| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
VM '04 Paper
[VM '04 Technical Program]
A Virtual Machine Generator for Heterogeneous Smart SpacesDoug Palmer CSIRO ICT Centre Doug.Palmer@csiro.au Abstract:
Heterogenous smart spaces are networks of communicating,
embedded resources and general-purpose computers that have
a wide spread of power and capabilities.
Devices can range from having less than a kilobyte of RAM
to many megabytes.
Virtual machine techniques can be used to control some of the inherent complexity of a heterogeneous smart space by providing a common runtime environment. However, a suitably rich, single virtual machine implementation is unlikely to be able to operate in all environments. By using a virtual machine generator and allowing virtual machines to be subsetted, it is possible to provide numerous virtual machines, each tailored to the capabilities of a class of resources.
IntroductionA heterogeneous smart space, such as the SmartLands[18] smart space contains many different sensors and controllers, each with their own set of capabilities and, in particular, computing power. Individual devices can range in power and size from a Berkeley Mote (128Kb flash memory, 4Kb SRAM)[4] to a PDA (64Mb RAM)[16]. The smart space, as a whole, can also have access to general-purpose computing resources[21]. A contrast to a heterogeneous smart space is the sort of homogeneous smart space as the Ageless Aerospace Vehicle skin[14], or a Motes network, where the computing resources available tend towards uniformity. Heterogeneous smart spaces can be expected to appear whenever longevity and cost are overriding issues; in a farm or building, for example. There are a number of factors driving heterogeneity in these environments:
The environments which generate heterogeneous smart spaces also tend to generate a plethora of distinct applications, all competing for resources. On a farm, for example, the stock protection, environment monitoring and irrigation systems may all want to use a single temperature sensor for a variety of purposes. New applications may be added, and old ones removed, in an ad hoc manner. These applications will tend to be of ordinary commercial quality, rather than safety-critical quality and will often fail or go awry; the smart space as a whole will need to be protected from rogue applications. A feature of heterogeneous smart spaces is that common applications -- building heating, stock protection, active maps, etc. -- need to be deployed into individual, complex smart spaces. To allow smart spaces to be useful at a common, commercial level, some mechanism for automated customisation and deployment is needed. There are two strands to automated customisation and deployment: at the top level, a declarative service description language model is needed, to allow applications to abstract the resources needed to perform a task[17]; at the bottom level, some sort of mechanism is needed to help control the complexity inherent in an ad hoc collection of resources with competing applications.
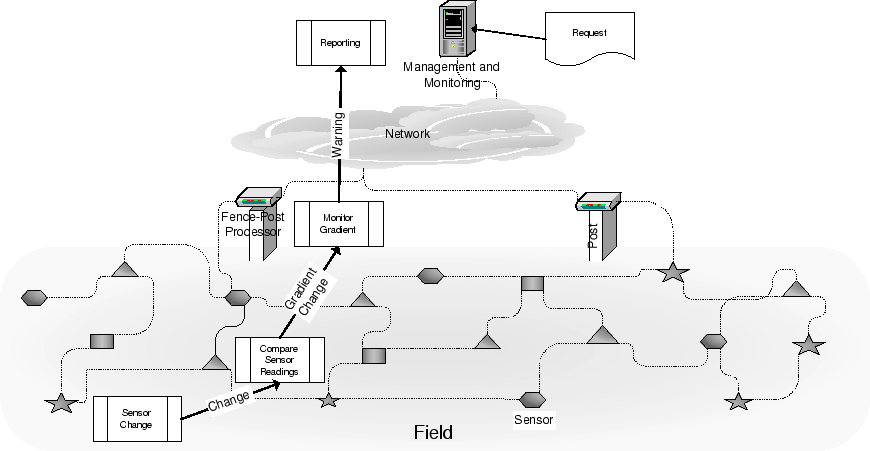
Figure 1 shows an example top-level deployment onto a field smart space. The smart space consists of some low-level soil moisture sensors with minimal processing power and range, some intermediate-level fence-post processors and a general-purpose monitoring and management facility. The moisture sensors have been ``sown'' into the field over several years. Each sowing uses whatever agricultural sensor packages are most economical at the time, leading to a mixture of architectures and processing platforms. The sensors form an ad-hoc network with each sensor connecting to any near neighbours. At the top level is a declarative request made by an application to monitor the moisture gradient of the field and raise an alarm if the gradient fluctuates outside acceptable bounds. This request must be mapped onto the smart space by the smart space itself, since the smart space is aware of the resources available, their