| Total Time |
| Category |
Percent Time |
Average Time |
| VMM Time |
77.3% |
N/A |
| Transmitting via the VMNet |
8.7% |
13.8 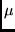 s s |
| Emulating the Lance status register |
4.0% |
3.1 s |
| Handling host IRQs (device interrupts) |
3.4% |
N/A |
| Emulating the Lance transmit path |
3.3% |
5.2 s |
| Receiving via the VMNet |
0.8% |
1.8 s |
| VMM Time |
| Category |
Percent Time |
Average Time |
| IN/OUTs requiring switching to the VMApp |
26.8% |
7.45 s |
| Instructions not requiring virtualization |
22.0% |
N/A |
| General instructions requiring virtualization |
11.6% |
N/A |
| IN/OUTs handled in the VMM |
8.3% |
1.36 s |
| IN/OUTs to the Lance Address Port |
8.1% |
0.74 s |
| Transitioning to/from virtualization code |
4.8% |
N/A |
| Virtualizing the IRET instruction |
4.8% |
3.93 s |
| Delivering virtual IRQs (device interrupts) |
4.6% |
N/A |
|
|
|
