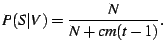Helen J. Wang, John C. Platt, Yu Chen, Ruyun Zhang, Yi-Min Wang
{helenw, jplatt, ychen, ymwang}@microsoft.com
Microsoft Research
Technical support contributes 17% of the total cost of ownership of today's desktop PCs [25]. An important element of technical support is troubleshooting misconfigured applications. Misconfiguration troubleshooting is particularly challenging, because configuration information is shared and altered by multiple applications.
In this paper, we present a novel troubleshooting system: PeerPressure, which uses statistics from a set of sample machines to diagnose the root-cause misconfigurations on a sick machine. This is in contrast with methods that require manual identification on a healthy machine for diagnosing misconfigurations [30]. The elimination of this manual operation makes a significant step towards automated misconfiguration troubleshooting.
In PeerPressure, we introduce a ranking metric for misconfiguration candidates. This metric is based on empirical Bayesian estimation. We have prototyped a PeerPressure troubleshooting system and used a database of 87 machine configuration snapshots to evaluate its performance. With 20 real-world troubleshooting cases, PeerPressure can effectively pinpoint the root-cause misconfigurations for 12 of these cases. For the remaining cases, PeerPressure significantly narrows down the number of root-cause candidates by three orders of magnitude.
Today's desktop PCs have not only brought their users an enormous and ever-increasing number of features and services, but also an increasing amount of troubleshooting costs and productivity losses. Studies have shown that technical support contributes 17% of the total cost of ownership of today's desktop PCs [25]. A large amount of technical support time is spent on troubleshooting.
Many troubleshooting cases are due to misconfigurations. Such misconfiguration is often caused by data that is in shared persistent stores such as the Windows registry and UNIX resource files. These stores may serve many purposes. They include system-wide resources that are naturally shared by all applications (e.g., the file system). They allow applications installed at different times to discover and integrate with one another. They enable users to customize default handlers or appearances of existing applications. They allow individual applications to register with system services to reuse base functionalities. They permit individual components to register with host applications that provide an extensibility mechanism (e.g., toolbars in browsers). To simplify our presentation, we will focus our discussion on a particular type of important configuration data: the Windows Registry [24], which provides hierarchical persistent storage for named, typed entries. Our discussions, techniques, and principles are directly applicable to other types of configuration stores, such as files, and other platforms, such as UNIX.
Misconfigurations can be introduced in many ways. For example, an application may unilaterally make seemingly innocuous changes to shared system configurations and cause unexpected behaviors in another application. A software bug may corrupt a Registry entry (by leaving a data field empty, for example) and break other programs that cannot handle an incorrect data format. Applying security patches may introduce Registry settings that are incompatible with existing applications [11]. Failed uninstallation of applications may introduce configuration inconsistencies resulting in malfunctions [17]. Administrators may inadvertently corrupt Registry entries when they try manually to fix misconfiguration problems using a Registry editor. Ganapathi et al. analyzed and categorized Registry misconfiguration problems based on their manifestation and scope of impact [14]. Some examples include missing Registry entries causing all network connections to disappear from the Control Panel, an extraneous entry causing a CD-ROM player to become inaccessible, a corrupted entry causing the system to log out a user upon any successful login.
Maintaining healthy configurations of a computer platform with a large installed base and numerous third-party software packages has been recognized as a daunting task [19]. The considerable number of possible configurations and the difficulty in specifying the ``golden state'' [26] (the perfect configuration) have made the problem appear to be intractable.
In this paper, we address the problem of misconfiguration troubleshooting. There are two essential goals in designing such a troubleshooting system:
To diagnose misconfigurations of an application on a sick machine, it is natural to find a healthy machine to compare against [30]. Then, the configurations that differ between the healthy and the sick are misconfiguration suspects. However, it is difficult to identify a healthy machine automatically. Involving the user in confirming the correct application behavior seems unavoidable.
We can avoid extensive manual identification work by observing that the golden state is in the mass. In other words, an application functions correctly on most of machines, therefore we can use the statistics from a large enough sample set as the ``statistical golden state''. The statistical golden state can be combined with Bayesian statistics to identify anomalous misconfigurations on sick machines. Then, the misconfigurations can be corrected by conforming to the majority of the samples. Hence, we name this statistical troubleshooting method PeerPressure.
