Resource containers[1] encapsulate all the resources consumed by an activity or a group of activities. Resources include CPU time, memory, network bandwidth, disk bandwidth etc. Our focus in this paper has been on CPU time. 4
Scheduling and resource allocation is done via resource containers5. Processes are bound to resource containers to obtain resources. This resource binding between a process and a resource container is dynamic. All the resource consumption of a process is charged to the associated resource container. Multiple processes may simultaneously have their resource bindings set to a given container.
A task starts with a default resource container binding (inherited from its creator). The application can rebind the task to another container as the need arises. For example, a task time-multiplexed between several network connections can change its resource binding as it switches from handling one connection to another, to ensure correct accounting of the resource consumption.
Tasks identify resource containers through file descriptors. The semantics of these descriptors are the same as that of file descriptors: the child inherits the descriptors from the parent, and it can be passed between unrelated processes through the Unix-domain socket file descriptor passing mechanisms. APIs are provided for operations on resource containers. Security is enforced as an application can access only those resource containers that it can reference through its file descriptors.
We have added a new name space corresponding to the resource container: the resource container id, similar to the pid for processes, as it was not possible to access some of the resource containers through the existing APIs (e.g. a container that has no processes directly associated with it). This name space is available to users having the right privilege through the /proc interface.
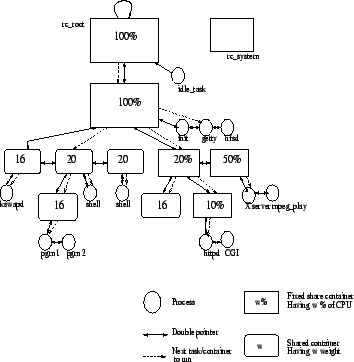
Resource containers form an hierarchy (figure 1). A resource container can have tasks or other resource containers (called child containers) in its scheduler bindings (i.e. the set of schedulable entities). The resource usage of a child container is constrained by the scheduling parameters of its parent container. On the top of the hierarchy is the root container. This encapsulates all the resources available in the system.
Hierarchical resource containers make it possible to control the resource consumption of an entire subsystem without constraining how the subsystem allocates and schedules resources among it various independent activities. This allows a rich set of scheduling policies to be implemented. Our Linux implementation allows the scheduling policies to be changed dynamically through APIs. It also allows these policies to be in dynamically loadable modules. This allows privileged users to try out various scheduling algorithms and to use better ones with a specific application mix.
The CPU resources allocated to a container may be either a fixed share of the resource its parent container is entitled to (called fixed share child container), or it may be shared with other children of the parent (called shared child container). In the case of shared children, the amount of CPU time it is entitled to is proportional to the weight of the container relative to other shared child containers of parent.
Along with fixed and shared child containers, our implementation support multiple scheduling classes. Scheduling classes have strict priorities, i.e. a container in the lower priority class will not be scheduled in the presence of container with a higher priority class.
For scheduling soft real-time processes, we need to attach them to fixed share containers. The CPU reservation of these containers have to be at least the amount of processing required for those processes. Unlike hard real-time scheduling, this will allow other time shared processes to have reasonable progress if the CPU reservation of soft-real time process is not 100%. Higher scheduling classes should be used only when absolutely necessary (eg. hard real-time) as this can possibly make all the processes in the lower class starve.
Our design does not take care of any interrupt live-locks that can occur due to high network activity. It has been shown that LRP[5] gives stable throughput under high load, hence we plan to incorporate it at a later time.