| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
OSDI '04 Paper
[OSDI '04 Technical Program]
CP-Miner: A Tool for Finding Copy-paste and Related Bugs
|
 |
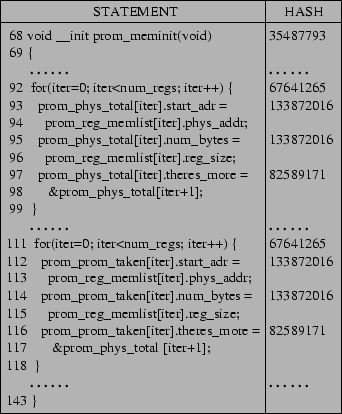
Figure 1 shows an example of a bug detected by CP-Miner in the latest version of Linux (2.6.6). We reported this bug to the Linux kernel community and it has been confirmed by kernel developers [1]. In this example, the loop in lines 111-118 was copied from lines 92-99. In the new copy-pasted segment (lines 111-118), the variable prom_phys_total is replaced with prom_prom_taken in most of the cases except the one in line 117 (shown in bold font). As a result, the pointer prom_prom_taken[iter].theres_more incorrectly points to the element of prom_phys_total instead of prom_prom_taken. This bug is a semantic error, and therefore it cannot be easily detected by memory-related bug detection tools including static checkers [9,14,17,32] or dynamic tools such as Purify [19], Valgrind [36], and CCured [12]. Besides this bug, CP-Miner has also detected many other similar bugs caused by copy-paste in Linux, FreeBSD, PostgreSQL and Web Apache.
While one can imagine augmenting the software development tools and editors with copy-paste tracking, this support does not currently exist. Therefore, we are focusing on detecting likely copied and pasted code in an existing code base. Not all code segments identified by previous detection tools and our tool are really the results of copy-paste (even though we prune many of the false copy-pasted segments as described in Section 3.1.4), but for simplicity we refer likely-copy-pasted segments as copy-pasted segments.
It is a challenging task to efficiently extract copy-pasted code in
large software such as an operating system. Even though some previous
studies [16,20] have addressed the
related problem of plagiarism detection, they are not suitable for
detecting copy-pasted code. Those tools, such as the commonly used
JPlag [33], were designed to measure the degree of
similarity between a pair of programs in order to detect cheating. If
these tools were to be used to detect copy-pasted code in a single
program without any modification, they would need to compare
all possible pairs of code fragments. For a program with ![]() statements, a total of
statements, a total of ![]() pairwise
comparisons
pairwise
comparisons![]() would need to be
performed. This complexity is certainly impractical for software with
millions of lines of code such as Linux and FreeBSD. Of course, it is
possible to modify these tools to identify copy-pasted code in single
software, but the modification is not trivial and straightforward.
would need to be
performed. This complexity is certainly impractical for software with
millions of lines of code such as Linux and FreeBSD. Of course, it is
possible to modify these tools to identify copy-pasted code in single
software, but the modification is not trivial and straightforward.
So far, only a few tools have been proposed to identify copy-pasted code in a single program. Examples of such tools include Moss [4,35], Dup [6], CCFinder [24] and others [5,7]. Most of these tools suffer from some or all of the following limitations:
(1) Efficiency: Most existing tools are not scalable to large
software such as operating system code because they consume a
large amount of memory and take a long time to analyze millions of
lines of code.
(2) Tolerance to modifications: Most tools cannot deal with
modifications in copy-pasted code. Some
tools [13,22] can only detect
copy-pasted segments that are exactly identical. Moreover, most
of the existing tools do not allow statement insertions or
modifications in a copy-pasted segment. Such modifications are
very common in standard practice. Our experiments with CP-Miner
show that about one third of copy-pasted segments contain
insertion or modification of 1-2 statements.
(3) Bug detection: The existing tools cannot detect
copy-paste related bugs. They only aim at detecting copy-pasted
code and do not consider bugs associated with copy-paste.
In this paper we present CP-Miner, a tool that uses data mining techniques to efficiently identify copy-pasted code in large software including operating system code, and also detects copy-paste related bugs. It requires no modification or annotation to the source code of software being analyzed. Our paper makes three main contributions:
(1) A scalable copy-paste detection tool for large software:
CP-Miner can efficiently find copy-pasted code in large software
including operating system code. Our experimental results show that
it takes less than 20 minutes for CP-Miner to detect
150,000-190,000 different copy-pasted segments that account for about
20-22% of the source code in Linux and FreeBSD (each with more than
3 million lines of code). Additionally, it takes less than one minute
to detect copy-pasted segments in Apache web server and PostgreSQL,
accounting for about 17-22% of total source code.
Compared to CCFinder [24], CP-Miner is able to find 17-52% more copy-pasted segments because CP-Miner can tolerate statement insertions and modifications.
(2) Detection of bugs associated with copy-paste: CP-Miner
can detect copy-paste related bugs such as the one shown in
Figure 1, most of which are hard to detect with
existing static or dynamic bug detection tools. More specifically,
CP-Miner has detected 28 potential bugs in the latest version of
Linux, 23 in FreeBSD, 5 in Web Apache, and 2 in PostgreSQL. Most of
these bugs had never been reported.
We have reported these bugs to the corresponding developers. So far five bugs have recently been confirmed and fixed by Linux developers, and one bug has been confirmed and fixed by Apache developers.
(3) Statistical study of copy-pasted code distribution in
operating system code: Few previous studies have been conducted on
the characteristics of copy-paste in large software. Our work
analyzed some interesting statistics of copy-pasted code in Linux and
FreeBSD. Our results indicate that (1) copy-pasted segments are
usually not too large, most with 5-16 statements; (2) although more
than 50% of copy-pasted segments have only two copies, a few
(6.3-6.7%) copy-pasted segments are copied more than 8 times; (3)
there is a significant number (11.3-13.5%) of copy-pasted segments
at function granularity (copy-paste of an entire function); (4) most
(65-67%) copy-pasted segments require renaming at least one
identifier, and 23-27% of copy-pasted segments have inserted,
modified, or deleted one statement; (5) different OS modules have very
different copy-paste coverage: drivers,
arch, and crypt have higher percentage of copy-paste
than other modules in Linux; (6) as the operating system code evolves,
the amount of copy-paste also increases, but the coverage percentage
of copy-pasted code remains relatively stable over the recent versions
of Linux and FreeBSD.
Previous techniques for copy-paste detection can be roughly classified into three categories: (1) string-based, in which the program is divided into strings (typically lines), and these strings are compared against each other to find sequences of duplicated strings [6]; (2) parse-tree-based, in which pattern matching is performed on the parse-tree of the code to search for similar subtrees [7,27]; (3) token-based, in which the program is divided into a stream of tokens and duplicate token sequences are identified [24,33].
Our tool, CP-Miner, is token-based. This approach has advantages over the other two. First, a string-based approach does not exploit any lexical information, so it cannot deal with simple modifications such as identifier renaming. Second, using parse trees can introduce false positives because two segments with identical syntax trees are not necessarily copy-pasted. This is because copy-paste is code-based rather than syntax-based, i.e., it reuses a piece of code rather than an abstract syntax structure.