We have prototyped a PeerPressure-based troubleshooting system which draws samples from a database of 87 real-usage machine configuration snapshots. We have evaluated the system with 20 real-world troubleshooting cases. PeerPressure can effectively pinpoint the root-cause misconfigurations for 12 of the cases. For the remaining ones, PeerPressure significantly narrows down the number of root-cause candidates by three orders of magnitude. These results have demonstrated PeerPressure as a promising troubleshooting method.
We will first give an overview of the architecture and operations of the PeerPressure troubleshooting system in Section 2. In Section 3, we detail the formulation and the analysis of the PeerPressure algorithm. We discuss our prototype implementation in Section 4. Then, we present our empirical results in Section 5. We compare and contrast our work with the related work in Section 6, address future work in Section 7, and finally conclude in Section 8.
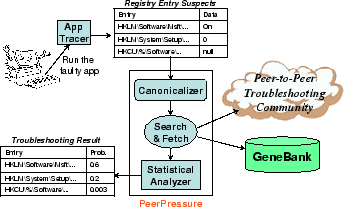
Figure 1 illustrates the architecture and the operations of a PeerPressure troubleshooting system. A troubleshooting user first records the symptom of the faulty application execution on the sick machine with ``App Tracer''. ``App Tracer'' captures the registry entries that are used as input to the failed execution. These entries are the misconfiguration suspects. Then, the user feeds the suspects into the PeerPressure troubleshooter, which has three modules: a canonicalizer, a searcher/fetcher, and a statistical analyzer. The canonicalizer turns any user- or machine-specific entries into a canonicalized form. For example, user names and machine names are all replaced with constant strings ``USERNAME'' and ``MACHINENAME'', respectively. Then, PeerPressure searches for a sample set of machines that run the same application. The search can be performed over a ``GeneBank'' database that consists of a large number of machine configuration snapshots or through a peer-to-peer troubleshooting community. In this paper, we base our discussions on the GeneBank database approach. For the peer-to-peer approach, we refer interested readers to [28]. Next, PeerPressure fetches the respective values of the canonicalized suspects from the sample set machines that also run the application under troubleshooting. The statistical analyzer then uses Bayesian estimation to calculate the probability for each suspect to be sick, and outputs a ranking report based on the sick probability. Finally, PeerPressure conducts trial-and-error fixing, by stepping down the ranking report and replacing the possibly sick value with the most popular value from the sample set. The fixing step interacts with the user to determine whether the sickness is cured: if not, configuration state needs to be properly rolled back. This last step is not shown in the figure and we will not address it for the rest of the paper.
As careful readers can see, there are still some manual steps involved. The first one is that the user must run the sick application to record the suspects. The second one is that the user is involved in determining whether the sickness is cured for the last step. We argue that these manual steps are difficult to eliminate because only the user can recognize the sickness, and therefore has to be in the loop for those steps. Nonetheless, these manual steps only involve the troubleshooting user and not any second parties.
We use an example to illustrate the intuition and objectives of formulating
the sick probability calculation for each suspect. Table 1
shows three suspects (![]() ,
,![]() ,
,![]() ) and their respective values from a
sample set of machine configuration snapshots from the GeneBank. A cursory
examination of the sample set suggests that
) and their respective values from a
sample set of machine configuration snapshots from the GeneBank. A cursory
examination of the sample set suggests that ![]() is probably healthy and
is probably healthy and
![]() is more likely to be sick than
is more likely to be sick than ![]() . The suspect
. The suspect ![]() is more likely
to be sick because all samples have the same value, while the suspect value
is different.
is more likely
to be sick because all samples have the same value, while the suspect value
is different.
In fact, we have seen two types of state in canonicalized configuration
entries: (I) application configuration states such as ![]() and
and ![]() , (II)
operational states such as timestamps, usage counts, caches, seeds for
random number generators, window positions, and MRU (Most Recently
Used)-related information. For troubleshooting configuration failures, we
are mostly concerned with type I entries. Type II entries constitute the
``natural biological diversity'' among machines and are less likely to be
root causes of configuration failures. In our example,
, (II)
operational states such as timestamps, usage counts, caches, seeds for
random number generators, window positions, and MRU (Most Recently
Used)-related information. For troubleshooting configuration failures, we
are mostly concerned with type I entries. Type II entries constitute the
``natural biological diversity'' among machines and are less likely to be
root causes of configuration failures. In our example, ![]() belongs to
category II.
belongs to
category II.