capabilities and their properties. In the example smart space, sensors report any significant changes in moisture content to neighbours, which then compare the changes with their own readings. If a fluctuation is detected, the event is reported to a nearby fence-post processor, which collates reports in a local area and notifies the monitor of any significant changes. The deployment shown in Figure 1 only shows one instance of each routine for clarity. Each sensor is running both the sensor monitoring and gradient change detection routines. A consequence of the request is that essentially identical programs need to be run on a wide range of hardware platforms, corresponding to the range of sensors that have been distributed in the field. A bottom-level system that allows a separation between program and implementation would help control the complexity inherent in a deployment across multiple resources. The main requirements for such a bottom-level system can be summarised as follows:
The advantages of a common language runtime have long been recognised when working with many machine architectures and many languages[15]. A virtual machine allows a safe common language runtime to be implemented, with the virtual machine preventing overflows and illegal, unmediated access to resources such as sensors, processor time and memory not allocated to the program being run. However, some of the computing resources in a smart space are not large enough to handle dynamic strings, let alone something as sophisticated as a full object-oriented environment. There is also a considerable difference in the sophistication required across the range of resources. In the soil moisture monitoring example, there is a considerable difference between the simple monitoring functions performed by a sensor and the more complex array processing required in the fence-post processor, where ``significance'' is determined. The approach taken here is to make use of the communications inherent in a smart space. Small resources can use a subset of the full virtual machine, perhaps only capable of simple integer arithmetic. More complex processing can occur on larger resources, capable of more sophisticated processing and memory management. Large scale data and system management can be handled by general-purpose computers[21] or by exploiting the emergent properties of multi-agent systems[14]. An application can be partitioned into fragments of code that can be distributed throughout a smart space, with the low-capability resources offloading sophisticated processing onto their more powerful brethren. To allow specialised virtual machine subsets, a virtual machine generator is used. An abstract virtual machine specification, along with a description of the subset needed for a particular resource, is fed into the generator. The generator then constructs source code (in C or Java) for a virtual machine that implements the specification. This virtual machine can then be compiled, linked with a resource-specific kernel and loaded into the resource. Application-specific code can be loaded into the running virtual machine across a communications network as components[20].
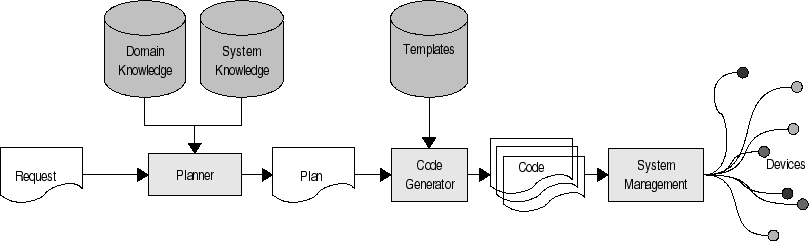
A sample deployment architecture is shown in Figure 2. Each device has a customised virtual machine, with knowledge about the capabilities of that virtual machine kept in a system knowledge database. A high-level request is given to a planner. The planner uses knowledge about the structure of the smart space and the domain of the request to build a plan: a set of small components (a few subroutines in size) in an intermediate language such as Forth or a subset of C. The plan reflects the known capabilities of the devices and the connections between the devices. Each part of the plan is compiled into code by a templating code generator, which selects code generation templates based on the capabilities of the target virtual machine. The code can then be distributed to the target devices.
