``fast'' disks), and four 7,200 RPM Seagate ST34572W Barracuda 4XL disks (the ``slow'' disks). The fast disks can deliver data at roughly 21.6 MB/s each, and the slow disks at approximately 7.5 MB/s apiece. For all experiments, we perform 30 trials and show both the average and standard deviation.
In some experiments, we compare the performance of I.LFS/ExRAID to standard RAID-0 striping. Stripe sizes are chosen so as to maximize performance of the RAID-0 given the workload at hand, making the comparison as fair as possible, or even slightly unfair towards I.LFS/ExRAID.
In this first experiment, we demonstrate the baseline performance of I.LFS/ExRAID on top of two different homogeneous storage configurations, one with four slow disks, and one with four fast disks. The experiment consists of sequential write, sequential read, random write, and random read phases (based on patterns generated by the Bonnie [6] and IOzone [25] benchmarks). We perform this experiment to demonstrate that there is no unexpected overhead in our implementation, and that it scales to higher-performance disks effectively.
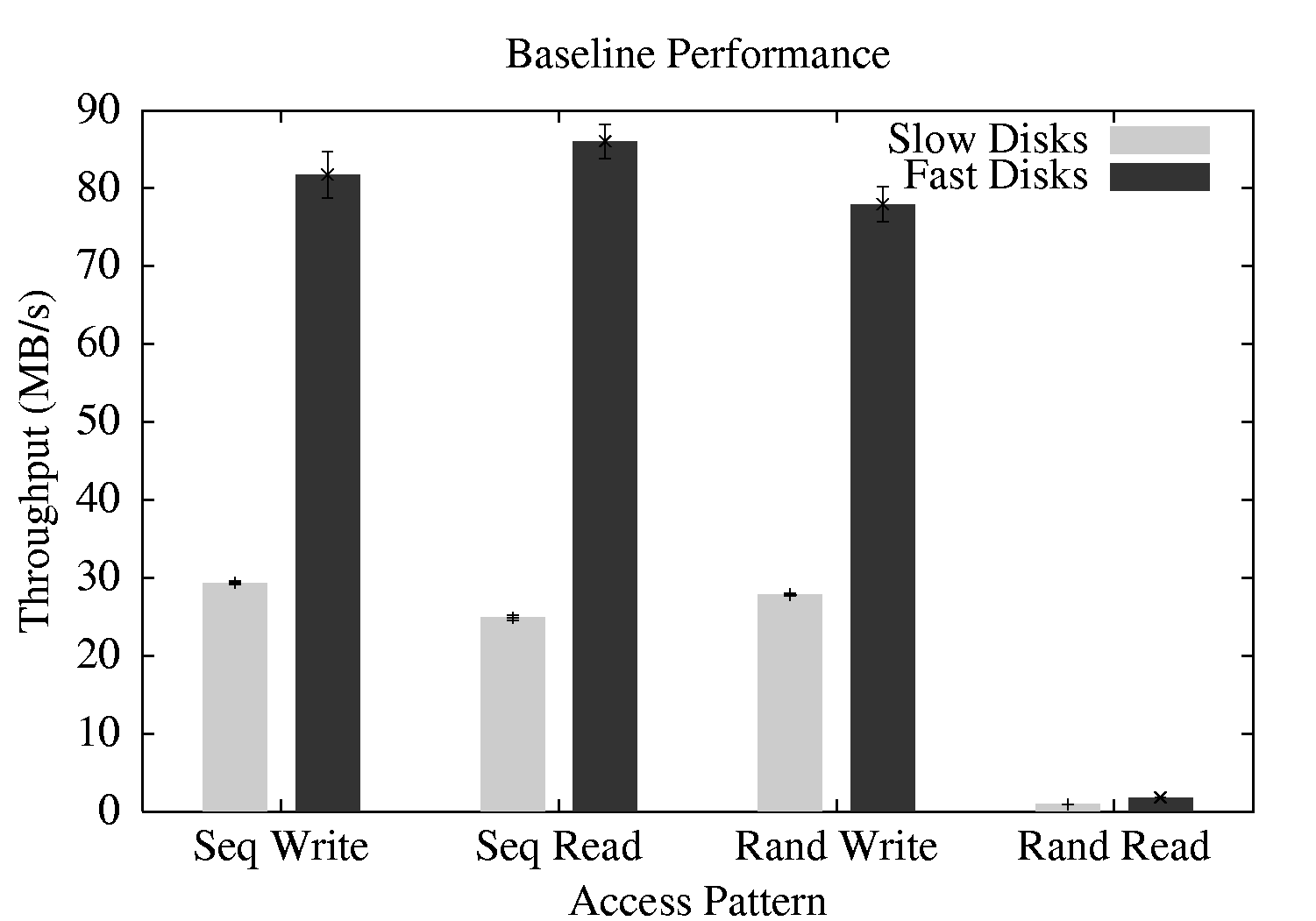 |
As we can see in Figure 3, sequential write, sequential read, and random writes all perform excellently, achieving high bandwidth across both disk configurations. Not surprisingly for a log-based file system, random reads perform much more poorly, achieving roughly 0.9 MB/s on the four slow disks, and 1.8 MB/s on the four fast disks, in line with what one would expect from these disks in a typical RAID configuration.