Therefore, the objective for the sick probability formulation is not only to capture the anomaly from the golden mass, but also to weed out the operational state false positives.
Table 2 summarizes our notation.
To estimate whether a suspect is sick, we need to estimate ![]() , the
probability that a suspect is sick given its value
, the
probability that a suspect is sick given its value ![]() . We estimate this
probability for all suspects independently. In the derivation below, let us
consider only one suspect
. We estimate this
probability for all suspects independently. In the derivation below, let us
consider only one suspect ![]() : all parameters are implicitly indexed by
: all parameters are implicitly indexed by ![]() .
.
According to Bayes rule [15], we have:
We need to estimate each of the terms on the right-hand-side of
Equation (1). We first assume that there is only one sick
entry amongst the suspects (leaving the multiple sick entry case for future
work). Before we observe any values, the prior probabilities of a suspect
being sick and healthy are
We do not have an extensive training set of sick suspects. Therefore, we
assume that a sick entry has all possible values with equal probability:
For ![]() , we leverage the observation of a sample set of machine
configurations from the GeneBank. Let
, we leverage the observation of a sample set of machine
configurations from the GeneBank. Let ![]() denote the number of samples
matching
denote the number of samples
matching ![]() , and
, and ![]() , the size of the sample set. If we assume that
, the size of the sample set. If we assume that
![]() is estimated via maximum likelihood, we get the estimate
is estimated via maximum likelihood, we get the estimate
Bayesian estimation [15] of probabilities is more appropriate for
the situation of small sample size ![]() , such as our GeneBank
scenario. Bayesian estimation uses a prior over
, such as our GeneBank
scenario. Bayesian estimation uses a prior over ![]() , before the sample
set is examined. The estimation then uses the posterior estimate of
, before the sample
set is examined. The estimation then uses the posterior estimate of ![]() after the sample set is examined. Therefore,
after the sample set is examined. Therefore, ![]() is never 0 or 1.
is never 0 or 1.
We first assume that ![]() is multinomial over all possible values
is multinomial over all possible values
![]() . A multinomial is a probability distribution that governs a
multi-sided die, where side
. A multinomial is a probability distribution that governs a
multi-sided die, where side ![]() has label
has label ![]() attached to it. The
probability of throwing the die and getting value
attached to it. The
probability of throwing the die and getting value ![]() is
is ![]() .
Because one side is always up when a die is thrown, the
.
Because one side is always up when a die is thrown, the ![]() sum to
one. The multi-sided die (and the multinomial) is completely characterized by
the vector
sum to
one. The multi-sided die (and the multinomial) is completely characterized by
the vector ![]() .
.
We take the Bayesian approach of treating the ![]() values as random
variables. Therefore, the
values as random
variables. Therefore, the ![]() themselves follow a
distribution. Purely for mathematical simplicity, we assume that the
themselves follow a
distribution. Purely for mathematical simplicity, we assume that the
![]() follow a Dirichlet distribution [15]. Dirichlet
distributions are a natural prior for multinomials, because they are
conjugate to multinomials. That is, combining observations from
a multinomial with a prior Dirichlet yields a posterior Dirichlet. The
use of Dirichlet priors is very common in Bayesian inference.
follow a Dirichlet distribution [15]. Dirichlet
distributions are a natural prior for multinomials, because they are
conjugate to multinomials. That is, combining observations from
a multinomial with a prior Dirichlet yields a posterior Dirichlet. The
use of Dirichlet priors is very common in Bayesian inference.
Dirichlet distributions are completely characterized by a count vector
![]() , which corresponds to the number of possible counts for each
value
, which corresponds to the number of possible counts for each
value ![]() . These counts do not need to reflect real observations: as
we will see below, we can count phantom data, also.
. These counts do not need to reflect real observations: as
we will see below, we can count phantom data, also.
To perform Bayesian estimation of ![]() , we first start by choosing
a prior distribution. We assume that all values
, we first start by choosing
a prior distribution. We assume that all values ![]() are equally
probable a priori. Therefore, we start by assuming a Dirichlet
distribution with a count
are equally
probable a priori. Therefore, we start by assuming a Dirichlet
distribution with a count ![]() for all possible values
for all possible values ![]() .
We then observe our
.
