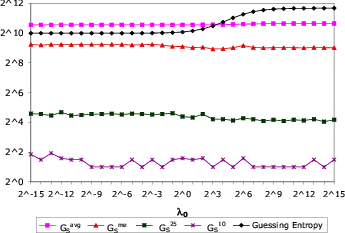
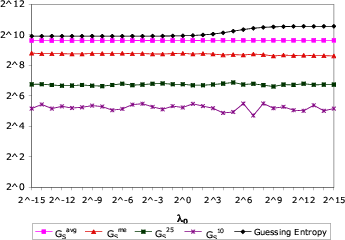
We are primarily concerned with measuring the ability of an attacker
to guess the password of a user. Given accurate values for
![]() for each
for each ![]() , a
measure that indicates this ability is the ``guessing
entropy'' [18] of passwords. Informally, guessing entropy
measures the expected number of guesses an attacker with perfect
knowledge of the probability distribution on passwords would need in
order to guess a password chosen from that distribution. If we
enumerate passwords
, a
measure that indicates this ability is the ``guessing
entropy'' [18] of passwords. Informally, guessing entropy
measures the expected number of guesses an attacker with perfect
knowledge of the probability distribution on passwords would need in
order to guess a password chosen from that distribution. If we
enumerate passwords ![]() ,
, ![]() ,
, ![]() in
non-increasing order of
in
non-increasing order of
![]() , then
the guessing entropy is simply
, then
the guessing entropy is simply
The direct use of (6) to compute guessing entropy
using the probabilities in (5) is problematic for two
reasons. First, an attacker guessing passwords will be offered
additional information when performing a guess, such as the set of
available categories from which the next image can be chosen. For
example, in Face, each image choice is taken from nine images that
represent nine categories of images, chosen uniformly at random from
the twelve categories. This additional information constrains the set
of possible passwords, and the attacker would have this information
when performing a guess in many scenarios. Second, we have found that
the absolute probabilities yielded by (5) can be
somewhat sensitive to the choice of
![]() , which
introduces uncertainty into calculations that utilize these
probabilities numerically.
, which
introduces uncertainty into calculations that utilize these
probabilities numerically.
To account for the second of these issues, we use the probabilities
computed with (5) only to determine an enumeration
![]() of passwords in
non-increasing order of probability (as computed
with (5)). This enumeration is far less sensitive to
variations in
of passwords in
non-increasing order of probability (as computed
with (5)). This enumeration is far less sensitive to
variations in
![]() than the numeric probabilities
are, and so we believe this to be a more robust use of
(5). We use this sequence to conduct tests with our
dataset in which we randomly select a small set of ``test'' passwords
from our dataset (20% of the dataset), and use the remainder of the
data to compute the enumeration
than the numeric probabilities
are, and so we believe this to be a more robust use of
(5). We use this sequence to conduct tests with our
dataset in which we randomly select a small set of ``test'' passwords
from our dataset (20% of the dataset), and use the remainder of the
data to compute the enumeration ![]() .
.
We then guess passwords in order of ![]() until each test password is
guessed. To account for the first issue identified above, namely the
set of available categories during password selection, we first filter
from
until each test password is
guessed. To account for the first issue identified above, namely the
set of available categories during password selection, we first filter
from ![]() the passwords that would have been invalid given the
available categories when the test password was chosen, and obviously
do not guess them. By repeating this test with non-overlapping test
sets of passwords, we obtain a number of
guesses per test password. We use
the passwords that would have been invalid given the
available categories when the test password was chosen, and obviously
do not guess them. By repeating this test with non-overlapping test
sets of passwords, we obtain a number of
guesses per test password. We use
![]() to denote the
average over all test passwords, and
to denote the
average over all test passwords, and
![]() to denote
the median over all test passwords. Finally, we use
to denote
the median over all test passwords. Finally, we use
![]() for
for
![]() to denote the number of guesses sufficient to guess
to denote the number of guesses sufficient to guess
![]() percent of the test passwords. For example, if
percent of the test passwords. For example, if ![]() of the test
passwords could be guessed in
of the test
passwords could be guessed in ![]() or fewer guesses, then
or fewer guesses, then
![]() .
.
We emphasize that by computing our measures in this fashion, they are intrinsically conservative given our dataset. That is, an attacker who was given 80% of our dataset and challenged to guess the remaining 20% would do at least as well as our measures suggest.