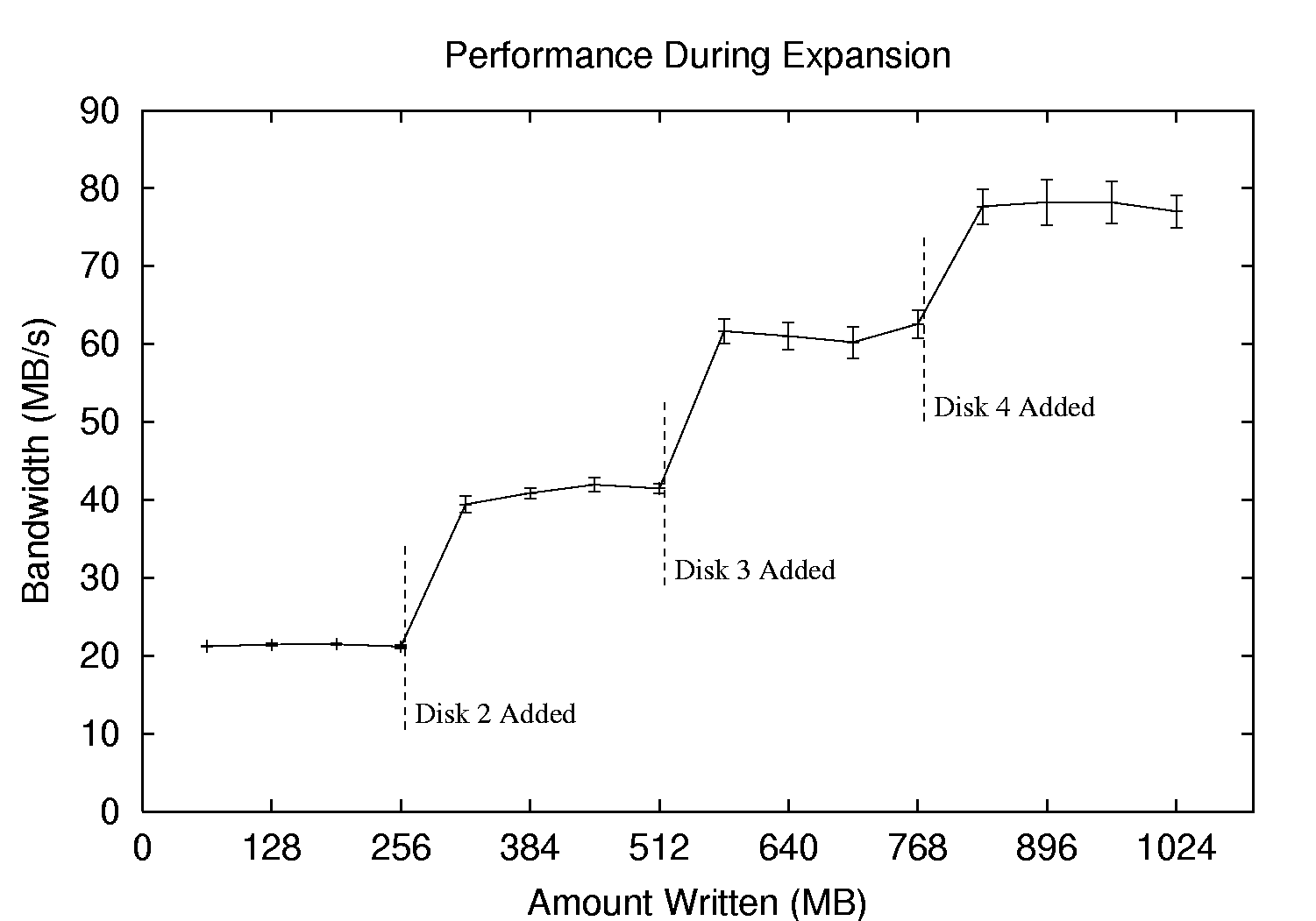
We now demonstrate the performance of the system under writes as disks are added to the system on-line. In this experiment, the disks are already present within the PC, and thus the expansion stresses the software infrastructure and not hardware capabilities.
Figure 4 plots the performance of sequential writes over time as disks are added to the system.1 Along the x-axis, the amount of data written to disk is shown, and the y-axis plots the rate that the most recent 64 MB was committed to disk. As one can see from the graph, I.LFS immediately starts using the disks for write traffic as they are added to the system. However, read traffic will continue to be directed to the original disks for older data. The LFS cleaner could redistribute existing data over the newly-added disks, either explicitly or through cleaning, but we have not yet explored this possibility.
 |
We next explore the ability of I.LFS to place segments dynamically in different regions based on the current performance characteristics of the system, in order to demonstrate the ability of I.LFS to react to static and dynamic performance differences across devices.
