Taoyu Li![]()
![]() Minghua Chen
Minghua Chen![]() Dah-Ming Chiu
Dah-Ming Chiu![]() Maoke Chen
Maoke Chen![]()
![]() Tsinghua University, Beijing, China. {taoyu,cmk}@ns.6test.edu.cn
Tsinghua University, Beijing, China. {taoyu,cmk}@ns.6test.edu.cn
![]() The Chinese University of Hong Kong, Shatin, Hong Kong. {tyli,minghua,dmchiu}@ie.cuhk.edu.hk
The Chinese University of Hong Kong, Shatin, Hong Kong. {tyli,minghua,dmchiu}@ie.cuhk.edu.hk
![[*]](footnote.png)
Classical queueing theory models systems where jobs arrive randomly at static service stations of given service capacities, and provides analysis of the system's properties, such as waiting time and stability. Queueing theory has wide application in many scenarios of operations research. In particular, its application in studying computer networks and operating systems led to a generalization of queueing theory to model a network of queues and many different service policies [1,2].
Recently, the modeling of peer-to-peer (P2P) systems is pointing to a new kind of queueing system not studied before. In this new model, jobs still arrive randomly, but the service stations also arrive randomly, possibly correlated to the arrival of jobs. Like classical queueing theory, this new kind of model can also help answer some fundamental questions in the design of (P2P) systems. For example, what are the necessary or sufficient conditions to guarantee the stability of a P2P system? And what would be the performance for a given workload and service parameters?
One of the first dynamic P2P models was introduced by Qiu and Srikant [3] to model BitTorrent, a P2P file sharing system. The model is simple, but very inspiring. Although they did not mention queueing theory, they implicitly modeled randomly arriving service stations (which are peers themselves) providing an effective service (file sharing) rate. Subsequently, Fan, Chiu and Lui [4] modeled and studied the tradeoff between different service rate allocations in a dynamic P2P system similar to the Qiu-Srikant model. Clevenot, Nain and Ross [5] generalized the Qiu-Srikant model fluid model to describe more realistic cases. The authors in [6] and [7] also used randomly arriving peers with certain service rate to model P2P streaming systems. There are many other examples of dynamic P2P system models, yet there has not been a unifying analysis in terms of an generalized queueing theory.
In this paper, we first develop a taxonomy and a family of notations similar to that in [1] for different variations of queueing models with server dynamics (Section II). For several basic classes of these systems, we derive the stability conditions and compare them to those results in the classical queueing theory (Section III). Next, to demonstrate the application of a P2P queueing model to real systems, we study a P2P storage system known as Wuala [8] (Section IV). We present some numerical simulation results in Section V, and conclude the work in Section VI.
| Notation | Definition |
|---|---|
| A | job arrival process. |
| B | job service time distribution. |
| s | number of servers (used in traditional queuing model). |
| C | server arrival process. |
| E | server life time distribution. |
| POLICY | the service policy assumed. |
|
|
average interarrival time between two job arrivals. |
| average job service time. | |
|
|
job load demand of the system. |
|
|
average interarrival time between two server arrivals. |
| average server life time. | |
|
|
service capacity of the system. |
| the number of jobs in the system at time |
|
| the number of servers in the system at time |
In classical queuing theory, Kendall's
notation [1], i.e.,
A![]() B
B![]() s
s![]() POLICY
, is widely used to
represent queuing model for static service systems where servers are
static.
POLICY
, is widely used to
represent queuing model for static service systems where servers are
static.
To represent new queuing models for P2P service systems in which both job and server dynamically arrive and depart, we use the following notation
To represent systems with different job and server dynamics, some
notations we use for arrival processes (A or C) and distributions (B
or E) are 1) ![]() for a Memoryless process (e.g. Poisson process), or
an exponential distribution. 2)
for a Memoryless process (e.g. Poisson process), or
an exponential distribution. 2) ![]() for a
deterministic process, or a deterministic distribution. 3)
for a
deterministic process, or a deterministic distribution. 3) ![]() for a
process with general independent arrivals, or arbitrary
distribution.
for a
process with general independent arrivals, or arbitrary
distribution.