We then observe our ![]() samples of values for this registry key,
collecting counts
samples of values for this registry key,
collecting counts ![]() for the different values. The mean of the
posterior Dirichlet yields the posterior estimate
for the different values. The mean of the
posterior Dirichlet yields the posterior estimate
![]() [15]:
[15]:
|
We only need to estimate the ![]() for the value that actually occurs
in the suspect entry. Therefore, we can replace
for the value that actually occurs
in the suspect entry. Therefore, we can replace ![]() with
with ![]() , the number
of samples that matches the suspect entry. Combining
Equations (4) and (1) yields
, the number
of samples that matches the suspect entry. Combining
Equations (4) and (1) yields
We choose ![]() for our prior, which is equivalent to a flat prior:
all multinomial values
for our prior, which is equivalent to a flat prior:
all multinomial values ![]() are equally likely a priori. This
is known as an ``uninformative'' prior.
are equally likely a priori. This
is known as an ``uninformative'' prior.
Bayesian smoothing with an uninformative prior is just one method for smoothing probabilities. Another common method is the Turing-Good smoother [8], which also estimates the probability of a value unseen in the sample set. Unfortunately, Turing-Good is not easily applicable for smoothing probability of registry values: Turing-Good requires a large number of distinct values which occur once or a few times in the sample set, in order to extrapolate the probability of a value that occurs zero times in the sample set. There are many registry values that have a small number of distinct values, hence the extrapolation performed by Turing-Good is not accurate. In other words, Turing-Good works well in linguistics, where the number of distinct values (words) is large, which is not always the case in the registry.
Because we do not use Turing-Good, we must handle the case of a value
that is present in the suspect registry key, but is unseen in the
sample values. We handle this by counting the number of distinct
values in the sample set, ![]() , then adding an additional new value,
called ``unseen''. Any suspect value that is not present in the
sample set will be assigned to the ``unseen'' class. Thus, we set the
cardinality
, then adding an additional new value,
called ``unseen''. Any suspect value that is not present in the
sample set will be assigned to the ``unseen'' class. Thus, we set the
cardinality ![]() and compute the probability of a registry key
being sick given a previously unseen value to be
and compute the probability of a registry key
being sick given a previously unseen value to be
![]() .
.
To show that our Bayesian probability estimates in Equation (5) produce sensible results, we illustrate the asymptotic behavior of the estimates in various cases.
Given a suspect set of size ![]() , there are four variables that affect the
sick probability ranking for the suspects: the number of matches
, there are four variables that affect the
sick probability ranking for the suspects: the number of matches
![]() , the Dirichlet prior strength
, the Dirichlet prior strength ![]() , the sample set size
, the sample set size ![]() , and the
cardinality
, and the
cardinality ![]() . Please note that
. Please note that ![]() can vary among the suspects because of
the canonicalized entries. For example, for a user-specific canonicalized
entry, the number of samples is the number of users rather than the number
of machines in the GeneBank; and a machine can have multiple users. Now, we
analyze how each of these parameters affects the sick probability and
whether the trend agrees with our objectives (see
Section 3.1).
can vary among the suspects because of
the canonicalized entries. For example, for a user-specific canonicalized
entry, the number of samples is the number of users rather than the number
of machines in the GeneBank; and a machine can have multiple users. Now, we
analyze how each of these parameters affects the sick probability and
whether the trend agrees with our objectives (see
Section 3.1).
Fixing ![]() ,
, ![]() , and
, and ![]() , as the number of matches
, as the number of matches ![]() increases, the sick
probability decreases, as desired:
increases, the sick
probability decreases, as desired:
Fixing ![]() ,
, ![]() , and
, and ![]() , as the prior strength
, as the prior strength ![]() increases, we have
increases, we have
For understanding the influence of ![]() , we assume that as
, we assume that as ![]() grows,
grows,
![]() also grows as
also grows as ![]() , for some fraction
, for some fraction ![]() between zero and
one. Therefore,
between zero and
one. Therefore,
To illustrate the impact of the cardinality ![]() , we first note that
, we first note that
![]() implies
implies
![]() . So, applying the analysis for
. So, applying the analysis for ![]() above, we have
above, we have
Now, we examine the case of operational state where ![]() most likely,
we have
most likely,
we have
In summary, our analysis demonstrates that Formula 5 achieves our objective of capturing anomalies and weeding out operational state false positives. Later, in Section 5, we further demonstrate through real-world troubleshooting cases that our PeerPressure algorithm is indeed effective.