Most previous copy-paste detection tools do not sufficiently address the limitations described in Section 1. Most of them consume too much time or memory to be scalable to large software, or do not tolerate modifications made in copy-pasted code. In contrast, CP-Miner can address both challenges.
CP-Miner is based on frequent subsequence mining (also called frequent sequence mining), an association analysis technique that discovers frequent subsequences in a sequence database [2]. Frequent subsequence mining is an active research topic in data mining [38,39]. It has broad applications, including mining motifs in DNA sequences, analysis of customer shopping behavior, etc.
A subsequence is considered frequent when it occurs in at least a specified number of sequences (called min_support) in the sequence database. A subsequence is not necessarily contiguous in an original sequence. We denote the number of occurrences of a subsequence as its support. A sequence that contains a given subsequence is called a supporting sequence of this subsequence.
For example, a sequence database ![]() has five sequences:
has five sequences:
![]() . The number of occurrences of
subsequence
. The number of occurrences of
subsequence ![]() is 4, and sequence
is 4, and sequence ![]() is one of
is one of ![]() 's
supporting sequences. If
's
supporting sequences. If
![]() is specified as 4, the
frequent subsequences are
is specified as 4, the
frequent subsequences are
![]() , where the numbers
are the supports of the subsequences.
, where the numbers
are the supports of the subsequences.
CP-Miner uses a recently proposed frequent subsequence mining
algorithm called CloSpan (Closed Sequential
Pattern Mining)[38], which
outperforms most previous algorithms. Instead of mining the complete
set of frequent subsequences, CloSpan mines only the closed
subsequences. A closed subsequence is the subsequence whose support
is different from that of its super-sequences. CloSpan mainly
consists of two stages: (1) using a depth-first search procedure to
generate a candidate set of frequent subsequences that includes all
the closed frequent subsequences; and (2) pruning the non-closed
subsequences from the candidate set. The computational complexity of
CloSpan is ![]() if the maximum length of frequent sequences is
constrained by a constant.
if the maximum length of frequent sequences is
constrained by a constant.
Mining efficiency in CloSpan is improved by two main ideas. The first
is based on an observation that if a sequence is frequent, all of its
subsequences are frequent. For example, if ![]() is frequent, all of
its subsequences
is frequent, all of
its subsequences
![]() are also frequent. CloSpan
recursively produces a longer frequent subsequence by concatenating
every frequent item to a shorter frequent subsequence that has already
been obtained in the previous iterations.
are also frequent. CloSpan
recursively produces a longer frequent subsequence by concatenating
every frequent item to a shorter frequent subsequence that has already
been obtained in the previous iterations.
Let us consider an example. Let ![]() denote the set of frequent
subsequences with length
denote the set of frequent
subsequences with length ![]() . In order to get
. In order to get ![]() , we can join the
sets
, we can join the
sets ![]() and
and ![]() . For example, suppose we have already
computed
. For example, suppose we have already
computed ![]() and
and ![]() as shown below. In order to compute
as shown below. In order to compute ![]() ,
we can first compute
,
we can first compute ![]() by concatenating a subsequence from
by concatenating a subsequence from ![]() and an item from
and an item from ![]() :
:
| �� | |||
| �� | |||
| �� |
For greater efficiency, CloSpan does not join the sequences in set
![]() with all the items in
with all the items in ![]() . Instead, each sequence in
. Instead, each sequence in ![]() is
concatenated with only the frequent items in its suffix
database. A suffix database of a subsequence
is
concatenated with only the frequent items in its suffix
database. A suffix database of a subsequence ![]() is the database of
all the maximum suffixes of the sequences that contain
is the database of
all the maximum suffixes of the sequences that contain ![]() . In our
example, for the frequent sequence
. In our
example, for the frequent sequence ![]() in
in ![]() , its suffix database
is
, its suffix database
is
![]() , and only
, and only ![]() is a frequent item,
so
is a frequent item,
so ![]() is only concatenated with
is only concatenated with ![]() and we get a longer sequence
and we get a longer sequence
![]() that belongs to
that belongs to ![]() .
.
The second idea for improving mining performance is to efficiently
evaluate whether a concatenated subsequence is frequent. Rather than
searching the whole database, CloSpan only checks certain suffixes.
In our example, for each sequence ![]() in
in ![]() , CloSpan checks
whether it is frequent or not by searching the suffix database
, CloSpan checks
whether it is frequent or not by searching the suffix database
![]() . If the number of its occurrences is greater than
. If the number of its occurrences is greater than ![]() ,
,
![]() is added into
is added into ![]() , which is the set of frequent subsequences of
length 3. CloSpan continues computing
, which is the set of frequent subsequences of
length 3. CloSpan continues computing ![]() from
from ![]() ,
, ![]() from
from
![]() , and so on until no more subsequences can be added into the set
of frequent subsequences.
, and so on until no more subsequences can be added into the set
of frequent subsequences.
Due to space limitation, a detailed discussion of the CloSpan
algorithm can be found in [29,38].
To detect copy-pasted code, CP-Miner first converts the problem into a frequent subsequence mining problem. It then uses an enhanced algorithm of CloSpan to find basic copy-pasted segments. Finally, it prunes false positives and composes larger copy-pasted segments. For convenience of description, we refer to a group of code segments that are similar to each other as a copy-paste group.
CP-Miner can detect copy-pasted segments efficiently because it uses frequent subsequence mining techniques that can avoid many unnecessary or redundant comparisons. To map our problem to a frequent subsequence mining problem, CP-Miner first maps a statement to a number, with similar statements being mapped to the same number. Then, a basic block (i.e., a straight-line piece of code without any jumps or jump targets in the middle) becomes a sequence of numbers. As a result, a program is mapped into a database of many sequences. By mining the database using CloSpan, we can find frequent subsequences that occur at least twice in the sequence database. These frequent subsequences are exactly copy-pasted segments in the original program. By applying some pruning techniques such as identifier mapping, we can find basic copy-pasted segments, which can then be combined with neighboring ones to compose larger copy-pasted segments.
CP-Miner is capable of handling modifications in copy-pasted segments for two reasons. First, similar statements are mapped into the same value. This is achieved by mapping all identifiers (variables, functions and types) of the same type into the same value, regardless of their actual names. This relaxation tolerates identifier renaming in copy-pasted segments. Even though false positives may be introduced during this process, they are addressed later through various pruning techniques such as identifier mapping (described in Section 3.1.4). Second, we have enhanced the basic frequent subsequence mining algorithm, CloSpan, to support gap constraints in frequent subsequences. This enhancement allows CP-Miner to tolerate 1-2 statement insertions, deletions, or modifications in copy-pasted code. Insertions and deletions are symmetric because a statement deletion in one copy can also be seen as an insertion in the other copy. Modification is a special case of insertion. Basically, the modified statement can be treated as if both segments have a statement inserted.