Notice that for ![]() or
or ![]() , it may be the case that server arrival
and lifetime distribution has correlation with job arrival and job
service time distribution. We use notation `
, it may be the case that server arrival
and lifetime distribution has correlation with job arrival and job
service time distribution. We use notation `![]() ' for
' for ![]() or
or ![]() in
the case that server arrival and lifetime distribution is identical
to the job arrival and job service time distribution. We use
notation
in
the case that server arrival and lifetime distribution is identical
to the job arrival and job service time distribution. We use
notation ![]() for
for ![]() in the case that server lifetime equals to
the summation of job service time and an extra period of time
following exponential or arbitrary distribution, respectively.
in the case that server lifetime equals to
the summation of job service time and an extra period of time
following exponential or arbitrary distribution, respectively.
Similarly, notations we use for service policy (POLICY) include 1)
![]() (First-Come-First-Served), which means jobs are served in
their arrival order, each by all the servers currently in the
system. 2)
(First-Come-First-Served), which means jobs are served in
their arrival order, each by all the servers currently in the
system. 2) ![]() (
(![]() -Processor-Sharing), which means all jobs in
the system are served, each by no more than
-Processor-Sharing), which means all jobs in
the system are served, each by no more than ![]() servers
simultaneously. In real systems, this constraint is often due to
downlink capacity limitation of end users. Furthermore, we assume
the job-server allocation is efficient so that the number of busy
servers (also the total service capacity, since each server has a
unit service capacity) at time
servers
simultaneously. In real systems, this constraint is often due to
downlink capacity limitation of end users. Furthermore, we assume
the job-server allocation is efficient so that the number of busy
servers (also the total service capacity, since each server has a
unit service capacity) at time ![]() is exactly the maximum allowed
value
is exactly the maximum allowed
value
![]() .
.
We discuss several classes of P2P service systems as follows.
Note that if the Markov process
![]() is stable, then not only it has a stationary distribution, but
also the states
is stable, then not only it has a stationary distribution, but
also the states
![]() , will be visited within
finite amount of time. Practically, this means that all arriving
jobs will be served and cleared by the P2P service system in finite
time.
, will be visited within
finite amount of time. Practically, this means that all arriving
jobs will be served and cleared by the P2P service system in finite
time.
The job-server process
![]() of this type of
systems is a two-dimension birth-death process with infinite states.
Its transition rate is given in Table II. Since at
any time
of this type of
systems is a two-dimension birth-death process with infinite states.
Its transition rate is given in Table II. Since at
any time ![]() one job is served by
one job is served by ![]() servers, the job
departure rate is
servers, the job
departure rate is
![]() , as shown in the third row in
Table II. The server dynamics, on the other hand,
does not depend on the number of jobs in the system, and can be
studied by an
, as shown in the third row in
Table II. The server dynamics, on the other hand,
does not depend on the number of jobs in the system, and can be
studied by an
![]() queue.
queue.
A routine way to derive the stability condition is to solve the balance equations. However, for the above process, applying this approach involves solving infinite number of balance equations, each having four unknown variables. Observing that the approach is very challenging, we thus re-interpret the job-server process as a quasi-birth-death (QBD) one and proceed with a matrix-analytical method.
It is not difficult to verify that a
![]() system is a
homogeneous QBD process, and its transition matrix, denoted by
system is a
homogeneous QBD process, and its transition matrix, denoted by
![]() , is given by:
, is given by:
The stability condition of a homogeneous QBD process is given in [9] as follows.
| (6) |
Using Lemma 3, we derive the stability condition for
![]() systems and summarize it in the following theorem.
systems and summarize it in the following theorem.
![$\displaystyle P = \left[\begin{array}{ccccc}
-\lambda_{s} & \lambda_{s}\\
\mu_...