There are many reasons for performance variation among drives. For example, when new disks are added, they can likely be faster than older ones; further, unexpected dynamic performance variations due to bad-block remapping or ``hot spots'' in the workload are not uncommon [5], and therefore can also lead to performance heterogeneity across disks. Indeed, the ability to expand the disk system on-line (as shown above) induces a workload imbalance, as read traffic is not directed to the newly-added disks until the cleaner has reorganized data across all of the disks in the system.
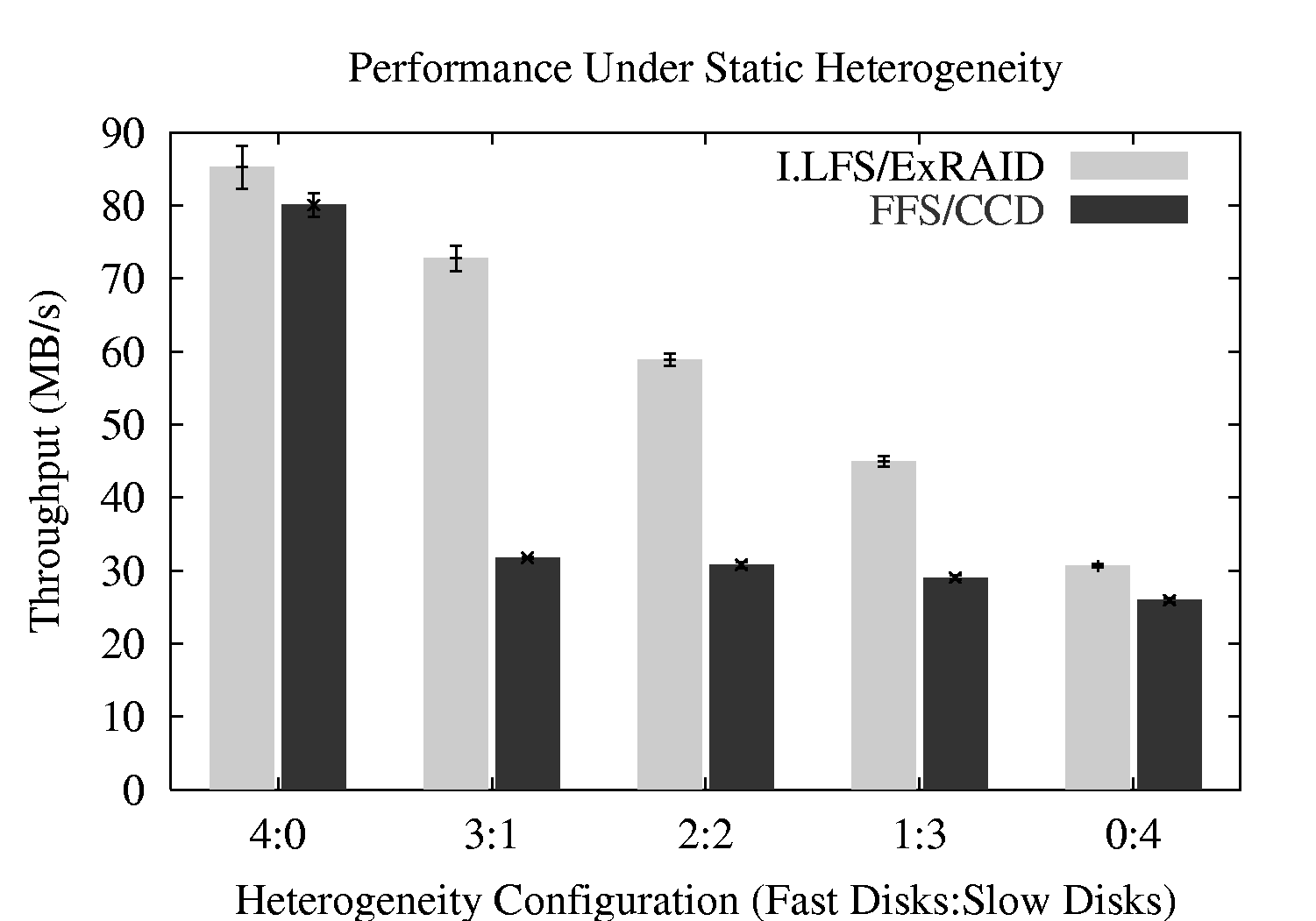
We experiment with both static and dynamic performance variations in this subsection. Figure 5 shows the results of our static heterogeneity test. The sequential write performance of I.LFS with its dynamic segment placement scheme is plotted along with FFS on top of the NetBSD concatenated disk driver (CCD) configured to stripe data in a RAID-0 fashion. In all experiments, data is written to four disks. Along the x-axis, we increase the number of slow disks in the system; thus, at the extreme left, all of the four disks are fast ones, at the right they are all slow ones, and in the middle are different heterogeneous configurations.
 |
 |
As we can see in the figure, by writing segments dynamically in proportion to delivered disk performance, I.LFS/ExRAID is able to deliver the full bandwidth of the underlying storage system to applications - overall performance degrades gracefully as more slow disks replace fast ones in the storage system. RAID-0 striping performs at the rate of the slowest disk, and thus performs poorly in any heterogeneous configuration.