We have prototyped the PeerPressure troubleshooting system as shown in Figure 1. We have created a GeneBank database using Microsoft SQL Server 2000 [10], which contains real-usage registry snapshots from 87 Windows XP desktop PCs. Approximately half of these snapshots are from three diverse organizations within Microsoft: Operations and Technology Group (OTG) Helpdesk in Colorado, MSR-Asia, and MSR-Redmond. The other half are from machines across Microsoft that were reported to have potential Registry problems.
We have implemented the PeerPressure troubleshooter in C# [22], which issues queries to the GeneBank to fetch the sample values and carries out the sick probability calculation (Section 3). We use a set of heuristics for canonicalizing user-specific and machine-specific configuration entries in the suspect set. One obstacle we encountered during our prototyping is that values for a specific registry entry across different machines are the same but with different representations. For example, 1, ``#1'', and ``1'' all represent the same value. Nonetheless, the first one is an integer and the latter two are different string representations. Such inconsistent representations of the same data affect all parameter values needed by the sick probability calculation. We use heuristics to unify the different representations of the same data value. We call this procedure ``data sanitization'' for future reference. For example, one such heuristic is to find all entries that have more than one type. (Registry entries contain a ``type'' field). For a registry entry that has both numeric-typed and string-typed values among different registry snapshots, all string values are converted into numbers.
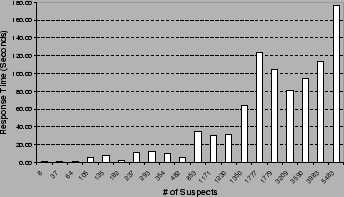
Our PeerPressure troubleshooter, although unoptimized in its present
form, is already fast. We use a dual Intel Xeon 2.4GHz CPU
workstation with 1 GB RAM to host the SQL server and to run the
troubleshooter. On average, it takes less than ![]() seconds to return
a root-cause ranking report for suspect sets of thousands of
entries. The response time generally grows with the number of
suspects. Further analysis shows that database queries dominate the
troubleshooting response time
because we issue one query per suspect
entry. Figure 2 shows the relationship between the
response time and the number of suspects for the 20 troubleshooting
cases under study. With aggressive database query batching, we
anticipate that the response time can be greatly improved.
seconds to return
a root-cause ranking report for suspect sets of thousands of
entries. The response time generally grows with the number of
suspects. Further analysis shows that database queries dominate the
troubleshooting response time
because we issue one query per suspect
entry. Figure 2 shows the relationship between the
response time and the number of suspects for the 20 troubleshooting
cases under study. With aggressive database query batching, we
anticipate that the response time can be greatly improved.
In this section, we evaluate the troubleshooting effectiveness of the PeerPressure prototype on 20 real-world troubleshooting cases. We first examine the registry characteristics based on the registry snapshots from our GeneBank repository, then we present and analyze our troubleshooting results.
|
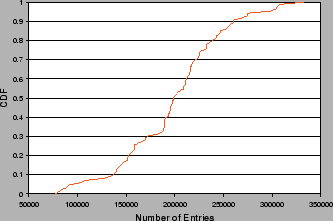
The Windows Registry contains most of the configuration data for a desktop PC. Table 3 summarizes some registry statistics from the GeneBank. The sheer volume of configuration data is daunting. Figure 3 shows the registry size distribution among the registry snapshots in the GeneBank. Registry sizes range from 77,517 to 333,193 entries. The median is 198,608 entries. The total number of distinct canonicalized entries in the GeneBank is 1,476,665. Across all the machines, there are 43,913 common canonicalized entries. With our canonicalization heuristics, an average of 68,126 entries from each registry snapshot are canonicalized. With our data sanitization heuristics (see Section 4), we have sanitized 918,898 entries in the GeneBank.
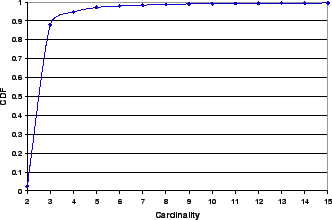
Cardinality is an essential parameter of our PeerPressure algorithm (Section 3). Because the GeneBank may not contain all possible ``genes'' (entry values), we treat all values that are unknown to the GeneBank as a single value unseen. This unseen value effectively increments the observed cardinality from the GeneBank by one. Therefore, any entry from the GeneBank has a cardinality of at least two; and entries that do not exist in the GeneBank have a cardinality of one. In addition, some entries may not exist on some sample machines. For such cases, these entries have the value no entry. Figure 4 shows the distribution of the cardinality for all canonicalized entries in the GeneBank. 87% of the registry entries have a cardinality of two, 94% no more than three, and 97% no more than four. The low cardinality of registry entries contributes to the excellent troubleshooting results of our PeerPressure algorithm (as shown in the next section) because when the cardinality is low, the conformity among the samples is strong.