...2\mu_{s} & \lambda_{s}\\
& & \ddots & \ddots & \ddots\\
\end{array}\right].
$](img90.png)
It is not difficult to verify
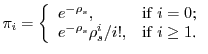
The average queue length in the stationary state is
Since
![]() diag
diag![]() , we have
, we have
![]() .
With
.
With
![]() diag
diag![]() , we can derive
, we can derive
![]() .
.
Combining above observations and applying Lemma 3, we conclude that
![]() is the stability condition for
is the stability condition for
![]() systems.
systems.
![]()
Remarks: Recall the server dynamics of this type of
systems can be modeled by a
![]() queue. In stationary state,
the average service capacity, i.e. the average number of servers, is
queue. In stationary state,
the average service capacity, i.e. the average number of servers, is
![]() . Therefore, Theorem 4 states that a
. Therefore, Theorem 4 states that a
![]() P2P service system is stable if and only if the
average workload
P2P service system is stable if and only if the
average workload ![]() does not exceed the average service
capacity
does not exceed the average service
capacity ![]() . This result is consistent with stability
conditions of classical static service systems, e.g.
. This result is consistent with stability
conditions of classical static service systems, e.g. ![]() for
for
![]() systems and
systems and ![]() for
for ![]() systems.
systems.
It is not difficult to verify that an
![]() system is a
non-homogeneous QBD, and its transition matrix
system is a
non-homogeneous QBD, and its transition matrix ![]() is given by
is given by
By building a series of homogeneous QBD and applying
Lemma 3, we have the stability condition for
![]() systems as follows.
systems as follows.
We now show the sufficiency of the condition.
We first construct two series of QBD processes, whose transition matrices are given as: for all ![]() ,
,
![$\displaystyle Q^{(i)}=\left[
\begin{array}{cccccccc}
V & P_0 & & & \\
P_2^{...
...^{(i)} & P_0 \\
& & & & & \ddots& \ddots & \ddots \\
\end{array} \right],
$](img115.png)
and
![$\displaystyle Q'^{(i)}=\left[
\begin{array}{ccccc}
V & P_0 & & & \\
P_2^{(i...
...& & P_2^{(i)} & \ddots & \ddots \\
& & & \ddots & \\
\end{array} \right],
$](img116.png)
respectively.
For any ![]() , the two QBD processes associated with
, the two QBD processes associated with ![]() and
and ![]() respectively will have the same
stability since their transition rates are only different in the first finite levels. Since the QBD processes associated with
respectively will have the same
stability since their transition rates are only different in the first finite levels. Since the QBD processes associated with
![]() are homogeneous, their stability
conditions are simply
are homogeneous, their stability
conditions are simply
![]() according to Lemma 3, where
according to Lemma 3, where
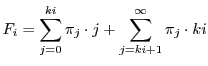
is a constant depending on the stationary distribution
Notice that sequence ![]() is increasing and has a limit of
is increasing and has a limit of
![]() . Thus if we have
. Thus if we have
![]() , there must exists a
, there must exists a ![]() that
that
![]() .
Therefore the QBD process associated with
.
Therefore the QBD process associated with ![]() is stable, and
so is the QBD process associated with
is stable, and
so is the QBD process associated with ![]() .
.
Now we compare ![]() and
and ![]() given in (8).
Observing the departure rate in
given in (8).
Observing the departure rate in ![]() is larger than or equals to that
in
is larger than or equals to that
in ![]() for every state, we conclude the job-server process
associated with
for every state, we conclude the job-server process
associated with ![]() is stable. This completes the proof of
sufficiency.
is stable. This completes the proof of
sufficiency.
![]()
Remarks: Theorem 5 states
that for ![]() systems, using
systems, using ![]() or
or ![]() policy leads
to the same stability condition. Intuitively, this is because these
two policies both allow full utilization of the system service
capacity when the number of jobs is large (i.e. when the system is
crowded), and differ only when the number of jobs is small. Since
the stability is determined by the service capacity utilization when
the system is crowded, it is not surprising that these two policies
leads to the same stability condition.
policy leads
to the same stability condition. Intuitively, this is because these
two policies both allow full utilization of the system service
capacity when the number of jobs is large (i.e. when the system is
crowded), and differ only when the number of jobs is small. Since
the stability is determined by the service capacity utilization when
the system is crowded, it is not surprising that these two policies
leads to the same stability condition.