We also perform a ``misconfiguration'' test. In this experiment, we configure the storage system to utilize two partitions on the same disk, emulating a misconfiguration by an administrator (similar in spirit to tests performed by Brown and Patterson [7]). Thus, while the disk system appears to contain four separate disks, it really only contains three. In this case, I.LFS/ExRAID writes data to disk at 65 MB/s, whereas standard striping delivers only 46 MB/s. The dynamic segment striping of I.LFS is successfully able to balance load across the disks, in this case properly assigning less load to each partition within the accidentally over-burdened disk.
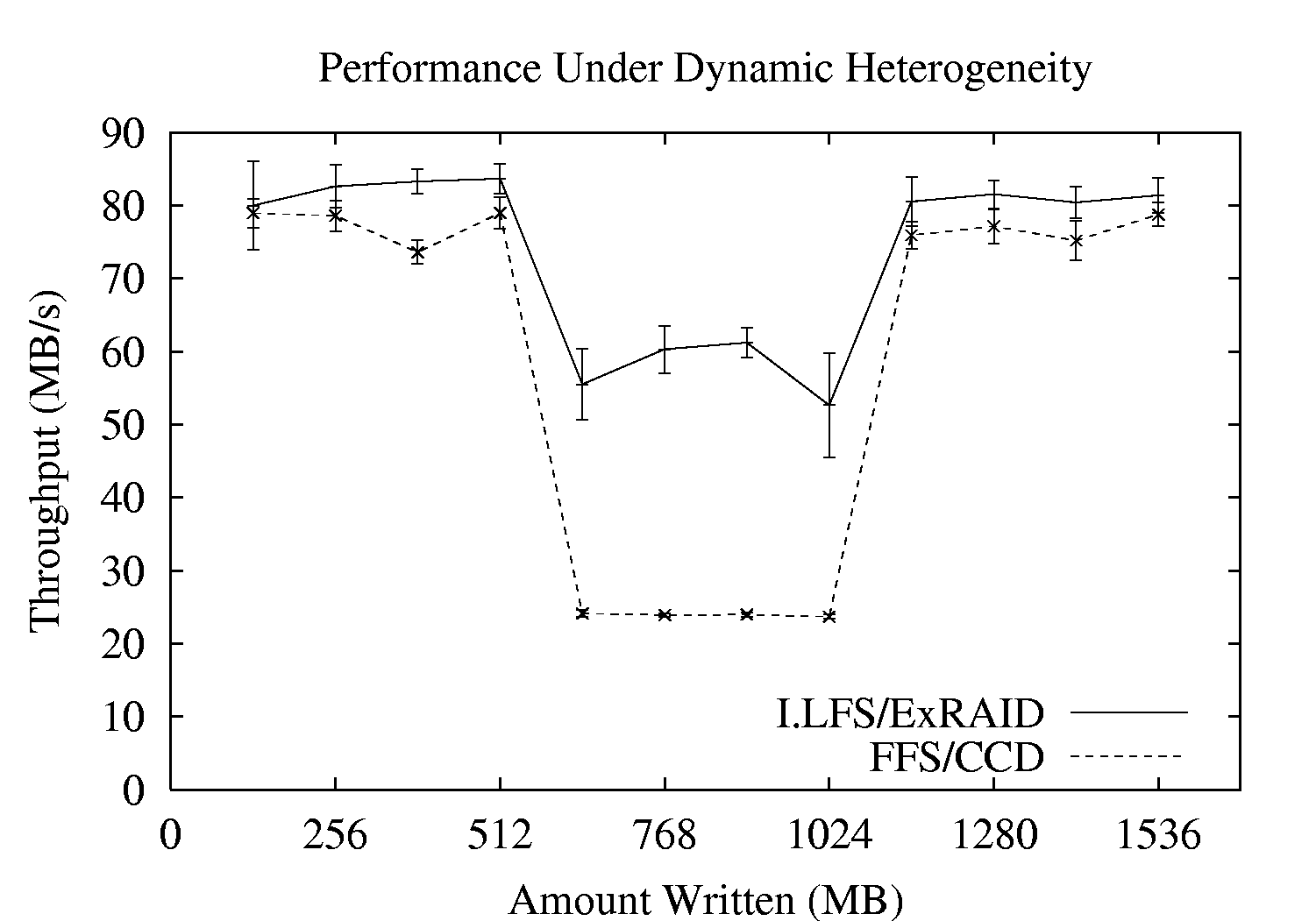
In our final heterogeneity experiment, we introduce an artificial ``performance fault'' into a storage system consisting of four fast disks, in order to confirm that our load balancing works well in the face of dynamic performance variations. Figure 6 shows the performance during a write of both I.LFS/ExRAID with dynamic segment placement and FFS/CCD using RAID-0 striping in a case where a single disk of the four exhibits a performance degradation. After one third of the data is written, a kernel-based utility is used to temporarily delay completed requests from one of the disks. The delay has the effect of reducing its throughput from 21.6 MB/s to 5.8 MB/s. The impaired disk is returned to normal operation after an additional one third of the data is written. As we can see from the figure, I.LFS/ExRAID does a better job of tolerating the fluctuations induced during the second phase of the experiment, improving performance by over a factor of two as compared to FFS/CCD.