In this section, we present our empirical troubleshooting results for PeerPressure.
|
We use the 20 cases listed in Table 4 for our experiments. They were all real-world failures that troubled some users. We have the knowledge of root-cause misconfiguration a priori. We picked 20 out of 129 accessible cases from Microsoft (MS) Product Support Service (PSS) e-mail logs, MS Helpdesk, web support forums, and our co-workers' reported problems. The only criterion we used in selecting these cases is the ease of reproducing application failures since some cases require special hardware setup or specific software versions. Cases 1, 11, 13, and 14 are among the most commonly encountered configuration problems from MS PSS e-mail logs [14]; Cases 2, 9, and 10 are from MS Helpdesk; Cases 15-18 are from a web support forum; and the rest are from our co-workers.
Since we know the misconfigured, root-cause entry for each case, we use the ranking of the entry as our evaluation metric. To allow parameterized experiments, we reproduced these failures on a real-usage desktop using configuration user interface (e.g., Control Panel applets) to inject the failures whenever possible, and using direct editing of the Registry for the remaining cases. Then, we used ``App Tracer'' to get the suspects, the entries that are touched during the faulty execution of the application (see Section 2). Finally, we ran PeerPressure to produce the ranking reports.
For each troubleshooting case, Table 5 shows the ranking of the root-cause entry, the number of ties, the number of suspects, the cardinality of the root-cause entry, the number of samples matching the suspect's root-cause entry value, and the number of samples. Ranking ties can happen when the estimated probabilities of some entries have the same values. The non-zero values for the ``# of Matches'' column indicate that the GeneBank contains registry snapshots with the same sickness. Nonetheless, our assumption that the golden state is in the mass is still correct, since there are indeed only very small percentage of the sick machines in the GeneBank.
As we can see from the table, the number of suspects is large: ranging from 8 to 26,308, with a median of 1,171, and an average of 2,506. Therefore, PeerPressure is an indispensable step of troubleshooting since sieving through these large suspect sets for root-cause entries is like finding a needle in a haystack.
For 12 out of the 20 cases, PeerPressure ranks the root-cause entry as number one without any ties. For the remaining cases, PeerPressure narrows down the root-cause candidates in the suspect set by three orders of magnitude for most cases. There is only one case, case 19, which our GeneBank cannot help because only two machines in the GeneBank have the application and they happen to be sick and have the same sick values as well.
The nature of the root-cause entry is only one factor. The ranking also depends on how the root-cause entry relates to other entries in the suspect set. A highly customized machine likely produces more noise, since the unique customizations can be even less conforming than a sick entry value. Case 11, 12, and 16 fall in this category.
Lastly, GeneBank is not pristine. The non-zero values in Column ``# of Matches'' in Table 4 indicate the number of machines in the GeneBank that have the same sickness. This affected the ranking of Case 2, 6, and 10.
|
|
We have experimented with sample sets of size 5, 10, 20, 30, 50, and
87. For each sample set size ![]() , we pick
, we pick ![]() samples from the GeneBank
randomly for 5 times, then we average the root-cause ranking of the random
sample sets. Table 6 shows root-cause ranking trend for
various sample set sizes. The average number of ties for each sample set
size is indicated in the parentheses. For the first three cases in the
table, the root-cause ranking is perfect regardless of the sample set size.
This perfect behavior is caused by all samples of the root-cause entry
taking the same value. Any subset of the GeneBank samples still has the
same value. No other suspects have a high sick probability when the sample
set is small.
samples from the GeneBank
randomly for 5 times, then we average the root-cause ranking of the random
sample sets. Table 6 shows root-cause ranking trend for
various sample set sizes. The average number of ties for each sample set
size is indicated in the parentheses. For the first three cases in the
table, the root-cause ranking is perfect regardless of the sample set size.
This perfect behavior is caused by all samples of the root-cause entry
taking the same value. Any subset of the GeneBank samples still has the
same value. No other suspects have a high sick probability when the sample
set is small.