In ![]() systems, every job arrival (departure) also brings
in (takes away) a server. So it is sufficient to describe only the
job dynamics to represent the entire system.
systems, every job arrival (departure) also brings
in (takes away) a server. So it is sufficient to describe only the
job dynamics to represent the entire system.
The job process
![]() is a one-dimension birth-death
process with transition rate given in Table IV, which is
exactly same with the job process associated with a classical
is a one-dimension birth-death
process with transition rate given in Table IV, which is
exactly same with the job process associated with a classical
![]() system.
Since
system.
Since
![]() systems are always stable, so are
systems are always stable, so are ![]() systems.
systems.
For
![]() systems, since peers may stay in the system for a while to serve others after its job has been finished,
the total number of servers would always be larger than the total number of jobs.
systems, since peers may stay in the system for a while to serve others after its job has been finished,
the total number of servers would always be larger than the total number of jobs.
In practical P2P file downloading systems, this result indicates that as long as every joining peer brings in some service capability with it, the system is always stable.
Let us consider Wuala [8] as an example of a P2P storage system. Wuala allows users to store and share files online. Instead of relying purely on centralized (and deployed) servers, Wuala relies on peers to contribute their disk space to help provide the service. These peers may be users of the system or may be pure storage sellers who only contribute to (without using) the service. For the purpose of this modeling exercise, we assume the requests for files are independent from the peers providing the storage, who are referred to as storage peers.
To store a file into the system, Wuala encrypts it, erasure codes it into fragments, and stored the coded fragments at different storage peers. To retrieve a file from the system, Wuala first locates the fragments using a distributed hash table (DHT), then downloads fragments from multiple storage peers simultaneously. After sufficient fragments are downloaded, the file can be decoded and restored. This approach not only saves the deployment (and maintenance) costs of centralized servers, but can also provide better download rate for users, since it utilizes the upload bandwidth of multiple peers instead of sharing the upload bandwidth of a centralized server.
In studying the performance of systems based on centralized servers, we may apply classical queueing theory to determine the number of servers needed to support a certain workload. For a P2P storage system such as Wuala, there is a corresponding question of what type of online behavior of the storage peers is necessary to ensure the download request rates can be satisfied, which is exactly the kind of questions that can be addressed by the P2P queueing model proposed in Section II.
| Notation | Definition |
|---|---|
|
|
average online time of a storage peer. |
|
|
average offline time of a storage peer. |
| upload bandwidth of each storage peer. | |
| download bandwidth of each downloading peer. | |
| average file length in the system. | |
| file download request arrival rate. |
In modeling Wuala as a queueing system, we assume the availability of the file is not an issue, as it can be taken care of by sufficient redundancy. The key performance problem would be whether there is sufficient bandwidth to support the download requests.
The key parameters used in modeling a P2P storage system are listed in Table V.
If we assume server online/offline time and file length to follow
exponential distributions, and the arrival of file download requests
to follow a Poisson process, then such a P2P storage system can be
modeled by an
![]() model, where
model, where
| (11) | |||
| (12) | |||
| (13) |
Applying Theorem 5,
we know that stability
does not depend on ![]() , and the stability condition
, and the stability condition
![]() reduces to
reduces to
The left hand side represents the total supply (of uplink bandwidth) whereas the right hand side represents the total demand of downloading requests. The insight from this result is the relationship between storage peers' online/offline time ratio and the system's capacity. The online behavior of storage peers can be adjusted by the policy for rewarding them, thus the system capacity could be controlled.
In the next section we show some simulation results which may give more insights on building P2P storage systems.