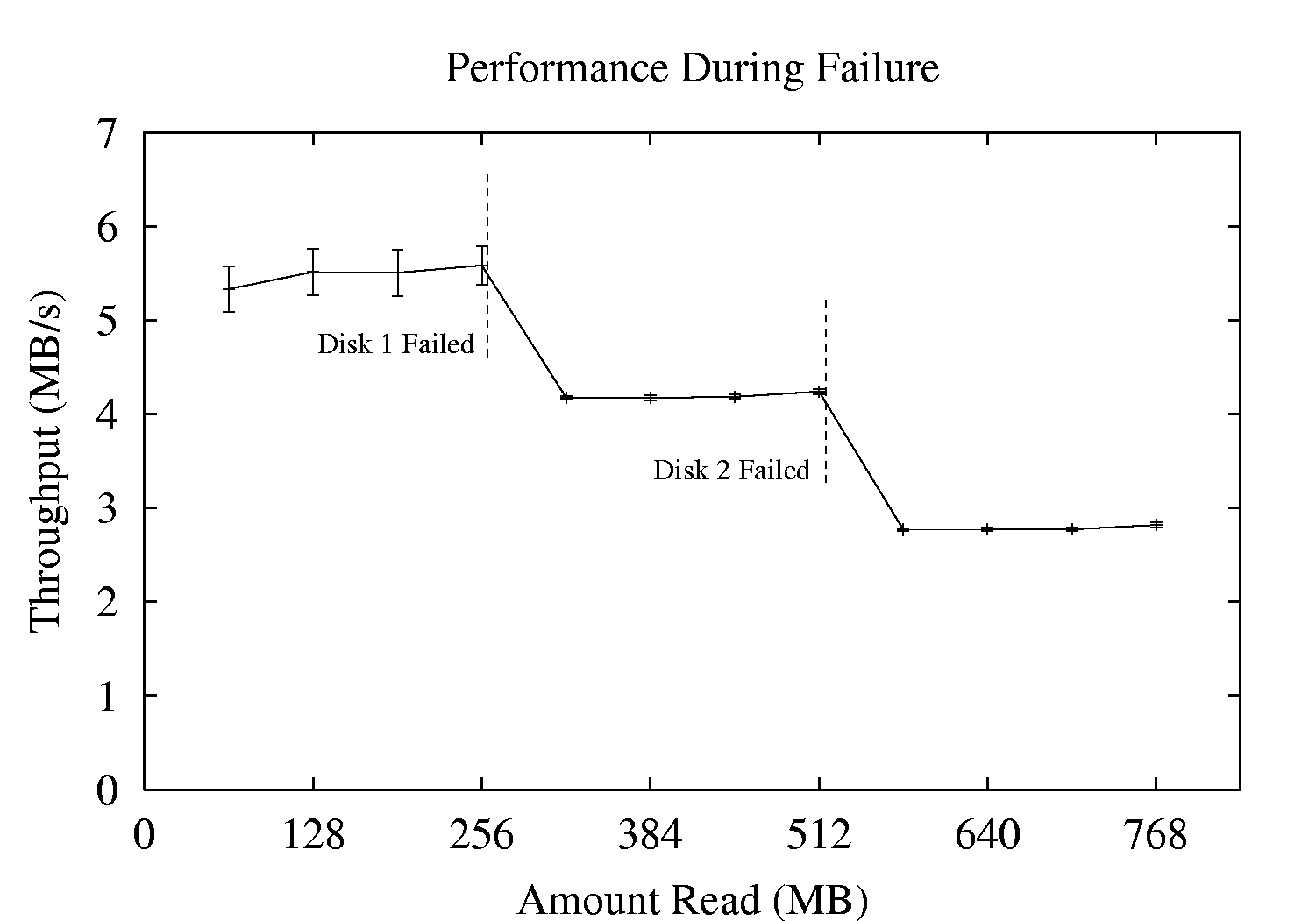
In our first redundancy experiment, we verify the operation of our system in the face of failure. Figure 7 plots the performance of a set of processes performing random reads from redundant files on I.LFS. Initially, the bandwidth of all four disks is utilized by balancing the read load across the mirrored copies of the data. As the experiment progresses, a disk failure is simulated by disabling reads to one of the disks. I.LFS continues providing data from the available replicas, but overall performance is reduced.
 |
Next, we demonstrate the flexibility of per-file redundancy when the redundancy is managed by the file system. A total of 20 files are written concurrently to a system consisting of four fast disks, while the percentage of those files that are mirrored is increased along the x-axis. The results are shown in Figure 8.