Related WorkBerkeley Motes provide a consistent model for the development of smart spaces. Since Motes have a very small memory footprint, there have been several developments designed to operate in such a constrained environment. The TinyOS[12] operating system has been developed to provide support for Motes. The nesC[10] language is a language oriented towards TinyOS applications -- and TinyOS itself. TinyOS/nesC is designed to support complete static analysis of applications, including atomic operations and data race detection, to ensure reliability. A single application is linked with TinyOS and deployed as a single unit. This approach can be contrasted with the approach taken in this paper, which assumes multiple, dynamic applications and the ability to kill (and reload) misbehaving components. The obvious advantages of using virtual machines in smart spaces has led to the development of Maté[13] for networks of Motes. There is a considerable overlap between Maté and the virtual machines described in this paper: stack-based, active messages, small footprint. However, Maté follows the general Motes philosophy: a single program and an essentially homogeneous environment allowing a single virtual machine implementation and instruction-level access to hardware. Virtual machine generation has been used successfully with the VMGen[7] system, used to generate virtual machines for GForth. The virtual machine generator presented here shares many of the characteristics of VMGen, although VMGen performs sophisticated superinstruction generation and does not permit subsetting. The Denali lightweight virtual machine model[23] offers a similar model to that discussed in this paper: lightweight, multiplexed virtual machines acting as monitors and sharing resources across a network. However, the focus of Denali is on providing isolated multiplexing on large, general-purpose systems and the para-virtualisation techniques used in Denali would compromise the goal of a common runtime. Also suitable for larger embedded devices is Scylla[19]. Scylla uses a register-based virtual machine that can be easily compiled into the instruction set present in larger embedded processors, such as the ARM. Scylla is oriented towards (just-in-time) compiled applications, something beyond the power of many of the resources discussed in this paper.
OverviewThe paper is structured as follows: Section 2 gives a description of the generic virtual machine architecture that is supported, a stack-based virtual machine with a range of specific data stores; Section 3 describes the way a specific virtual machine is declared in an XML document; Section 4 discusses code generation from a specification to compiled virtual machine, along with some discussion of the size of the generated virtual machine and of potential optimisations; Section 5 concludes the paper.
|
|
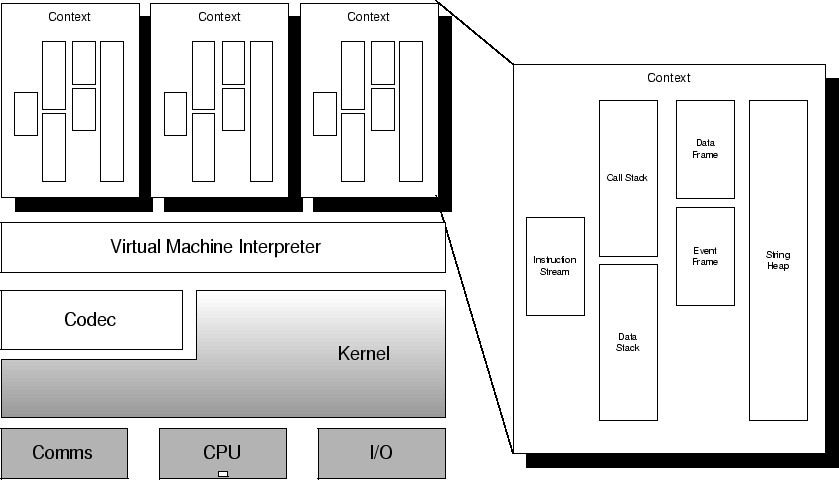
A virtual machine is specified in an XML document. The use of XML allows both ease of use and the wide range of XML tools and technologies to be applied to the specification. The specification allows a stack-based virtual machine to be generated. The essential elements of a specification, shown in Figure 4, are:
|
In addition to the basic virtual machine definition, a separate XML document contains a subset declaration for the virtual machine. An example subset declaration is shown in Figure 5. The subset declaration lists those instructions, events and stores that are to be implemented. The subset declaration also, in the case of events, defines them to be direct or message events. Subset elements can be defined either by inclusion or exclusion. For conciseness, the inclusions and exclusions use regular expressions to match store, instruction and event names.