In this section, we run numerical experiments to verify the stability conditions we
derive in Section III for different types of
systems, and explore other system performance metrics. The value of time and parameter
![]() and
and ![]() are normalized so we omit the unit of them when showing the results.
are normalized so we omit the unit of them when showing the results.
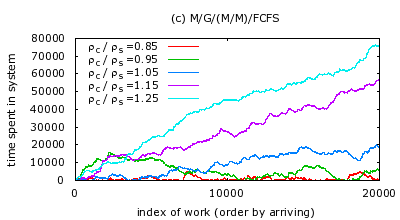
We also evaluate the stability of a system with general service time
distribution, i.e. an
![]() system. We use a service time
distribution which is converted from a file size distribution
measured from practical P2P file sharing system[10].
system. We use a service time
distribution which is converted from a file size distribution
measured from practical P2P file sharing system[10].
We fix
![]() ,
,
![]() and
and
![]() , adjust
, adjust
![]() so that
so that
![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
and
,
and ![]() respectively, and the result is shown in
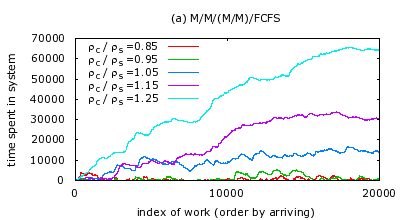
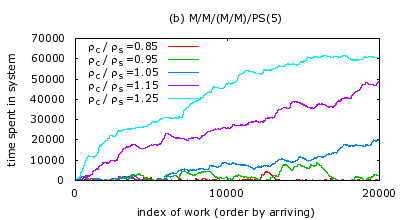
Fig.1. From the result, it can be inferred that when
respectively, and the result is shown in
Fig.1. From the result, it can be inferred that when
![]() , the total time a job spends in the system is
bounded. However, if
, the total time a job spends in the system is
bounded. However, if
![]() , the time a job spends in the
system has a trend of increasing unboundedly by time. This verifies
that the stability condition
, the time a job spends in the
system has a trend of increasing unboundedly by time. This verifies
that the stability condition
![]() holds for
holds for
![]() and
and
![]() systems, as well as for
systems, as well as for
![]() systems.
systems.
It would be interesting to compare the performance of P2P service
systems with same average service capacity (i.e. same ![]() ) but
different server dynamics (i.e. different
) but
different server dynamics (i.e. different ![]() and
and ![]() ).
).
In this experiment, we fix ![]() , and adjust the value of
, and adjust the value of
![]() and
and ![]() proportionally to form several systems with
different server dynamics. All systems have the same
proportionally to form several systems with
different server dynamics. All systems have the same ![]() and
and
![]() ; hence, they have the same average workload.
; hence, they have the same average workload.
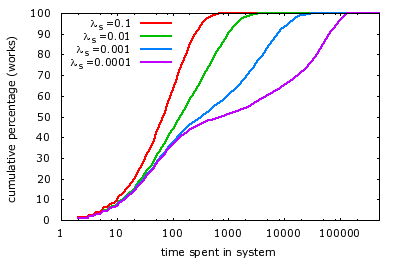
We simulate the systems with ![]() job arrivals, and record the
cumulative percentage of time a job spends in the system. The
initial value of
job arrivals, and record the
cumulative percentage of time a job spends in the system. The
initial value of ![]() and
and ![]() is 0
and
is 0
and ![]() , respectively.
The results of
, respectively.
The results of ![]() equal to
equal to ![]() ,
, ![]() ,
, ![]() and
and
![]() are shown in Fig.2. The average and
standard deviation of the time a job spends in different systems are
summarized in Table VI.
are shown in Fig.2. The average and
standard deviation of the time a job spends in different systems are
summarized in Table VI.
These results indicate that with fixed average service capacity, a
job would spend less time in systems with high server dynamics than
in systems with low server dynamics, averagely. To explain this, we
first define the system is in ``surplus stage'' if the service
capacity is no less than workload ![]() , and is in ``deficiency
stage'' otherwise. Compared to high server dynamics, low server
dynamics lead to longer stay in a stage each time the system enters
it but less frequent switches between stages.