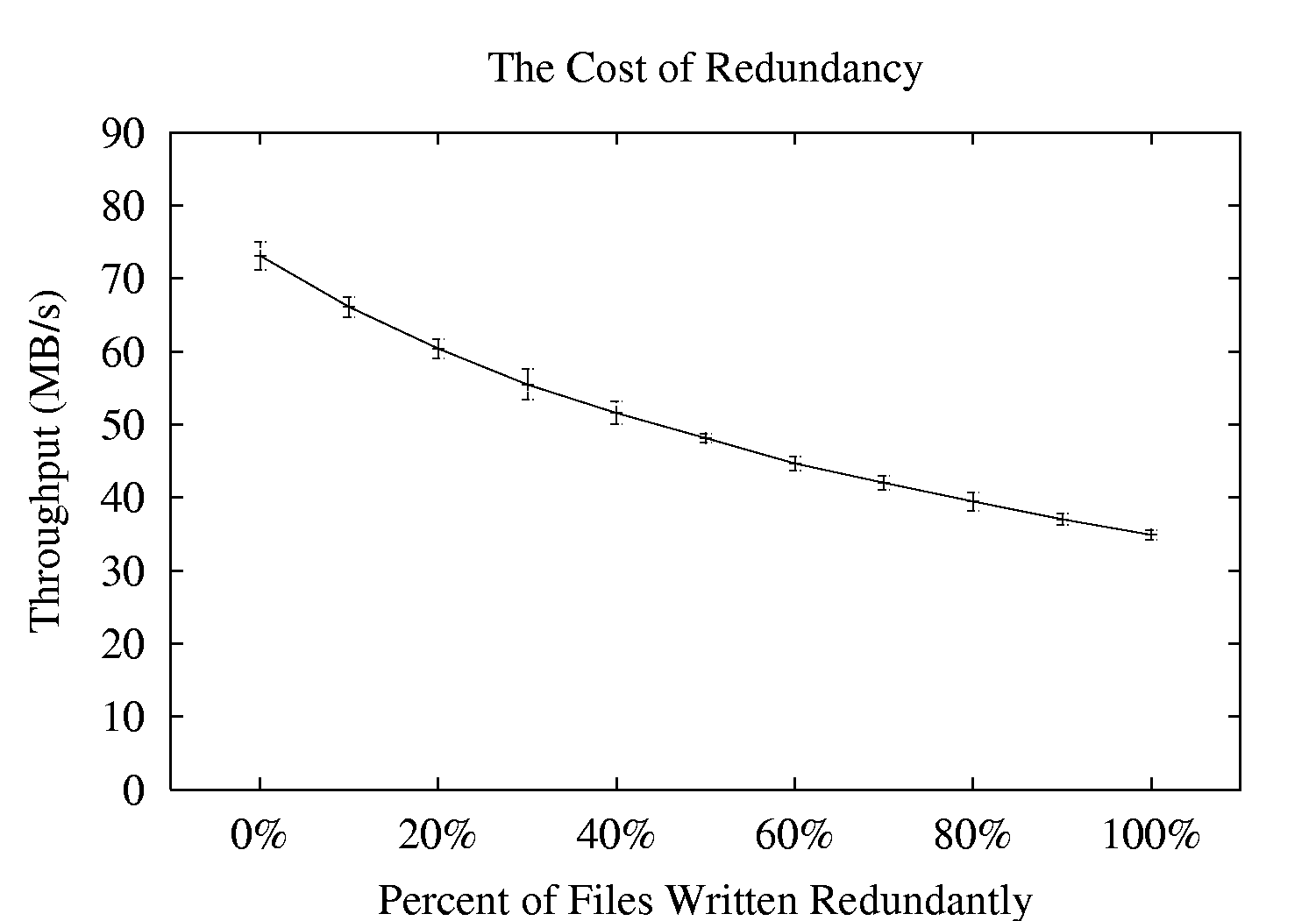 |
As expected, the net throughput of the system decreases linearly as more files are mirrored, and when all are mirrored, overall throughput is roughly halved. Thus, with per-file redundancy, users ``get what they pay for''; if users want a file to be redundant, the performance cost of replication is paid during the write, and if not, the performance of the write reflects the full bandwidth of the underlying disks.