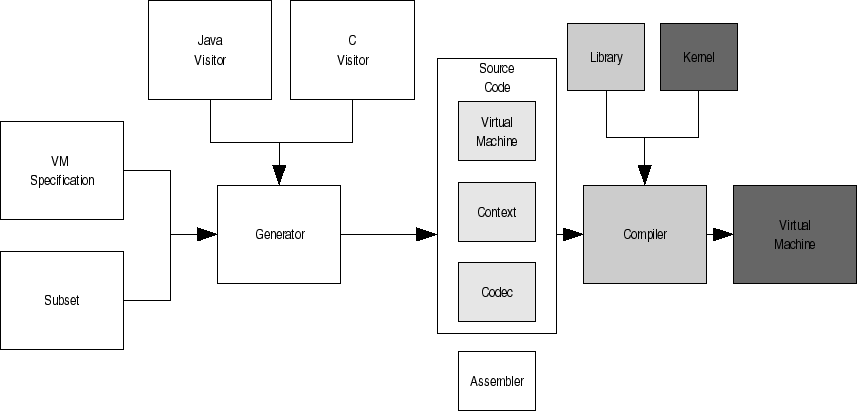
The virtual machine generation process is shown in Figure 6. A virtual machine specification and subset declaration are fed into the generator. The generator then analyses the virtual machine and generates a series of source code files for Java and C that implement the subset virtual machine. The source files are then compiled and linked against a standard library of support functions and classes. An assembler is also generated. Sample declared instructions and generated C code is shown in Figures 7 and 8.
|
|
The complete virtual machine is analysed and instruction codes, event codes and stores are allocated before subsetting. By analysing the complete virtual machine, a subset virtual machine is guaranteed to be compatible with any superset implementation.
Code generation makes extensive use of the Visitor pattern[9]. Each virtual machine construct (type, instruction, store, event, etc.) is represented by an object. A language-specific generator is then used to generate appropriate code.
Superinstruction analysis and generation[7] is not performed. The trade-off in a memory-constrained environment between virtual machine size, on one hand, and code size and speed, on the other hand, is difficult to manage. The aim of the generator is to generate multiple virtual machines, all providing a subset of a common runtime.
Java code generation is relatively straightforward. A separate class file for each element of the virtual machine shown in Figure 3 is generated, along with interfaces for common elements, such as instruction codes. Abstract superclasses provide any common functionality that is needed.
The interpreter uses a large switch statement to decode instructions. For each instruction, arguments are gathered from the various stores and placed in temporary variables. Any implementation code that is part of the declaration is then executed. Any results are then returned to the appropriate stores.
The generated virtual machine interpreter moves commonly used context elements (stack pointers, store arrays) to temporary variables while the context is being executed. These variables are replaced whenever the interpreter cycle for that context finishes or when an instruction with side-effects -- such as an event send -- is executed. The more sophisticated stack caching techniques, discussed in [6], are not implemented, although implementing them would clearly improve performance and caching behaviour.
The UUID method of addressing has proved cumbersome. It is difficult to handle 128-bit objects efficiently without generating large amounts of code, special instructions and special stores. A local context identifier that fits the natural data size of the virtual machine would seem to be more useful, at the expense of more management complexity at higher levels.
The C code generator generates code that is very similar to the generated Java code. The main difference between the two generators is that structs, rather than classes, are used for data structures, with functions taking the structs as arguments. Library code is in the form of individual functions, rather than abstract classes. C, rather than C++, is generated, so that a minimalist approach can be taken to object construction and destruction.