The main steps of the process to identify copy-pasted segments include:
(1) Parsing source code: Parse the given source code and
build a sequence database (a collection of sequences). In addition,
information regarding basic blocks and block nesting levels are also
passed to the mining algorithm.
(2) Mining for basic copy-pasted segments: The enhanced
frequent subsequence mining algorithm is applied to the sequence
database to find basic copy-pasted segments.
(3) Pruning false positives: Various techniques including
identifier mapping are used to prune false positives.
(4) Composing larger copy-pasted segments: Larger copy-pasted
segments are identified by combining consecutive smaller ones. The
combined copy-pasted segments are fed back to step (3) to prune false
positives. This is necessary because the combined one may not be
copy-pasted, even though each smaller one is.
Like other copy-paste detection tools, CP-Miner can only detect copy-pasted segments, but cannot tell which segment is original and which is copy-pasted from the original. Fortunately, this limitation is not a big problem because in most cases it is enough for programmers to know what segments are similar to each other. Moreover, our bug detection method described in Section 3.2 does not rely on such differentiation. Additionally, if programmers really need the differentiation, navigating through RCS versions could help figuring out which segment is the original copy.
A statement is mapped to a number by first tokenizing its components such as variables, operators, constants, functions, keywords, etc. To tolerate identifier renaming in copy-pasted segments, identifiers of the same type are mapped into the same token. Constants are handled in the same way as identifiers: constants of the same type are mapped into the same token. However, operators and keywords are handled differently, with each one mapped to a unique token. After all the components of a statement are tokenized, a hash value digest is computed using the ``hashpjw'' [3] hash function, chosen for its low collision rate. Figure 2 shows the hash value for each statement in the example shown in Figure 1 of Section 1. As shown in this figure, the statement in lines 93-94 and the statement in lines 112-113 have the same hash values.
After each statement is mapped, the program becomes a long number sequence. Unfortunately, the frequent subsequence mining algorithms need a collection of sequences (a sequence database) as described in 2.2, so we need a way to cut this long sequence into many short ones. One simple method is to use a fixed cutting window size (e.g., every 20 statements) to break the long sequence into many short ones. This method has two disadvantages. First, some frequent subsequences across two or more windows may be lost. Second, it is not easy to decide the window size: if it is too long, the mining algorithm would be very slow; if too short, too much information may be lost on the boundary of two consecutive windows.
Instead, CP-Miner uses a more elegant method to perform the cutting. It takes advantage of some simple syntax information and uses a basic programming block as the unit to break the long sequence into short ones. The idea for this cutting method is that a copy-pasted segment is usually either a part of a basic block or consists of multiple basic blocks. In addition, basic blocks are usually not too long to cause performance problems in CloSpan. By using a basic block as the cutting unit, CP-Miner can first find basic copy-pasted segments and then compose larger ones from smaller ones. Since different basic blocks have a different number of statements, their corresponding sequences also have different length. But this is not a problem for CloSpan because it can deal with sequences of different sizes. The example shown in Figures 1 and 2 is converted into the following collection of sequences:
(35487793)
......
(67641265)
(133872016, 133872016, 82589171)
......
(67641265)
(133872016, 133872016, 82589171)
......
Besides a collection of sequences, the parser also passes to the mining algorithm the source code information of each sequence. Such information includes (1) the nesting level of each basic block, which is later used to guide the composition of larger copy-pasted segments from smaller ones; (2) the file name and line number, which is used to locate the copy-pasted code corresponding to a frequent subsequence identified by the mining algorithm.
Unfortunately, the mining process is not as straightforward as expected. The main reason is that the original CloSpan algorithm was not designed exactly for our purpose, and nor were other frequent subsequence mining algorithms. Most existing algorithms including CloSpan have the following two limitations that we had to enhance CloSpan to make it applicable for copy-paste detection:
(1) Adding gap constraints in frequent subsequences: In most
existing frequent subsequence mining algorithms, frequent subsequences
are not necessarily contiguous in their supporting sequences. For
example, sequence ![]() provides 1 support for subsequence
provides 1 support for subsequence ![]() ,
even though
,
even though ![]() does not appear contiguously in
does not appear contiguously in ![]() . It is
possible to have a large gap in the occurrence of a frequent
subsequence in one of its supporting sequences. Hence, its
corresponding code segment would have several statements inserted.
Such segment is unlikely to be copy-pasted.
. It is
possible to have a large gap in the occurrence of a frequent
subsequence in one of its supporting sequences. Hence, its
corresponding code segment would have several statements inserted.
Such segment is unlikely to be copy-pasted.
To address this problem, we modified CloSpan to add a gap constraint
in frequent subsequences. CP-Miner only mines for frequent
subsequences with a maximum gap not larger than a given threshold
called
![]() . If the maximum gap of a subsequence in a
sequence is larger than
. If the maximum gap of a subsequence in a
sequence is larger than
![]() , this sequence is not
``supporting'' this subsequence. For example, for the sequence
database
, this sequence is not
``supporting'' this subsequence. For example, for the sequence
database
![]() , the support of
subsequence
, the support of
subsequence ![]() is 1 if
is 1 if
![]() equals 0, and the
support is 3 if
equals 0, and the
support is 3 if
![]() equals 1.
equals 1.
The gap constraint with
![]() means that no statement
insertion or deletions are allowed in copy-paste, whereas the gap
constraint with
means that no statement
insertion or deletions are allowed in copy-paste, whereas the gap
constraint with
![]() or
or
![]() means
that 1 or 2 statement insertions/deletions are tolerated in
copy-paste.
means
that 1 or 2 statement insertions/deletions are tolerated in
copy-paste.
(2) Matching frequent subsequences to copy-pasted segments:
The original CloSpan algorithm outputs only frequent subsequences and
their corresponding support values, but not their corresponding
supporting sequences. To find copy-pasted code, we need to find the
supporting sequences for each frequent subsequence.
We enhance CloSpan to address this problem. When CP-Miner generates a frequent subsequence, it maintains a list of IDs of its supporting sequences. In the above example, CP-Miner outputs two frequent subsequences: (67641265) and (133872016, 133872016, 82589171), each with their supporting sequence IDs, based on which the locations of the corresponding basic copy-pasted segments (file name and line numbers) can be identified.
The composition procedure is very straightforward. CP-Miner maintains a candidate set of copy-paste groups, which initially includes all of the basic copy-pasted segments that survive the pruning procedure described in Section 3.1.4. For each copy-paste group, CP-Miner checks their neighboring code segments to see if they also form a copy-paste group. If so, the two groups are combined together to form a larger one. This larger copy-paste group is checked against the pruning procedure. If it can survive the pruning process, it is added to the candidate set and the two smaller ones are removed. Otherwise, the two smaller ones still remain in the set and are marked as ``non-expandable''. CP-Miner repeats this process until all groups in the candidate set are non-expandable.