, and is in ``deficiency
stage'' otherwise. Compared to high server dynamics, low server
dynamics lead to longer stay in a stage each time the system enters
it but less frequent switches between stages.
In a system with low server dynamics, the queue builds up when the system is in ``deficiency stage'' before it gets clear after the system switches to ``surplus stage''. Thus the queued-up jobs spend longer time in the system. On the contrary, in a system with high server dynamics, the switching between stages is more frequent. Consequently, less jobs get queued up in the ``deficiency stage'' before the system switches stage, resulting in less time in the system in average.
Consider the P2P storage system we modeled in
Section IV. Remembering that we have
![]() and
and
![]() , the
simulation result indicates that, a system in which servers get
online/offline more frequently would have a better performance, by shorter average file downloading time.
, the
simulation result indicates that, a system in which servers get
online/offline more frequently would have a better performance, by shorter average file downloading time.
For ![]() models where job and server dynamics are identical,
we show that the system is always stable. This confirms the
observations in practical P2P streaming systems.
models where job and server dynamics are identical,
we show that the system is always stable. This confirms the
observations in practical P2P streaming systems.
For ![]() models where job and server arrive independently, we
show that the system is stable if its average service capacity is
larger than the average workload. This stability condition is
similar to that of static service systems. The limitation of that a
single job can get service from only limited number of servers has
no effect on this stability condition.
models where job and server arrive independently, we
show that the system is stable if its average service capacity is
larger than the average workload. This stability condition is
similar to that of static service systems. The limitation of that a
single job can get service from only limited number of servers has
no effect on this stability condition.
As shown in our numerical experiments, the service dynamics in the P2P service systems helps to reduce the time a job spends in the system. We plan to further characterize this effect in future work.
Since this paper is an exordial study of applying queueing
model to P2P systems, we believe that there is lots of possible
further work in the area. Future work directions includes study of
![]() systems with general service time distribution, system
with different classes of service policy, system with different type
of job/server correlation, and system with heterogeneous servers.
It would also be interesting to derive more analytical results than just stability.
An example would be average queue length.
Applying Little's
Law[1], the study on average queue length
would obtain the result on average service time, which may give us
more insight on the performance of P2P systems.
systems with general service time distribution, system
with different classes of service policy, system with different type
of job/server correlation, and system with heterogeneous servers.
It would also be interesting to derive more analytical results than just stability.
An example would be average queue length.
Applying Little's
Law[1], the study on average queue length
would obtain the result on average service time, which may give us
more insight on the performance of P2P systems.
This document was generated using the LaTeX2HTML translator Version 2008 (1.71)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -split 0 -show_section_numbers -local_icons -no_navigation p2pqueuing.tex
The translation was initiated by 3P1C on 2009-03-25

![$\displaystyle Q_A=\left[ \begin{array}{ccccc} V & P_0 & & & \ P_2 & P_1 & P_0 ...
...1 & P_0 & \ & & P_2 & \ddots & \ddots \ & & & \ddots & \ \end{array} \right]$](img66.png)
![$\displaystyle \left[
\begin{array}{ccccc}
-\lambda_s & \lambda_s & & & \\
\...
...& & & m\cdot\mu_s & -\lambda_c-m\cdot\mu_c-m\cdot\mu_s\\
\end{array} \right],$](img77.png)
![$\displaystyle +\left[
\begin{array}{ccccc}
-\lambda_s & \lambda_s & & & \\
...
...& & & m\cdot\mu_s & -\lambda_c-m\cdot\mu_c-m\cdot\mu_s\\
\end{array} \right].$](img80.png)
![$\displaystyle Q_B=\left[ \begin{array}{ccccc} V & P_0 & & & \ P_2^{(1)} & P_1^...
...0 & \ & & P_2^{(3)} & \ddots & \ddots \ & & & \ddots & \ \end{array} \right]$](img103.png)