The C virtual machine interpreter needs to do a great deal more bounds checking than the Java interpreter. Stacks, for example, may not overrun their boundaries -- something guaranteed by the Java virtual machine.
The code generated is relatively compact. Table 1 shows the relative code sizes for a simple virtual machine with and without string handling. The Java code was generated by the Sun 1.4.2_01 javac compiler. The C code was generated for a Pentium 4 processor by gcc 3.3.2 with the -Os option. Total size is 9-11k bytes of code for the virtual machine with string handling and 7-8k for the same machine without string handling.
The full virtual machine contains 29 instructions, 6 events, a data stack, a call stack, a data frame, a dispatch frame, a string heap and an instruction stream. The stringless virtual machine contains 25 instructions, 6 events, a data stack, a call stack, a data frame, a dispatch frame and an instruction stream. The underlying resource is a simple resource with 3 3-colour LEDs, a temperature sensor and a heat pump.
String handling increases the size of the generated virtual machine considerably. Clearly, a heap manager is needed, which increases code size. However, string management tends to be more complex in general, requiring specialised marshalling and unmarshalling and more complex instruction implementations. The method size in both the Connection and Codec classes increases by approximately 50% whenever string handling is needed. More importantly, given the small amount of RAM available, string handling requires the allocation of blocks of memory to act as a heap.
The network management and message passing parts of the virtual machine take up a significant part of the total memory footprint. Message and program transmission can be considered a relatively rare event -- or, at least, it should be, if energy consumption is to be taken into account -- in which case its influence on caching and power consumption (see Section 5) can be regarded as negligible. However, it would be a good thing, on principle, to reduce the amount of code needed for such an operation. At present, marshalling is handled by dedicated routines, one to each type of message. An alternative is to try an data-driven, interpreter-based approach[5]. If there a large number of events, this approach looks attractive.
|
An assembled program takes up little space. Table 2 summarises the context sizes, in the network deliverable loader format (see Section 2.2), for a number of simple programs.
The sizes shown in Table 2 show the minimum amount of information needed to initialise a context. Installed contexts usually take up more space within the resource: stacks need enough room to grow and heaps usually need additional space for new blocks of data.
The diversity and complexity of heterogeneous smart spaces, coupled to the stringent restrictions on resource usage that networks of small embedded devices imply, presents a considerable software engineering challenge. The sort of component reuse strategies that have become common in commercial programming environments will also need to be applied to smart spaces, if smart spaces are to become general-purpose, commercial environments. The use of virtual machines provides a method for distributing generic functionality across a wide range of resources.
There are a number of virtual machine optimisations and improvements that could be undertaken. These optimisations are discussed in Sections 4.1 and 4.3. In particular, code-size optimisations can be expected to play an important part in reducing the size of the generated virtual machine. An advantage to using a generator is that any optimisations that are made will propagate to any newly generated virtual machine, rather than requiring hand-optimisation.
Energy consumption and power management is a major concern in the space of small embedded devices, with memory access a significant source of energy consumption. Testing of the energy consumption of Java virtual machines in the Itsy pocket computer suggests that there is the order of a 50% penalty in energy consumption when interpretation is used, instead of a just-in-time compiler[8]. There is an order of magnitude difference between cache memory access and external memory access, however[1]. If the virtual machine interpreter -- or a subset of frequently used instruction implementations -- and a context could be fitted into cache memory, the energy costs could be significantly reduced. The compression effect of virtual machine instructions would then serve a useful purpose in allowing a component to be entirely cached.
Generating virtual machine subsets allows a common runtime environment to be imposed on the diverse array of resources that make up a heterogeneous smart space. Using a generator allows virtual machines to be quickly generated for new resources and to try new instruction sets. The generated virtual machine is relatively compact, although there is considerable room for improvement.
|
This paper was originally published in the
Proceedings of the 3rd Virtual Machine Research and Technology Symposium,
May 6-7, 2004, San Jose, CA, USA Last changed: 29 Aprl 2004 aw |
|