(1) Pruning unmappable segments:
This technique is used to prune false positives introduced by the
tokenization of identifiers. This is based on the observation that if
a programmer copy-pastes a code segment and then renames an
identifier, he/she would most likely rename this identifier in all its
occurrences in the new copy-pasted segment. Therefore, we can build an
identifier mapping that maps old names in one segment to their
corresponding new ones in the other segment that belongs to the same
copy-paste group. In the example shown in Figure 2,
variable
![]() is changed into
is changed into
![]() (except the bug on line 117).
(except the bug on line 117).
A mapping scheme is consistent if there are very few conflicts that map one identifier name to two or more different new names. If no consistent identifier mapping can be established between a pair of copy-pasted segments, they are likely to be false positives.
To measure the amount of conflict, CP-Miner uses a metric called
![]() , which records the conflict ratio for an
identifier mapping between two candidate copy-pasted segments. For
example, if a variable
, which records the conflict ratio for an
identifier mapping between two candidate copy-pasted segments. For
example, if a variable ![]() from segment 1 is changed into
from segment 1 is changed into ![]() in 75%
of its occurrences in segment 2 but 25% of its occurrences is changed
into other variables, the
in 75%
of its occurrences in segment 2 but 25% of its occurrences is changed
into other variables, the
![]() of mapping
of mapping
![]() is 25%. The
is 25%. The
![]() for the whole
mapping scheme between these two segments are the weighted sum of
for the whole
mapping scheme between these two segments are the weighted sum of
![]() of the mapping for each unique identifier.
The weight for an identifier
of the mapping for each unique identifier.
The weight for an identifier ![]() in a given code segment is the
fraction of total identifier occurrences that are occurrences of
in a given code segment is the
fraction of total identifier occurrences that are occurrences of ![]() .
If
.
If
![]() for two candidate copy-pasted segments is
higher than a predefined threshold, these two code segments are
filtered as false positives. In our experiments, we set the threshold
to be 60%.
for two candidate copy-pasted segments is
higher than a predefined threshold, these two code segments are
filtered as false positives. In our experiments, we set the threshold
to be 60%.
(2) Pruning tiny segments:
Our mining algorithm may find tiny copy-pasted segments that consist
of only 1-2 simple statements. If such a tiny segment cannot be
combined with neighbors to compose a larger segment, it is removed
from the copy-paste list. This is based on the observation that
copy-pasted segments are usually not very small because programmers
cannot save much effort in copy-pasting a simple tiny code segment.
CP-Miner uses the number of tokens to measure the size of a segment. This metric is more appropriate than the number of statements, because the length of statements is highly variable. If a single statement is very complicated with many tokens, it is still possible for programmers to copy-paste it.
To prune tiny segments, CP-Miner uses a tunable parameter called
![]() . If the number of tokens in a pair of copy-pasted
segments is fewer than
. If the number of tokens in a pair of copy-pasted
segments is fewer than
![]() , this pair is removed.
, this pair is removed.
(3) Pruning overlapped segments:
If a pair of candidate copy-pasted segments overlap with each other,
they are also considered false positives. CP-Miner stops extending
the pair of copy-pasted segments once they overlap. For some program
structures such as the switch statement that contain many
pairs of self-similar segments, pruning overlapped segments can avoid
most of the false positives in switch statements.
(4) Pruning segments with large gaps:
Besides the mining procedure for basic copy-pasted segments, the gap
constraint is also applied to composed ones. When two neighboring
segments are combined, the maximum gap of the newly composed large
segment may become larger than a predefined threshold,
![]() . If this is true, the composition is
invalid. So the newly composed one is not added into the candidate
set and the two smaller ones are marked as non-expandable in the set.
. If this is true, the composition is
invalid. So the newly composed one is not added into the candidate
set and the two smaller ones are marked as non-expandable in the set.
Of course, even after such rigorous pruning, false positives may still exist. However, we have manually examined 100 random copy-pasted segments reported by CP-Miner for Linux, and only a few false positives (8) are found. We can only manually examine each identified copy-pasted segment because there are no traces that record programmers' copy-paste operations during the development of the software.
As we have mentioned in Section 1, the main cause of copy-paste related bugs is that programmers forget to modify identifiers consistently after copy-pasting. Once we get the mapping relationship between identifiers in a pair of copy-pasted segments (see Section 3.1.4), we can find the inconsistency and report these copy-paste related bugs. Table 1 shows the identifier mapping for the example described in Section 1.
For an identifier that appears more than once in a copy-pasted
segment, it is consistent when it always maps to the same identifier
in the other segment. Similarly, it is inconsistent when it maps
itself to multiple identifiers. In Table 1, we
can see that
![]() is mapped inconsistently,
because it maps to
is mapped inconsistently,
because it maps to
![]() three times and
three times and
![]() once. All the other variable mappings
are consistent.
once. All the other variable mappings
are consistent.
Unfortunately, inconsistency does not necessarily indicate a bug. If the amount of inconsistency is high, it may indicate that the code segments are not copy-pasted. Section 3.1.4 describes how we prune unmappable copy-pasted segments based on this observation.
Therefore, the challenge is to decide when an inconsistency is likely
to be a bug instead of a false positive of copy-paste. To address this
challenge, we need to consider the programmers' intention. Our bug
detection method is based on the following observation: if a
programmer makes a change in a copy-pasted segment, the changed
identifier is unlikely to be a bug. But if he/she changes an
identifier in most places but forgets to change it in a few places,
the unchanged identifier is likely to be a bug. In other words,
``forget-to-change'' is more likely to be a bug than an intentional
``change''. For example, if in some cases, an identifier ![]() is
mapped into
is
mapped into ![]() and in other cases it is mapped into
and in other cases it is mapped into ![]() (both
(both ![]() and
and ![]() are different from
are different from ![]() ), it is unlikely to be a bug because
programmers intentionally change
), it is unlikely to be a bug because
programmers intentionally change ![]() to other names. On the
other hand, if
to other names. On the
other hand, if ![]() is changed into
is changed into ![]() in most cases but remains
unchanged only in a few cases, the unchanged places are likely to be
bugs.
in most cases but remains
unchanged only in a few cases, the unchanged places are likely to be
bugs.
Based on the above observation, CP-Miner reexamines each
non-expandable copy-paste group after running through the pruning and
composing procedures. For each pair of copy-pasted segments, it uses
a metric called
![]() to detect bugs in an
identifier mapping. We define
to detect bugs in an
identifier mapping. We define
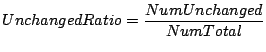
where
![]() means the number of occurrences that a
given identifier is unchanged, and
means the number of occurrences that a
given identifier is unchanged, and
![]() means the
number of total occurrences of this identifier in a given copy-pasted
segment. Therefore, the lower the
means the
number of total occurrences of this identifier in a given copy-pasted
segment. Therefore, the lower the
![]() , the more
likely it is a bug, unless
, the more
likely it is a bug, unless
![]() , which means
that all of its occurrences have been changed. Note that
, which means
that all of its occurrences have been changed. Note that
![]() is different from
is different from
![]() .