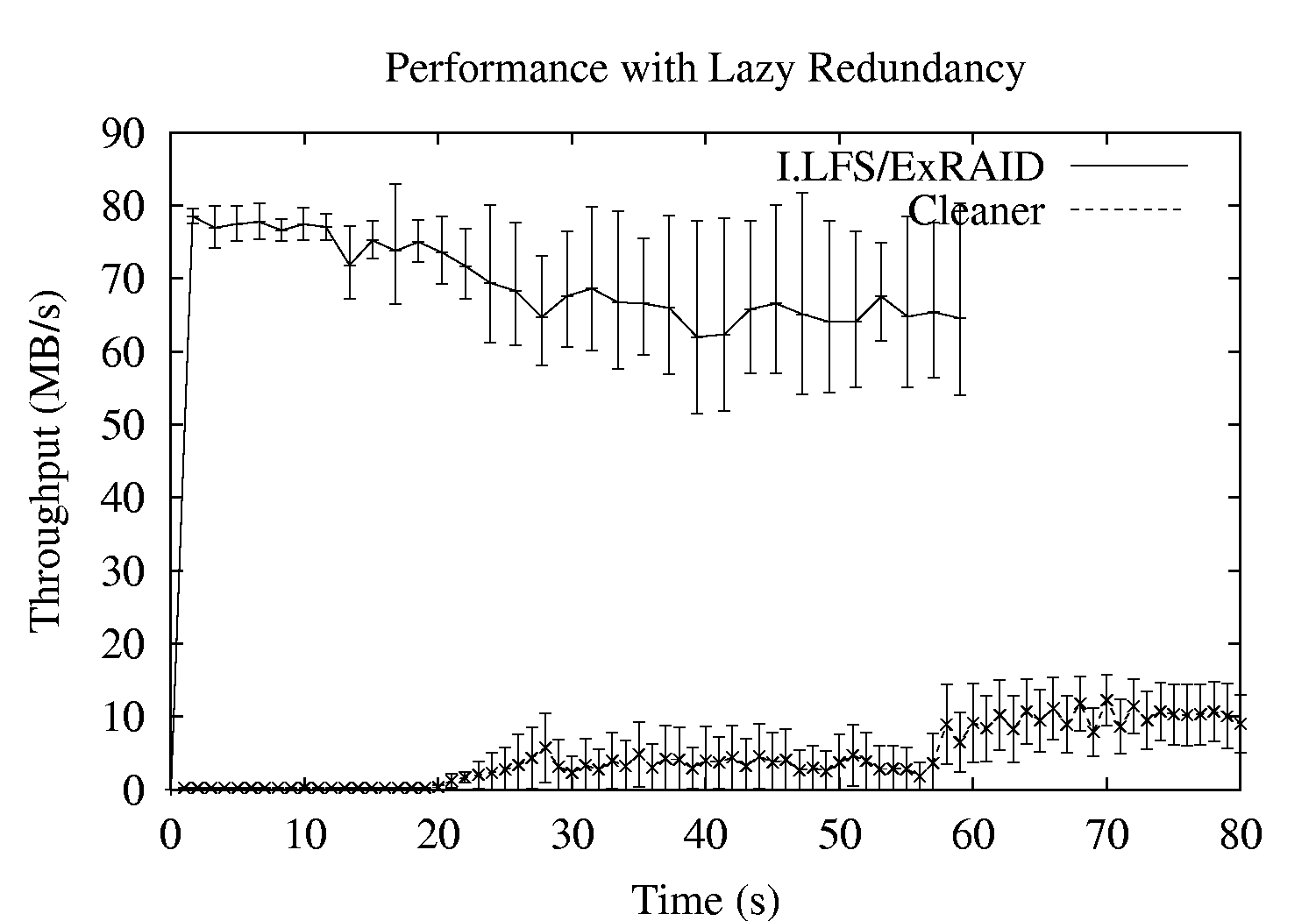
In our final experiment, we demonstrate some of the performance characteristics of lazy mirroring. Figure 9 plots the write performance to a set of lazily mirrored files. After a delay of 20 seconds, the cleaner begins replicating data, and the normal file system traffic suffers from a small decline in performance. The default replication delay for the system is two minutes in length, but an abbreviated delay is used here to reduce the time of the experiments.
From the figure, we can see the potential benefits of lazy mirroring, as well as its potential costs. If lazily mirrored files are indeed deleted before replication begins, the full throughput of the storage layer will be realized. However, if many or all lazily mirrored files are not deleted before replication, the system incurs an extra penalty, as those files must be read back from disk and then replicated, which will affect subsequent file system traffic. Therefore, lazy mirroring should be used carefully, either in systems with highly bursty traffic (i.e., idle time for the lazy replicas to be created), or with files that are easily distinguishable as short-lived.
In implementing I.LFS/ExRAID, we were concerned that by pushing more functionality into the file system, the code would become unmanageably complex. Thus, one of our primary goals is to minimize code complexity. We believe we achieve this goal, integrating the three major pieces of functionality with only an additional 1,500 lines of code, a 19% increase over the original size of the LFS implementation. Of this additional code, roughly half is due to the redundancy management.
From the design standpoint, we find that managing redundancy within the file system has many benefits, but also causes many difficulties. For example, to solve the crossed-pointer problem, we applied a divide-and-conquer technique. By placing the primary copy of a file into one of two sets, and its mirror in the other, we enable fast operation under failure. However, our solution limits data placement flexibility, in that once a file is assigned to a set, any subsequent writes to that file must be written to that set. This limitation affects performance, particularly under heterogeneous configurations where one set has significantly different performance characteristics than the other. Though we can relax these placement restrictions, e.g., by choosing which disks constitute a set on a per-file basis, the problem is fundamental to our approach to file-system management of redundancy.
