While we do not have full access to all of the client-side infrastructure, we can try to infer the reasons for the kinds of failures we are seeing and understand their impact on lookup behavior. Absolute confirmation of the failure origins would require direct access to the nameservers, routers, and switches at the sites, which we do not have. Using various techniques, we can trace some problems to packet loss, nameserver overloading, resource competition and maintenance issues. We discuss these below.
Packet Loss - The simplest cause we can guess is the packet loss in the LAN environment. Most nameservers communicate using UDP, so even a single packet loss either as a request or as a response would eventually trigger a query retransmission from the resolver. The resolver's default timeout for retransmission is five seconds, which matches some of the spikes in Figure 1.
Packet loss rates in LAN environments are generally assumed to be minimal, and our measurements of Princeton's LAN support this assumption. We saw no packet loss at two hops, 0.02% loss at three hops, and 0.09% at four hops. Though we did see bursty behavior in the loss rate, where the loss rates would stay high for a minute at a time, we do not see enough losses to account for the DNS failures. Our measurements show that 90% of PlanetLab nodes have a nameserver within 4 hops, and 70% are within 2 hops. However, other contexts, such as cable modems or dial-up services, have more hops [20], and may have higher loss rates.
Nameserver overloading - Since most request packets are likely
to reach the nameserver, our next possible culprit is the nameserver
itself. To understand their behavior, we asked all nameservers on
PlanetLab to resolve a local name once every two seconds and we
measured the results. For example, on planetlab-1.cs.princeton.edu,
we asked for planetlab-2.cs.princeton.edu's IP address. In addition
to the possibility of caching, the local nameserver is mostly likely
the
authoritative nameserver for the queried name, or at least the
authoritative server can be found on the same local network.
In Figure 4, we see some evidence that nameservers can be temporarily overloaded. These graphs cover two days of traffic, and show the 5-minute average failure rate, where a failure is either a response taking more than five seconds, or no response at all. In Figure 4(a), the node experiences no failures most of time but a 30% to 80% failure rate for about five hours. Figure 4(b) reveals a site where failures start during the start of the workday, gradually increase, and drop starting in the evening. It is reasonable to assume that human activity increases in these hours, and affects the failure rate.
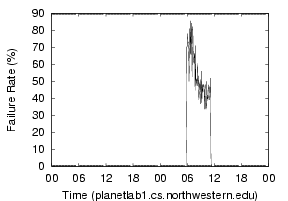 (a) northwestern-1 |
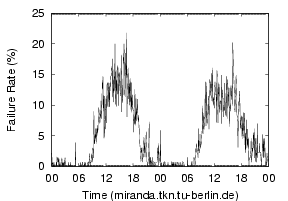 (b) tu-berlin |
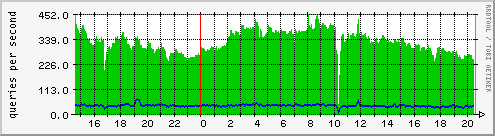
We suspect that a possible factor in this overloading is the UDP receive buffer on the nameserver. These buffers are typically sized in the range of 32-64KB, and incoming packets are silently dropped when this buffer is full. If the same buffer is also used to receive the responses from other nameservers, as the BIND nameserver does, this problem gets worse. Assuming a 64KB receive buffer, a 64 byte query, and a 300 byte response, more than 250 simultaneous queries can cause packet dropping. In Figure 5, we see the request rate (averaged over 5 minutes) for the authoritative nameserver for princeton.edu. Even with smoothing, the request rates are in the range of 250-400 reqs/sec, and we can expect that instantaneous rates are even higher. So, any activity that causes a 1-2 second delay of the server can cause requests to be dropped.
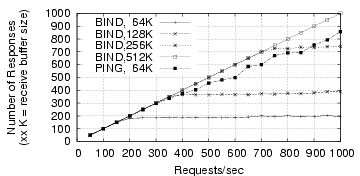
To test this theory of nameserver overload, we subjected BIND, the
most popular nameserver, to bursty traffic. On an otherwise unloaded
box (Compaq au600, Linux 2.4.9, 1 GB memory), we ran BIND 9.2.3 and an
application-level UDP ping that simulates BIND. Each request contains
the same name query for a local domain name with a different query
ID. Our UDP ping responds to it by sending a fixed response with the
same size as BIND's. We send a burst of ![]() requests from a
client
machine and wait 10 seconds to gather responses.
Figure 6 shows the
difference in responses
between BIND 9.2.3 and our UDP ping. With the default receive buffer
size of 64KB, BIND starts dropping requests at bursts of 200 reqs/sec,
and the capacity linearly grows with the size of the receive
buffer. Our UDP ping using the default buffer loses some requests due
to temporary overflow, but the graph does not flatten because
responses consume minimal CPU cycles. These experiments confirm that
high-rate bursty traffic can cause server overload, aggravating the
buffer overflow problem.
requests from a
client
machine and wait 10 seconds to gather responses.
Figure 6 shows the
difference in responses
between BIND 9.2.3 and our UDP ping. With the default receive buffer
size of 64KB, BIND starts dropping requests at bursts of 200 reqs/sec,
and the capacity linearly grows with the size of the receive
buffer. Our UDP ping using the default buffer loses some requests due
to temporary overflow, but the graph does not flatten because
responses consume minimal CPU cycles. These experiments confirm that
high-rate bursty traffic can cause server overload, aggravating the
buffer overflow problem.
Resource competition - Some sites show periodic failures,
similar to what is seen in Figure 7.
These tend to have spikes every hour or every few hours,
and suggests some heavy process is being launched from cron. BIND is
particularly susceptible to memory pressure, since its memory cache
is only periodically flushed. Any jobs that use large amounts of memory
can evict BIND's pages, causing BIND to page fault when accessing the
data. The faults can delay the server, causing the UDP buffer to fill.
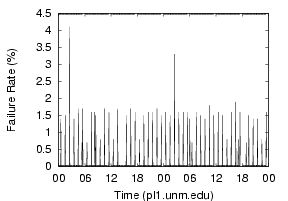 |
In talking with system administrators, we find that even sites with good DNS service often run multiple services (some cron-initiated) on the same machine. Since DNS is regarded as a low-CPU service, other services are run on the same hardware to avoid underutilization. It seems quite common that when these other services have bursty resource behavior, the nameserver is affected.
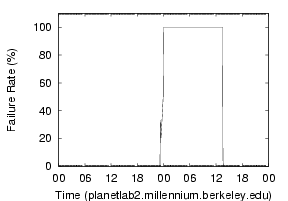
Maintenance problems - Another common source of failure is
maintenance problems which lead to service interruption, as shown in
Figure 8. Here, the DNS
lookup shows
a 100% failure rate for 13 hours. Both nameservers for this site
stopped working causing DNS to be completely unavailable, instead of
just slow. DNS service was restored only after manual intervention.
Another common case, complete failure of the primary nameserver,
generates a similar pattern, with all responses being retried after
five seconds and sent to the secondary nameserver.
 |