The cases belonging to the middle portion of Table 6 do not show a clear trend as a function of the sample set size. For Case 20, the root-cause entry has a scattered value distribution and a high cardinality of 65. Therefore, drawing any subset of the samples reflects the same value diversity, and therefore the ranking does not improve with larger sample set. For the other cases, although there is strong conformance in their value distributions, their rankings are affected by other entries in the suspect sets.
For the third category of the cases in the bottom part of Table 6, the root-cause ranking improves with larger sample set. For the first 4 cases, they have near-perfect root-cause ranking. Nonetheless, the number of ties decreases quickly as the sample set size increases. For most of the cases belonging to this category, we can see that the GeneBank has polluted entries according to the ``# of Matches'' column in Table 5. In this situation, enlarging the sample set reduces the impact of the polluted entries and therefore contributes to the decreasing trend of the rankings.
So far, we have only presented results from one sick machine's vantage point. In fact, the troubleshooting results do depend on how uniquely the sick machine is customized and configured. To understand how our results vary with different sick machines, we have picked three real-usage machines that belong to different users, and evaluated the sick machine sensitivity with 5 cases. Table 7 shows that the troubleshooting results on these sick machines are mostly consistent. In some cases, such as Case 6, a larger suspect set leads to better ranking rather than introducing more noise, as one would have expected. This is simply because the larger suspect set on one machine is not necessarily a superset of the smaller suspect set on the other machine.
|
There are two general approaches in system management: the white-box [6][3][9][21][16][27] and the black-box approach [30]. In the former, languages and tools are designed to allow developers or system administrators to specify "rules" of proper system behavior and configurations for monitoring and "actions" to correct any detected deviation. The biggest challenge for the white-box approach is in the accuracy and the completeness of the rule specification.
Strider [30], the precursor of this work, uses the black-box approach for misconfiguration troubleshooting: problems are diagnosed and corrected in the absence of specification of correct behavior. In Strider, the troubleshooting user first identifies a healthy machine on which the application functions correctly. This can be done by finding a healthy configuration snapshot in the past on the same machine or by finding a different healthy machine. Next, Strider performs configuration state differencing between the sick and the healthy, the difference is then further narrowed down by intersecting with suspects obtained from ``App Tracer'' (Section 2). Finally, Strider uses noise-filtering techniques to further narrow down the root-cause candidate set. Noise filtering uses a metric called Inverse Change Frequency, which looks at the change frequency of a registry entry. The more frequent an entry changes, the more likely it is a piece of operational state that is unlikely to be a root cause.
PeerPressure also takes the general black-box approach. PeerPressure differs from Strider in the following ways:
Another interesting work that also takes the black-box approach is that of Aguilera et al. [1]. They address the problem of black-box performance debugging for distributed systems. They developed and compared two algorithms for inferring the dominant causal paths. One uses the timing information from RPC messages. The other uses signal processing techniques. The significant finding of this work is that traces gathered with little or no knowledge of application design or message semantics are sufficient to make useful attributions of the sources of system latency. Therefore, their techniques are applicable to almost any distributed systems.
In a recent position paper, Redstone et al. [23] described a vision of an automated problem diagnosis system that automatically captures aspects of a computer's state, behavior, and symptoms necessary to characterize the problem, and matches such information against problem reports stored in a structured database. Redstone's work addresses the troubles with known root causes. PeerPressure complements this work with the techniques that identify the root causes of unsolved troubleshooting cases.
The concept of using statistical techniques for problem identification
has emerged in several areas in recent years. One way of using
statistics is to build a statistical model of healthy machines, and
compare a sick machine against the statistical model. PeerPressure
falls into this category and is the first to apply Bayesian techniques
to the problem of misconfiguration troubleshooting. Other related
work in this category [12][18][13] first use
statistics to build a correct behavior model which is used to detect
anomalies. Then, the number of false positives is minimized as much as
possible. Engler et al. [12] use static analysis on the
source code to derive likely invariants based on the statistics on
some pre-defined rule templates (such as a call to ![]()
![]() must be paired with a call to
must be paired with a call to ![]()
![]() ). Then, potential bugs
are recognized as deviant behaviors from these invariants. Engler et
al. have discovered hundreds of bugs in Linux and FreeBSD to
date. Later, they further improved the false positive rate
in [18]. Forrest et al.'s seminal work on host-based intrusion
detection system [13] builds a normal-behaving system call
sequence database by observing system calls for various
processes. Then, the intrusions with abnormal system call sequence can
be caught. Apap et al. [2] designed a host-based intrusion
detection system that builds a model of normal Registry behavior
through training and showed that anomaly detection against the model
can identify malicious activities with relatively high accuracy and
low false positive rate.