From the implementation standpoint, file-system managed redundancy is also problematic, in that the vnode layer is designed with a single underlying disk in mind. Though our recursive invocation technique was successful, it stretched the limits of what was possible in the current framework, and new additions or modifications to the code are not always straightforward to implement. To truly support file-system managed redundancy, a redesign of the vnode layer may be beneficial [31].
 |
A number of possible avenues exist for future research. Most generally, we believe more organizations of the storage protocol stack need to be explored. Which pieces of functionality should be implemented where, and what are the trade-offs? One natural follow-on is to incorporate more lower-level information into ExRAID; the main challenge when exposing new information to the file system is to find useful pieces of information that the file system can readily exploit.
Of course, most file service today spans client and server machines. Thus, we believe it is important to consider how functionality should be split across machines. Which portion of the traditional storage protocol stack should reside on clients, and which portion should reside on the servers? Researchers in distributed file systems have taken opposing points of view on this, with systems such as Zebra [15] and xFS [1] letting clients do most of the work, whereas the Frangipani/Petal system places most functionality within the storage servers [21,45].
We also believe cooperative approaches between the file system and storage system may be useful. For example, we found that implementing redundancy in the file system was sometimes vexing; perhaps an approach that shared the responsibility of redundancy across both file system and storage layer would be an improvement. For example, the storage layer could tell the file system which block to use as a mirror of another block, but the file system could decide when to perform the replication.
Even if we decide upon a new storage interface, it may be difficult to convince storage vendors to move away from the tried-and-true standard SCSI interface to storage. Thus, a more pragmatic approach may be to treat the RAID layer as a gray box, inferring its characteristics and then exploiting them in the file system, all without modification of the underlying RAID layer [2]. Tools that automatically extract low-level information from disk drives, such as DIXtrac [35] and SKIPPY [42], are first steps towards this goal, with extensions needed to understand the parallel aspects of storage systems.
Finally, we envision many more possible optimizations in our new arrangement of the storage protocol stack. For example, we are currently exploring the notion of intelligent reconstruction. The basic idea is simple: if a disk (or region) fails, and I.LFS has duplicated the data upon that disk, I.LFS can begin the reconstruction process itself. The key difference is that I.LFS will only reconstruct live data from that disk, and not the entire disk blindly, as a storage system would, substantially lowering the time to perform the operation. A fringe benefit of intelligent reconstruction is that I.LFS should be able to give preference to certain files over others, reconstructing higher-priority files first and thus increasing the availability of those files under failure.
We also imagine that many optimizations are possible with the LFS cleaner. For example, as data is laid out on disk according to current performance characteristics and access patterns, it may not meet the needs of subsequent potentially non-sequential reads from other applications. Similarly, as new disks are added, the cleaner may want to run in order to lay out older data across the new disks. Thus, the cleaner could be used to re-organize data across drives for better read performance in the presence of heterogeneity and new drives, similar to the work of Neefe et al., but generalized to operate in a heterogeneous multi-disk setting [22].
In terms of abstractions, block-level storage systems such as SCSI have been quite successful: disks hide low-level details from file systems such as the exact mechanics of arm movement and head positioning, but still export a simple performance model upon which file systems could optimize. As Lampson said: ``[...] an interface can combine simplicity, flexibility, and high performance together by solving one problem and leaving the rest to the client'' [20]. In early single-disk systems, this balance was struck nearly perfectly.
As storage systems evolved from a single drive into a RAID with multiple disks, the interface remained simple, but the RAID itself did not. The result is a system full of misinformation: the file system no longer has an accurate model of disk behavior, and the now-complex storage system does not have a good understanding of what to expect from the file system.
ExRAID and I.LFS bridge this information gap by design: the presence of multiple regions is exposed directly to the file system, enabling new functionality. In this paper, we have explored the implementation of on-line expansion, dynamic parallelism, flexible redundancy, and lazy mirroring in I.LFS. All were implemented in a relatively straight-forward manner within the file system, increasing system manageability, performance, and functionality, while maintaining a reasonable level of overall system complexity. Some of these aspects of I.LFS would be difficult if not impossible to build in the traditional storage protocol stack, highlighting the importance of implementing functionality in the correct layer of the system.
Though we have chosen a single point in the design space of storage protocol stacks, other arrangements are possible and perhaps even preferable; we hope that they will be explored. Whatever the conclusion of research on the division of labor between file and storage systems, we believe that the proper division should be arrived upon via design, implementation, and thorough experimentation, not via historical artifact.
We would like to thank our shepherd, Elizabeth Shriver, as well as John Bent, Nathan Burnett, Brian Forney, Florentina Popovici, Muthian Sivathanu, and the anonymous reviewers for their excellent feedback.
This work is sponsored by NSF CCR-0092840, CCR-0098274, NGS-0103670, CCR-0133456, ITR-0086044, and the Wisconsin Alumni Research Foundation. Timothy E. Denehy is sponsored by an NDSEG Fellowship from the Department of Defense.
|
This paper was originally published in the
Proceedings of the 2002 USENIX Annual Technical Conference, June 10-15, 2002, Monterey Conference Center, Monterey, California, USA.
Last changed: 16 May 2002 ml |
|