The former only measures the ratio of unchanged occurrences, whereas
the latter measures the ratio of conflicts. In the example shown on
Table 1,
.
The former only measures the ratio of unchanged occurrences, whereas
the latter measures the ratio of conflicts. In the example shown on
Table 1,
![]() for
for
![]() is 0.25, whereas all other identifiers
have
is 0.25, whereas all other identifiers
have
![]() .
.
CP-Miner uses a threshold for
![]() to detect
bugs. If
to detect
bugs. If
![]() for an identifier is not zero and
not larger than the threshold,
the unchanged places are reported as bugs. When CP-Miner reports a
bug, the corresponding identifier mapping information is also provided
to programmers to help in debugging. In the example shown on
Table 1, identifier
for an identifier is not zero and
not larger than the threshold,
the unchanged places are reported as bugs. When CP-Miner reports a
bug, the corresponding identifier mapping information is also provided
to programmers to help in debugging. In the example shown on
Table 1, identifier
![]() on line 117 is reported as a bug.
on line 117 is reported as a bug.
It is possible to further extend CP-Miner's bug detection engine.
For example, it might be useful to exploit variable correlations.
Assume variable ![]() always appears in close range to another variable
always appears in close range to another variable
![]() , and
, and ![]() always appears very close to
always appears very close to ![]() . So if in a pair of
copy-pasted segments,
. So if in a pair of
copy-pasted segments, ![]() is renamed to
is renamed to ![]() ,
, ![]() then should be
renamed to
then should be
renamed to ![]() with high confidence. Any violation of this rule may
indicate a bug. But the current version of CP-Miner has not
exploited this possibility. It remains as our future work.
with high confidence. Any violation of this rule may
indicate a bug. But the current version of CP-Miner has not
exploited this possibility. It remains as our future work.
We set the thresholds used in CP-Miner as following. The minimum
copy-pasted segment size
![]() is 30 tokens. We also
vary the gap constraints: (1) when
is 30 tokens. We also
vary the gap constraints: (1) when
![]() = 0, CP-Miner
only identifies copy-pasted code with identifier-renaming; (2) when
= 0, CP-Miner
only identifies copy-pasted code with identifier-renaming; (2) when
![]() = 1 and
= 1 and
![]() = 2, it means
that CP-Miner allows copy-pasted segments with insertion and
deletion of one statement between any two consecutive statements, and
a total of two statement insertions and deletions in the whole
segment. Without specifying, we use setting (2) by default.
= 2, it means
that CP-Miner allows copy-pasted segments with insertion and
deletion of one statement between any two consecutive statements, and
a total of two statement insertions and deletions in the whole
segment. Without specifying, we use setting (2) by default.
We define
![]() to measure the percentage of
copy-paste in given software (or a given module):
to measure the percentage of
copy-paste in given software (or a given module):

In our experiments, we also compare CP-Miner with a recently
proposed tool called CCFinder [24].
Similar to our tool, CCFinder also tokenizes identifiers, keywords,
constant, operators, etc. But different from our tool, it uses a
suffix tree algorithm instead of a data mining algorithm. Therefore,
it cannot tolerate statement insertions and deletions in copy-pasted
code. Our results show that CP-Miner detects 17-52% more
copy-pasted code than CCFinder. In addition, CCFinder does not filter
incomplete, tiny copy-pasted segments which are very likely to be
false positives. CCFinder does not detect copy-paste related bugs, so
we cannot compare this functionality between them.
In our experiments, we run CP-Miner and CCFinder on an Intel Xeon 2.4GHz machine with 2GB memory.
We first present the evaluation results of CP-Miner in this section, including the number of copy-pasted segments, the number of detected copy-paste related bugs, CP-Miner overhead, comparison with CCFinder, and effects of threshold setting. The statistical results of copy-paste characteristics in Linux and FreeBSD will be presented in Section 6.
Our results also show that a large percentage (30-50%) of
copy-pasted segments have statement insertions and modifications. For
example, when
![]() is 1, CP-Miner finds 62.4% more
copy-pasted segments in Linux. In FreeBSD, the
is 1, CP-Miner finds 62.4% more
copy-pasted segments in Linux. In FreeBSD, the
![]() increases from 14.9% to 20.4% when
increases from 14.9% to 20.4% when
![]() is relaxed from 0 to 1. These results show that
previous tools including CCFinder that cannot tolerate statement
insertions and modifications would miss a lot of copy-paste.
is relaxed from 0 to 1. These results show that
previous tools including CCFinder that cannot tolerate statement
insertions and modifications would miss a lot of copy-paste.
By increasing
![]() from 1 to 2 or higher, we can
further relax the gap constraint. Due to space limitation, we do not
show those results here. Also the number of false positives will
increase with
from 1 to 2 or higher, we can
further relax the gap constraint. Due to space limitation, we do not
show those results here. Also the number of false positives will
increase with
![]() . Our manual examination results
with the Linux file system module indicate that false positives are
low with
. Our manual examination results
with the Linux file system module indicate that false positives are
low with
![]() = 1, and relatively low with
= 1, and relatively low with
![]() = 2.
= 2.
CP-Miner has also reported many copy-paste related errors in the
evaluated software. Since the errors reported by CP-Miner may not
be bugs, we verify each reported error manually and then report to the
corresponding developer community those errors that we suspect to be
bugs with high confidence. The numbers of errors found by CP-Miner
and verified bugs are shown on Table 4. The
results are achieved by setting the
![]() threshold to be 0.4.
threshold to be 0.4.
Both Linux and FreeBSD have many copy-paste related bugs. So far, we have verified 28 and 23 bugs in the latest versions of Linux and FreeBSD. Most of these bugs had never been reported before. We have reported these bugs to the kernel developer communities. Recently, five Linux bugs have been confirmed and fixed by kernel developers, and the others are still in the process of being confirmed.
Since Apache and PostgreSQL are much smaller compared to Linux and FreeBSD, CP-Miner found much fewer copy-paste related bugs. We have verified 5 bugs for Apache and 2 bugs for PostgreSQL with high confidence. One bug in Apache was immediately fixed by the Apache developers after we reported it to them.
In addition to those bugs verified, we also find many ``potential bugs'' (21 in Linux and 8 in FreeBSD) that are not bugs by coincidence but might become bugs in the future. We call this type of errors ``careless programming''. Similar to the bugs verified, these errors also forget to change some identifiers consistently at a few places. Fortunately, by coincidence, the new identifiers and the old ones happen to have the same values. However, if such implicit assumptions are violated in future versions of the software, it would lead to bugs that are hard to detect.
Table 4 also shows the number of false alarms reported by CP-Miner. These false alarms are mostly caused by the following two major reasons and can be further pruned in our immediate future work:
(1) Incorrectly matched copy-pasted segments: In some copy-pasted segments that contain multiple ``case'' or ``if'' blocks, there are many possible combinations for these contiguous copy-pasted blocks to compose larger ones. Since CP-Miner simply follows the program order to compose larger copy-pastes, it is likely that a wrong composition might be chosen. As a result, identifiers are compared between two incorrectly matched copy-pasted segments, which results in false alarms.