). Then, potential bugs
are recognized as deviant behaviors from these invariants. Engler et
al. have discovered hundreds of bugs in Linux and FreeBSD to
date. Later, they further improved the false positive rate
in [18]. Forrest et al.'s seminal work on host-based intrusion
detection system [13] builds a normal-behaving system call
sequence database by observing system calls for various
processes. Then, the intrusions with abnormal system call sequence can
be caught. Apap et al. [2] designed a host-based intrusion
detection system that builds a model of normal Registry behavior
through training and showed that anomaly detection against the model
can identify malicious activities with relatively high accuracy and
low false positive rate.
Another way of using statistics is to correlate the observed service failure with root-cause software components or source code for debugging. Liblit et al. [20] uses statistical sampling combined with a number of elimination heuristics to analyze program behaviors. Program failures, such as crashes, are correlated with specific features or even specific variables in a program.
Brown et al [5] takes a black-box approach to infer hardware or software component dependencies by actively probing a system. Statistical model is then used to estimate dependency strengths. Similarly, Brodie et al [4] uses active probing with network events like pings or traceroutes for diagnosing network problems in a distributed system: a small set of high quality probes are first selected, then a Bayesian network is constructed for inferring faults.
The PinPoint root-cause analysis framework [7] is a debugger for component-based systems. PinPoint identifies individual faulty components that cause service failures in a distributed system. PinPoint uses data clustering on a large number of multi-tier request-response traces that are tagged with perceived success/failure status. The clustering determines the root-cause subset component(s) for the service failures.
Sometimes, a failed application execution may be caused by another application's misconfigurations. For example, a web browser may fail because of an incorrect VPN setting. The trace obtained from our AppTracer would not contain root-cause misconfigurations of another application. Cross-application misconfiguration troubleshooting remains an open challenge.
In environments where most or all machines have automatically maintained configurations, sample set selection criteria would need to be adjusted not to include the machines under the same automatic management.
PeerPressure takes the advantage of the strong conformance in most of the configuration entries for diagnosing the anomalies. However, some technology savvy users may customize their PCs so heavily that their configurations appear unique or ``anomalous'' to PeerPressure. These are inevitable false positives produced by PeerPressure.
Another open question is GeneBank maintenance. The GeneBank currently has one-time machine configuration snapshots from 87 volunteers. Without further maintenance, these configuration snapshots will be essentially out-of-date because of numerous software and OS upgrades. Effectively managing the evolving GeneBank is a challenge. Further, we have not yet addressed the privacy issue. The privacy for both the users who contribute their configuration snapshots to the GeneBank and the users who troubleshoot their computers with the GeneBank need to be protected for real deployment. An alternative to the GeneBank approach is to ``search and fetch'' in a peer-to-peer troubleshooting community (see Section 2). Drawing the sample set in a peer-to-peer fashion is essentially treating all computer configuration snapshots from all the peer-to-peer participants as a distributed database that is always up-to-date and requires no maintenance. Nonetheless, the peer-to-peer approach does result in longer search and response time. Further, ensuring the integrity of the troubleshooting result is a challenge in the face of unreliable or malicious peers. We have a proposal for a privacy and integrity-preserving peer-to-peer troubleshooting system. For details, please see [29]
We have developed a PeerPressure troubleshooter and used a database of 87 real-usage machine configuration snapshots to evaluate its performance. With 20 real-world troubleshooting cases, PeerPressure can effectively pinpoint the root-cause misconfigurations for 12 of the cases. For the remaining cases, PeerPressure significantly narrows down the number of root-cause candidates by three orders of magnitude.
In addition to achieving the goal of effective troubleshooting, PeerPressure also makes a significant step towards automation in misconfiguration troubleshooting by using a statistical golden state, rather than manually identifying a single healthy state.
Future work includes multi-gene troubleshooting where there are multiple root-cause entries instead of one, as well as privacy-preservation mechanisms for real deployment.
This document was generated using the LaTeX2HTML translator Version 2002-2-1 (1.71)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -split 0 -show_section_numbers -no_navigation -no_reuse peerPressure
The translation was initiated by Dejan Kostic on 2004-10-12