
 |
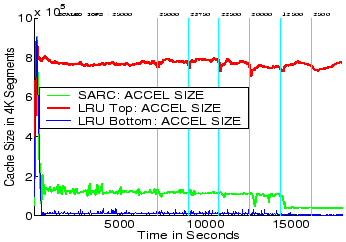
The Figure 7 plots the sizes of the SEQ list versus the time (in seconds) for all the three algorithms. It can be seen that LRU Top allocates too much cache space to SEQ list, LRU Bottom allocates too little cache space to SEQ list, while SARC adaptively allocates just the right amount of cache space to SEQ so as improve the overall performance. It can also be seen that SARC adapts to the evolving workload and selects a different size for the SEQ list at different loads.
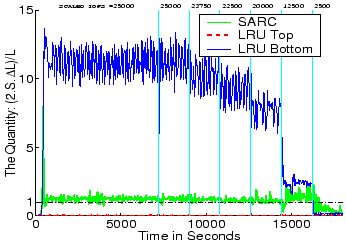 |
The Figure 8 plots the quantity
![]() for the three algorithms. This quantity is denoted by
variable
for the three algorithms. This quantity is denoted by
variable
![]() in line 4 of the algorithm in
Figure 4. It can be seen that for LRU Bottom
keeps
in line 4 of the algorithm in
Figure 4. It can be seen that for LRU Bottom
keeps
![]() too large meaning that it would benefit by
further increase in cache space devoted to sequential data.
Similarly, LRU Top keeps
too large meaning that it would benefit by
further increase in cache space devoted to sequential data.
Similarly, LRU Top keeps
![]() too small meaning
that it would benefit by a decrease in cache space devoted to
sequential data. Whereas SARC keeps
too small meaning
that it would benefit by a decrease in cache space devoted to
sequential data. Whereas SARC keeps
![]() to roughly
the idealized value of
to roughly
the idealized value of ![]() meaning that it essentially gets very
close to the optimum. In other words, SARC will not benefit
by further trading of cache space between SEQ and RANDOM, whereas the other two algorithms would. This plot clearly
explains why SARC outperforms the LRU variants in the
top three panels of Figure 7. Furthermore, quite
importantly, this plot also indicates that any other algorithm
that does not directly attempt to drive
meaning that it essentially gets very
close to the optimum. In other words, SARC will not benefit
by further trading of cache space between SEQ and RANDOM, whereas the other two algorithms would. This plot clearly
explains why SARC outperforms the LRU variants in the
top three panels of Figure 7. Furthermore, quite
importantly, this plot also indicates that any other algorithm
that does not directly attempt to drive
![]() to
to ![]() as
SARC does will not be competitive with SARC. For
example, any algorithm that keeps sequential data in the cache for
a fixed time [1] or allocates a fixed, constant
amount of space to sequential data [29], cannot in general
outperform SARC.
as
SARC does will not be competitive with SARC. For
example, any algorithm that keeps sequential data in the cache for
a fixed time [1] or allocates a fixed, constant
amount of space to sequential data [29], cannot in general
outperform SARC.