These false alarms can be pruned if we use more semantic information of the identifiers in these segments. The segments with a number of ``case/if'' blocks usually contain a lot of constant identifiers, but our current CP-Miner treats them as normal variable names. If we use the information of these constants to match ``case/if'' blocks when composing larger copy-pasted segments, it can reduce the number of incorrectly matched segments and most of such false alarms can be pruned.
(2) Exchangeable orders: In a copy-paste pair, the orders of some statements or expressions can be switched. For example, a segment with several similar statements such as ``a1=b1; a2=b2;'' is the same as ``a2=b2; a1=b1;''. The current version of CP-Miner simply compares the identifiers in a pair of copy-pasted segments in strict order and therefore a false alarm might be reported. In Linux, 41 false alarms are caused by such exchangeable orders.
These false alarms can be pruned if we relax the strict order comparison by further checking whether the corresponding ``changed'' identifiers are in the neighboring statements/expressions.
CP-Miner is also space-efficient. For example, it takes less than 530MB to find copy-pasted code in Linux and FreeBSD. For Apache and PostgreSQL, CP-Miner consumes 27-57 MB of memory.
We have compared CP-Miner with CCFinder [24]. CCFinder has execution time similar to that of CP-Miner, but CP-Miner discovers much more copy-pasted segments. In addition, CCFinder does not detect copy-paste related bugs. As we explained in Section 4, CCFinder allows identifier-renaming but not statement insertions. In addition, pruning in CCFinder is not so rigorous as CP-Miner. For example, CCFinder reports incomplete statements in copy-pasted segments, which is unlikely in practice. After pruning the incomplete statements, many small copy-pasted segments consist of less than 30 tokens, which are too simple to be worth copying.
CP-Miner can identify 17-52% more copy-pasted code than CCFinder
because CP-Miner can tolerate statement insertions and
modifications. Table 6 compares the
![]() identified by CP-Miner and CCFinder. The
results with CP-Miner are achieved using the default threshold
setting (
identified by CP-Miner and CCFinder. The
results with CP-Miner are achieved using the default threshold
setting (
![]() = 30 and
= 30 and
![]() = 1). For
fair comparison, we also filter those incomplete, small segments from
CCFinder's output.
= 1). For
fair comparison, we also filter those incomplete, small segments from
CCFinder's output.
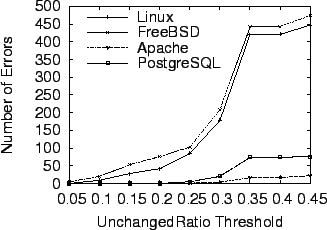
Unchanged Ratio Threshold
Figure 4 shows the effect of unchanged
ratio threshold on the number of bugs reported. Since
![]() means that most of the identifiers
are not changed after copy-pasting, these unchanged identifiers are
unlikely ``forget-to-change'' and so it cannot indicate a copy-paste
related error. Therefore, we only show the errors with
means that most of the identifiers
are not changed after copy-pasting, these unchanged identifiers are
unlikely ``forget-to-change'' and so it cannot indicate a copy-paste
related error. Therefore, we only show the errors with
![]() threshold less than 0.5.
threshold less than 0.5.
As expected, more errors are reported by CP-Miner when the
![]() threshold increases. Specifically, the
number of errors reported increases gradually when the threshold is
less than 0.25, and then increases sharply when the threshold
threshold increases. Specifically, the
number of errors reported increases gradually when the threshold is
less than 0.25, and then increases sharply when the threshold
![]() . We found that most of the errors with high
. We found that most of the errors with high
![]() turn out to be false alarms during our
verification. For example, CP-Miner reports many errors where only
1 out of 3 identifiers is unchanged (
turn out to be false alarms during our
verification. For example, CP-Miner reports many errors where only
1 out of 3 identifiers is unchanged (
![]() ). However, it cannot strongly support that it is a copy-paste
related bug. In order to prune such false alarms, we can further
analyze the identifiers in the context of the copy-pasted segments
(e.g., the whole function). We leave this improvement as our future
work.
). However, it cannot strongly support that it is a copy-paste
related bug. In order to prune such false alarms, we can further
analyze the identifiers in the context of the copy-pasted segments
(e.g., the whole function). We leave this improvement as our future
work.
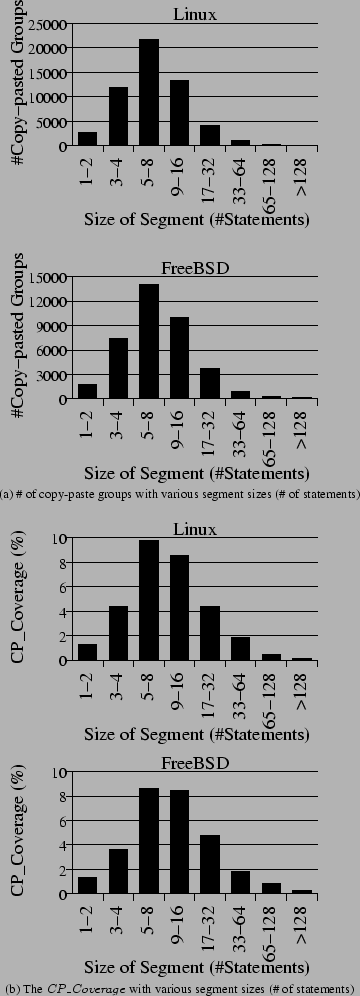 |
Figure 6 shows the distribution of copy-paste group size. About 60% of copy-paste groups contain only two segments, which indicates that there are only two copies (original and replicated) for most copy-pasted code. But still, a lot of code is replicated more than once.
Total 6.3-6.7% of copy-pasted segments are copy-pasted more than 8 times. If a bug is detected in one of the copies, it is difficult for programmers to remember fixing the bug in the other 8 or more copies. This motivates a tool that can automatically fix other copy-pasted segments once a programmer fixes one segment.
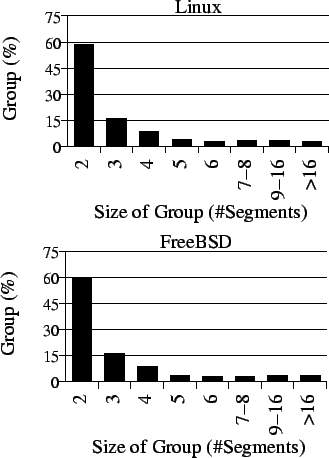 |
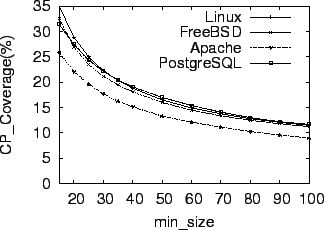
Table 7 shows the number of copy-pasted segments at basic-block and function granularity. Our results show that 9% of copy-pasted segments are basic blocks, which indicates that programmers seldom copy-paste basic blocks because most of them are too simple to worth it.
