


Next: Language Evaluation
Up: Results with PLAPACK
Previous: Results with PLAPACK
Performance Evaluation
Figure:
Performance comparison of hand-optimized and Broadway-optimized
PLAPACK applications.
cholesky_6x6.eps
=.9in
|
liaponov_6x6.eps
=.9in
|
|
Figure:
Performance comparison of hand-customized and Broadway-customized
PLA_Trsm() function for the Cholesky program. For the Lyapunov
program, the hand-customized PLA_Trsm() function matched the
performance of the Broadway-customized version.
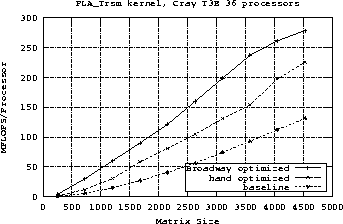 |
Figure:
Scalability of the Cholesky programs as the number of processors
grows.
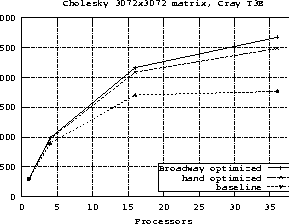 |
Figure ![[*]](icons.gif/cross_ref_motif.gif) shows the performance improvement of the Cholesky
and Lyapunov programs. For fairly large matrices (
shows the performance improvement of the Cholesky
and Lyapunov programs. For fairly large matrices (
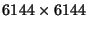 ), the
Broadway-optimized Cholesky program is 26% faster than the baseline and the
hand-optimized program is 22% faster than the baseline. For the Lyapunov
program, the Broadway system does not perform as well as the manual
approach, improving performance by 9.5% compared to the hand-optimized
improvement of 21.5% for
), the
Broadway-optimized Cholesky program is 26% faster than the baseline and the
hand-optimized program is 22% faster than the baseline. For the Lyapunov
program, the Broadway system does not perform as well as the manual
approach, improving performance by 9.5% compared to the hand-optimized
improvement of 21.5% for
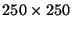 matrices, and improving
performance by 5.8% compared to 6.1% for
matrices, and improving
performance by 5.8% compared to 6.1% for
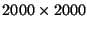 matrices. The two approaches obtain identical performance on the PLA_Trsm()
kernel, but the hand-optimized program performs a few additional
optimizations to other parts of the code.
matrices. The two approaches obtain identical performance on the PLA_Trsm()
kernel, but the hand-optimized program performs a few additional
optimizations to other parts of the code.
Note that there is considerable room for further improving the Lyapunov
program, since PLA_Trsm() only accounts for 11.6% of the execution
time for 250 250 matrices, and only 5.8% of the time for
matrices. When our compiler is complete, we will apply our
optimizations to all parts of the PLAPACK library, including the
PLA_Gemm() routine, where Lyapunov spends a majority of its time.
250 matrices, and only 5.8% of the time for
matrices. When our compiler is complete, we will apply our
optimizations to all parts of the PLAPACK library, including the
PLA_Gemm() routine, where Lyapunov spends a majority of its time.
Since our experiment focuses on the benefits of specializing the PLA_Trsm()
routine, Figure shows the performance difference
between the generic PLA_Trsm() routine and the version that was customized
for Cholesky by our compiler. Notice that we observe similar results for
different numbers of processors. Figure shows how the
performance of the various Cholesky programs scale with the number of
processors.
The results reveal several interesting points.
-
A small effort yields a large benefit because the annotations only contain
library knowledge, while all compilation expertise resides in the Broadway
Compiler. The library annotator supplies the small but critical bits of
information--such as specifying the conditions required to substitute a
specific PLAPACK routine in place of a more general one--while the compiler
analyzes the program, identifies opportunities for transformations, and
manages a number of optimization passes. This separation of concerns is
beneficial because the performance improvements shown in
Figure come from the repeated application of a small
number of transformations.
- Automation is desirable. Both the Cholesky and Lyapunov programs specialize
the same PLAPACK routine, but they do so in slightly different ways because
they invoke it in different contexts.
- An automated approach can apply all optimizations uniformly. There is no
fundamental reason why the hand-optimized Cholesky factorization is not as
efficient as ours, but the manual approach, which is quite invasive, did not
employ one transformation that it could have.
-
The effect of customization is more important for small matrices. For
example, for a
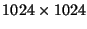 matrix, the Broadway-optimized Cholesky
factorization is 2.95 times faster than the base, and the hand-optimized is
2.47 times faster than the base. When matrices are small the improvements
are larger because there is more overhead relative to matrix operations.
Because dense linear algebra problems do not typically involve huge
matrices, the small matrix cases is important for scaling to larger
numbers of processors, and for supporting sparse matrix operations.
matrix, the Broadway-optimized Cholesky
factorization is 2.95 times faster than the base, and the hand-optimized is
2.47 times faster than the base. When matrices are small the improvements
are larger because there is more overhead relative to matrix operations.
Because dense linear algebra problems do not typically involve huge
matrices, the small matrix cases is important for scaling to larger
numbers of processors, and for supporting sparse matrix operations.
Closer examination of the Cholesky results reveal that specialization and
dead code elimination account for almost all of the performance benefits,
while high level copy propagation (where the copy operations are library
routines) contributes insignificantly.
Next: Language Evaluation
Up: Results with PLAPACK
Previous: Results with PLAPACK
Samuel Z. Guyer
1999-08-25