



Next: Load distribution of different
Up: New Analysis
Previous: Temporal Stability
In this section, we consider the following question: do people in the same
geographical region tend to issue a similar set of queries. We employ the same
approach as is used in studying the spatial locality for notification services
(described in Section 4.3.1).
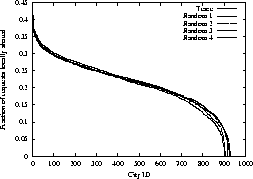
Figure 14 compares the fraction of documents that are
shared within a geographical cluster and within four random clusters, when we
consider requests from all the users (excluding users with invalid IDs). The
figure shows that the curve for the geographical clusters overlaps with those
for random clusters. This overlap indicates that the degree of sharing between
geographical clustering and random clustering is comparable, and the
correlation between users' interest in browsing over wireless channels and
their geographical location is weak.
Figure 14:
Local
sharing between random sets of clients and clients that are geographically
close together.
 |
A possible explanation for the weak correlation is that the popular browse
content has global interest. In particular, as mentioned in
Section 5.1, 0.1% - 0.5% of the URL and parameter
combinations (i.e., about 121 - 442 unique combinations) account for 90% of
the requests. With such a high concentration of user interest on a few
documents, even when clients are picked at random, they share many requests;
therefore, the geographical locality becomes insignificant. A similar
phenomenon has been observed in a study of a popular news server [16],
where the authors observed that the significance of domain membership becomes
diminished during a popular event. A major distinction between that study and
ours is the way in which users are clustered: in that study, users are
clustered based on their DNS names, whereas in our study we cluster users based
on their geographical region, e.g. the city in which they reside.
A natural question follows - why is there such a high concentration of
interest in popular documents that even when clients are picked at random they
share many documents? Examination of the most popular URLs and parameters
shows that they include the front pages for email login, news, sports,
weather, lottery, and the signup application, as well as some popular stock
quote queries. Intuitively, these queries are very popular to all users
regardless of their physical locations.
The lack of geographical locality implies that the web server's content
can be replicated without keeping in mind the geographical location of the clients.
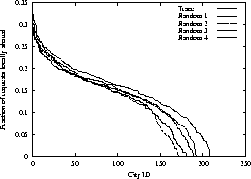
We performed the same spatial locality analysis to requests issued only by
wireless clients. Figure 15 summarizes the
results. With geographical clustering, wireless clients have slightly more
sharing of documents than with random clustering; however, the distinction
between the two clusterings is much less significant than the difference
observed for notification documents. This result suggests that
using geographical locality of wireless users as input for optimizing
performance (or providing content) will yield limited success.
Figure 15:
Comparison
of local sharing between random sets of wireless clients and wireless clients
that are geographically close together.
 |
Next: Load distribution of different
Up: New Analysis
Previous: Temporal Stability
Lili Qiu
2002-04-17