More interestingly, there are 13.5% of copy-pasted segments with whole functions in Linux and 11.3% in FreeBSD. The reason is that many functions provide similar functionalities, such as reading data from different types of devices. Those functions can be copy-pasted with modifications such as replacing data types of parameters. This motivates some refactoring tools [23] to better maintain these copy-pasted functions.
The results indicate that 65-67% of copy-pasted segments require identifier renaming. For example, in Linux, 27% copy-pasted segments are identical, and 8% segments are almost identical with only one statement inserted. The rest 65% of the copy-pasted segments in Linux rename at least one identifier. Such results motivate a tool to support consistently renaming identifiers in copy-pasted code.
The results in Figure 7 also show that
about 23-27% of copy-pasted segments contain at least one statement
insertion, deletion, and modification (
![]() =1). It
indicates that it is important for copy-paste detection tools to
tolerate such statement modifications.
=1). It
indicates that it is important for copy-paste detection tools to
tolerate such statement modifications.
 |
Different modules have different copy-paste characteristics. In this subsection, we analyze copy-pasted code across different modules in operating system code. We split Linux into 9 categories: arch (platform specific), fs (file system), kernel (main kernel), mm (memory management), net (networking), sound (sound device drivers), drivers (device drivers other than networking and sound device), crypto (cryptography), and others (all other code). For FreeBSD, modules are also split into 9 categories: sys (kernel sources), lib (system libraries), crypto (cryptography), usr.sbin (system administration commands), usr.bin (user commands), sbin (system commands), bin (system/user commands), gnu, and others.
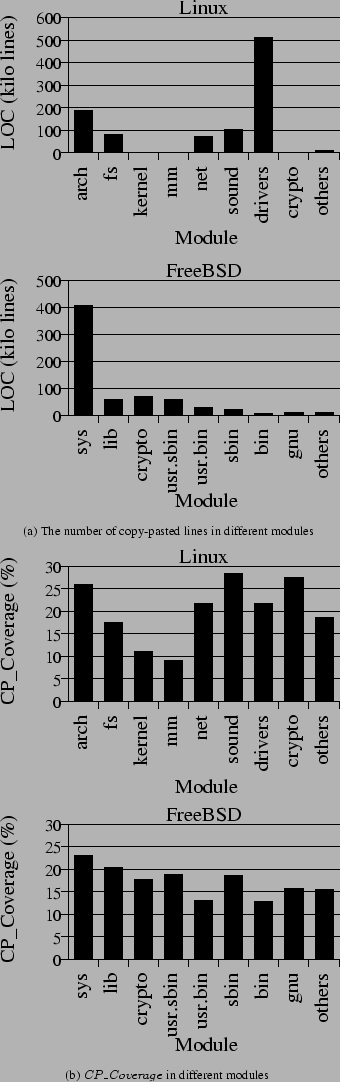
Figure 8 shows the number and
![]() of copy-pasted segments in different modules.
The
of copy-pasted segments in different modules.
The
![]() is computed based on the size of each
corresponding module, instead of the entire software.
is computed based on the size of each
corresponding module, instead of the entire software.
Figure 8 (a) shows that most copy-pasted code in Linux and FreeBSD is located in one or two main modules. For example, modules ``drivers'' and ``arch'' account for 71% of all copy-pasted code in Linux, and module ``sys'' accounts for 60% in FreeBSD. This is because many drivers are similar, and it is much easier to modify a copy-paste of another driver than writing one from scratch.
Figure 8 (b) shows that a large percentage (20-28%) of the code in Linux is copy-pasted in the ``arch'' module, the ``crypto'' module, and the device driver modules including ``net'', ``sound'', and ``drivers''. The ``arch'' module has a lot of copy-pasted code because it has many similar sub-modules for different platforms. The device driver modules contain a significant portion of copy-pasted code because many devices share similar functionalities. Additionally, ``crypto'' is a very small module (less than 10,000 LOC), but the main cryptography algorithms consist of a number of similar computing steps, so it contains a lot of copy-pasted code. Our results indicate that more attention should be paid to these modules because they are more likely to contain copy-paste related bugs.
In contrast, the modules ``mm'' and ``kernel'' contain much less copy-pasted code than others, which indicates that it is rare to reuse code in kernels and memory management modules.
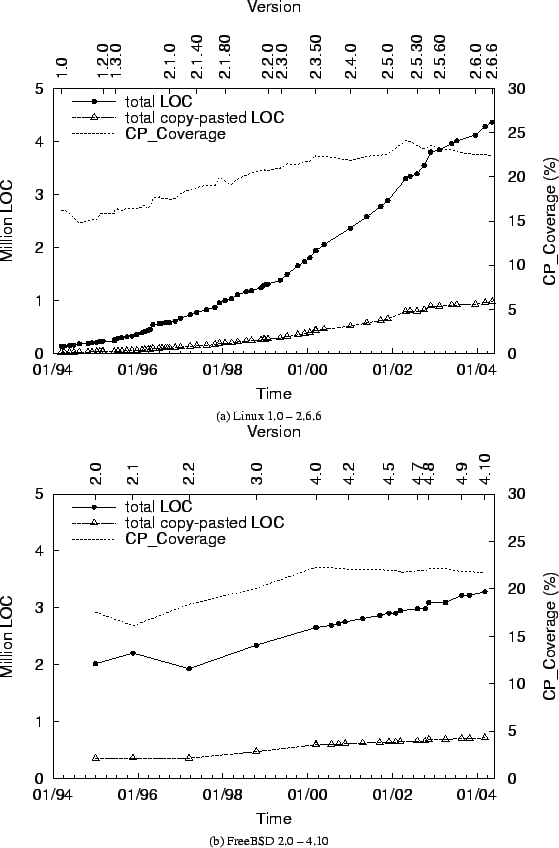
Figure 9 shows that the copy-pasted code increases as the operating system code evolves. For example, Figure 9(a) shows that as Linux's code size increases from 141,000 to 4.4 million lines, copy-pasted code also keeps increasing from 23,000 to 975,000 lines through version 1.0 to 2.6.6.
In terms of
![]() , the percentage of copy-pasted
code also steadily increases along software evolution. For example,
Figure 9(a) shows that
, the percentage of copy-pasted
code also steadily increases along software evolution. For example,
Figure 9(a) shows that
![]() in
Linux increases from 16.2% to 22.3% from version 1.0 to 2.6.6, and
Figure 9(b) shows that
in
Linux increases from 16.2% to 22.3% from version 1.0 to 2.6.6, and
Figure 9(b) shows that
![]() in
FreeBSD increases from 17.5% to 21.7% from version 2.0 to 4.10.
However, the
in
FreeBSD increases from 17.5% to 21.7% from version 2.0 to 4.10.
