


Next: mutual exclusion.
Up: 4. Memory bandwidth and
Previous: continuous datas.
The Intel P6 family use a cache coherency protocol with four states usually
called MESI10. This protocol is write invalidate which means that when two or
more processors holds a copy of the same memory line if one of them
writes in, the cache line holding the memory line is
invalidated on other processors. False sharing occur when processors write to
a shared cache line but not at the same location: there is no real coherency
problem since processors write to different location and since the cache allocate a line when a write
misses11 the protocol makes each processor invalidate the other forcing reload of
a cache line at each write. This situation occurs with blasth library at the
boundary of results blocks but in the case of level 1 BLAS only one cache line
will be shared between 2 processors. In the case of dgemm for a m x n
matrix up to max(m,n) caches lines can be shared but usual optimization of
dgemm use block copy of the resulting matrix avoiding such situation. False sharing is
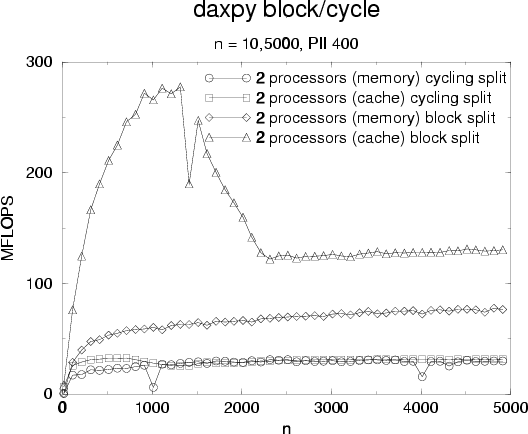
another argument to avoid cycling split and we can see effect
on daxpy in figure ![[*]](cross_ref_motif.png) : there is no cache effect on
operand y while operand x is accessed by each thread with an increment of 2.
: there is no cache effect on
operand y while operand x is accessed by each thread with an increment of 2.
Figure:
Effects of false sharing with daxpy on 2 processors
 |
Next: mutual exclusion.
Up: 4. Memory bandwidth and
Previous: continuous datas.
Thomas Guignon
2000-08-24