However, the
![]() remains relatively stable over
the recent several versions for both Linux and FreeBSD. For example,
the
remains relatively stable over
the recent several versions for both Linux and FreeBSD. For example,
the
![]() for FreeBSD has been staying around
21-22% since version 4.0.
for FreeBSD has been staying around
21-22% since version 4.0.
 |
Dup [6] finds all pairs of matching parameterized code fragments. A code fragment matches another if both fragments are contiguous sequences of source lines with some consistent identifier mapping scheme. Because this approach is line-based, it is sensitive to lexical aspects like the presence or absence of new lines. In addition, it does not find non-contiguous copy-pastes. CP-Miner does not have these shortcomings.
Johnson [21] proposed using a fingerprinting algorithm on a substring of the source code. In this algorithm, calculated signatures per line are compared in order to identify matched substrings. As with line-based techniques, this approach is sensitive to minor modifications made in copy-pasted code.
Some graphical tools were proposed to understand code similarities in
different programs (or in the same program)
visually. Dotplots [11] of source code can
be constructed by tokenizing the code into lines and placing a dot in
coordinates ![]() on a 2-D graph, if the
on a 2-D graph, if the ![]() input token
matches
input token
matches ![]() input token. Similarly, Duploc
[13] provides a scatter plot visualization of
copy-pastes (detected by string matching of lines) and also textual
reports that summarize all discovered sequences. Both
Dotplots and Duploc only support line granularity.
In addition, they can only detect identical duplicates and do not
tolerate renaming, insertions, and deletions.
input token. Similarly, Duploc
[13] provides a scatter plot visualization of
copy-pastes (detected by string matching of lines) and also textual
reports that summarize all discovered sequences. Both
Dotplots and Duploc only support line granularity.
In addition, they can only detect identical duplicates and do not
tolerate renaming, insertions, and deletions.
Baxter et al. [7] proposed a tool that transforms source code into abstract-syntax trees (AST), and detects copy-paste by finding identical subtrees. Similar to other tools, it is not tolerant to modifications in copy-pasted segments. In addition, it may introduce many false positives because two code segments with the same syntax subtrees are not necessarily copy-pastes.
Komondoor et al. [26] proposed using program dependence graph (PDG) and program slicing to find isomorphic subgraphs and code duplication. Although this approach is successful at identifying copies with reordered statements, its running time is very long. For example, it takes 1.5 hours to analyze only 11,540 lines of source code from bison, much slower than CP-Miner. Another slow PDG-based approach is found in [28].
Mayrand et al. [31] used an Intermediate Representation Language to characterize each function in the source code and detect copy-pasted function bodies that have similar metric values. This tool does not detect copy-paste at other granularity such as segment-based copy-paste, which occurs more frequently than function-based copy-paste as shown in our results.
Some copy-paste detection techniques are too coarse-grained to be useful for our purpose. JPlag [33], Moss [35], and sif [30] are tools to find similar programs among a given set. They have been commonly used to detect plagiarism. Most of them are not suitable for detecting copy-pasted code in a single large program.
Kontogiannis et al. [27] built an abstract pattern matching tool to identify probable matches using Markov models. This approach does not find copy-pasted code. Instead, it only measures similarity between two programs.
Another approach is to perform checks statically. Examples of this approach include explicit model checking [15,32,37] and program analysis [8,14,17]. Most static tools require significant involvement of programmers to write specifications or annotate programs. But the advantage of static tools is that they add no overhead during execution, and it can find bugs that may not occur in the common execution paths. A few tools do not require annotations, but they focus on detecting different types of bugs, instead of copy-paste related bugs.
Our tool, CP-Miner, is a static tool that can detect copy-paste related bugs, without any annotation requirement from programmers. CP-Miner complements other bug detection tools because it is based on a different observation: finding bugs caused by copy-paste. Some copy-paste related bugs can be found by previous tools if they lead to buffer overflow or some obvious memory corruption, but many of them, especially those semantic ones, cannot be found by previous tools.
Our work is motivated by and related to Engler et al.'s empirical
analysis of operating systems errors [10]. Their
study gave an overall error distribution and evolution analysis in
operating systems, and found that copy-paste is one of the major
causes for bugs. Our work presents a tool to detect copy-pasted code
and related bugs in large software including operating system code.
Many of these bugs such as the one in Figure 1 cannot
be detected by their tools.
This paper presents a tool called CP-Miner ![]() that uses data mining
techniques to efficiently identify copy-pasted code in large software
including operating systems, and also detects copy-paste related bugs.
Specifically, it takes less than 20 minutes for
CP-Miner to identify 190,000 and 150,000 copy-pasted segments that
account for 20-22% of the source code in Linux and FreeBSD.
Moreover, CP-Miner has detected 28 and 23 copy-paste related bugs in
the latest versions of Linux and FreeBSD, respectively. Compared to
CCFinder [24], CP-Miner finds 17-52% more
copy-pasted segments because it can tolerate statement insertions and
modifications in copy-paste. In addition, we have shown some
interesting characteristics of copy-pasted codes in Linux and FreeBSD,
including distribution of copy-paste across different segment sizes,
group sizes, granularity, modules, amount of modifications, and
software evolution.
that uses data mining
techniques to efficiently identify copy-pasted code in large software
including operating systems, and also detects copy-paste related bugs.
Specifically, it takes less than 20 minutes for
CP-Miner to identify 190,000 and 150,000 copy-pasted segments that
account for 20-22% of the source code in Linux and FreeBSD.
Moreover, CP-Miner has detected 28 and 23 copy-paste related bugs in
the latest versions of Linux and FreeBSD, respectively. Compared to
CCFinder [24], CP-Miner finds 17-52% more
copy-pasted segments because it can tolerate statement insertions and
modifications in copy-paste. In addition, we have shown some
interesting characteristics of copy-pasted codes in Linux and FreeBSD,
including distribution of copy-paste across different segment sizes,
group sizes, granularity, modules, amount of modifications, and
software evolution.
Our results indicate that maintaining copy-pasted code would be very useful for programmers because it is commonly used in large software such as operating system code, and it can easily introduce hard-to-detect bugs. We hope our study motivates software development environments such as Microsoft Visual Studio to provide functionality to maintain copy-pasted code and automatically detect copy-paste related bugs.
Even though CP-Miner focuses only on ``forget-to-change'' bugs
caused by copy-paste, copy-paste can introduce many other types of
bugs. For example, after copy-paste operation, the programmer forgets
to add some statements that are specific to the new copy-pasted
segment. However, such bugs are hard to detect because it relies on
semantic information. It is impossible to guess what the programmer
would want to insert or modify. Another type of copy-paste related
bugs is caused by programmers forgetting to fix a known bug in all
copy-pasted segments. They only fix one or two segments but forget to
change it in the others. Our tool CP-Miner can detect simple cases
of this type of errors. But if the fix is too complicated, CP-Miner
would miss the bug because the modified code segment becomes too
different from the others to be identified as copy-paste. To solve
this problem more thoroughly, it would require support from software
development environments such as Microsoft Visual Studio.
~aiken/moss.html.
|
This paper was originally published in the
Proceedings of the 6th Symposium on Operating Systems Design and Implementation,
December 6–8, 2004, San Francisco, CA Last changed: 18 Nov. 2004 aw |
|