
Sybil-Resilient Online Content Voting
Obtaining user opinion (using votes) is essential to ranking user-generated online content. However, any content voting system is susceptible to the Sybil attack where adversaries can out-vote real users by creating many Sybil identities. In this paper, we present SumUp, a Sybil-resilient vote aggregation system that leverages the trust network among users to defend against Sybil attacks. SumUp uses the technique of adaptive vote flow aggregation to limit the number of bogus votes cast by adversaries to no more than the number of attack edges in the trust network (with high probability). Using user feedback on votes, SumUp further restricts the voting power of adversaries who continuously misbehave to below the number of their attack edges. Using detailed evaluation of several existing social networks (YouTube, Flickr), we show SumUp's ability to handle Sybil attacks. By applying SumUp on the voting trace of Digg, a popular news voting site, we have found strong evidence of attack on many articles marked ``popular'' by Digg.
The Web 2.0 revolution has fueled a massive proliferation of user-generated content. While allowing users to publish information has led to democratization of Web content and promoted diversity, it has also made the Web increasingly vulnerable to content pollution from spammers, advertisers and adversarial users misusing the system. Therefore, the ability to rank content accurately is key to the survival and the popularity of many user-content hosting sites. Similarly, content rating is also indispensable in peer-to-peer file sharing systems to help users avoid mislabeled or low quality content [16,7,25].
People have long realized the importance of incorporating user opinion in rating online content. Traditional ranking algorithms such as PageRank [2] and HITS [12] rely on implicit user opinions reflected in the link structures of hypertext documents. For arbitrary content types, user opinion can be obtained in the form of explicit votes. Many popular websites today rely on user votes to rank news (Digg, Reddit), videos (YouTube), documents (Scribd) and consumer reviews (Yelp, Amazon).
Content rating based on users' votes is prone to vote manipulation by malicious users. Defending against vote manipulation is difficult due to the Sybil attack where the attacker can out-vote real users by creating many Sybil identities. The popularity of content-hosting sites has made such attacks very profitable as malicious entities can promote low-quality content to a wide audience. Successful Sybil attacks have been observed in the wild. For example, online polling on the best computer science school motivated students to deploy automatic scripts to vote for their schools repeatedly [9]. There are even commercial services that help paying clients promote their content to the top spot on popular sites such as YouTube by voting from a large number of Sybil accounts [22].
In this paper, we present SumUp , a Sybil-resilient online content voting system that prevents adversaries from arbitrarily distorting voting results. SumUp leverages the trust relationships that already exist among users (e.g. in the form of social relationships). Since it takes human efforts to establish a trust link, the attacker is unlikely to possess many attack edges (links from honest users to an adversarial identity). Nevertheless, he may create many links among Sybil identities themselves.
SumUp addresses the vote aggregation problem
which can be stated as follows: Given ![]() votes on a given object,
of which an arbitrary fraction may be from Sybil identities created by an
attacker, how do we collect votes in a Sybil resilient manner?
A Sybil-resilient vote aggregation solution should satisfy three properties.
First, the solution should collect a significant fraction of votes from honest
users. Second, if the attacker has
votes on a given object,
of which an arbitrary fraction may be from Sybil identities created by an
attacker, how do we collect votes in a Sybil resilient manner?
A Sybil-resilient vote aggregation solution should satisfy three properties.
First, the solution should collect a significant fraction of votes from honest
users. Second, if the attacker has ![]() attack edges, the maximum number of
bogus votes should be bounded by
attack edges, the maximum number of
bogus votes should be bounded by ![]() , independent of the attacker's ability
to create many Sybil identities behind him. Third, if the attacker repeatedly
casts bogus votes, his ability to vote in the future should be diminished. SumUp
achieves all three properties with high probability in the face of Sybil
attacks. The key idea in SumUp is the adaptive vote flow technique
that appropriately assigns and adjusts link capacities in the trust graph to
collect the net vote for an object.
, independent of the attacker's ability
to create many Sybil identities behind him. Third, if the attacker repeatedly
casts bogus votes, his ability to vote in the future should be diminished. SumUp
achieves all three properties with high probability in the face of Sybil
attacks. The key idea in SumUp is the adaptive vote flow technique
that appropriately assigns and adjusts link capacities in the trust graph to
collect the net vote for an object.
Previous works have also exploited the use of trust networks to limit Sybil
attacks [3,15,30,27,26,18], but
none directly addresses the vote aggregation problem.
SybilLimit [26] performs admission control
so that at most ![]() Sybil identities are accepted per attack
edge among
Sybil identities are accepted per attack
edge among ![]() honest identities. As SybilLimit results in 10
honest identities. As SybilLimit results in 10![]() 30
bogus votes per attack edge in a million-user system [26], SumUp
provides notable improvement by limiting bogus votes to one per attack
edge. Additionally, SumUp leverages user feedback to further diminish
the voting power of adversaries that repeatedly vote maliciously.
30
bogus votes per attack edge in a million-user system [26], SumUp
provides notable improvement by limiting bogus votes to one per attack
edge. Additionally, SumUp leverages user feedback to further diminish
the voting power of adversaries that repeatedly vote maliciously.
In SumUp , each vote collector assigns capacities to links in the trust graph
and computes a set of approximate max-flow paths from itself to all voters.
Because only votes on paths with non-zero flows are counted, the number of
bogus votes collected is limited by the total capacity of attack edges instead
of links among Sybil identities. Typically, the number of
voters on a given object is much smaller than the total user population (![]() ).
Based on this insight, SumUp assigns
).
Based on this insight, SumUp assigns ![]() units
of capacity in total, thereby limiting the number of votes that can be
collected to be
units
of capacity in total, thereby limiting the number of votes that can be
collected to be ![]() . SumUp adjusts
. SumUp adjusts ![]() automatically according
to the number of honest voters for each object so that it can aggregate a large
fraction of votes from honest users. As
automatically according
to the number of honest voters for each object so that it can aggregate a large
fraction of votes from honest users. As ![]() is far less than
is far less than ![]() ,
the number of bogus votes collected on a single object (i.e. the
attack capacity) is no more than the number of attack edges (
,
the number of bogus votes collected on a single object (i.e. the
attack capacity) is no more than the number of attack edges (![]() ).
SumUp 's security guarantee on bogus votes is probabilistic. If a vote
collector happens to be close to an attack edge (a low probability event), the
attack capacity could be much higher than
).
SumUp 's security guarantee on bogus votes is probabilistic. If a vote
collector happens to be close to an attack edge (a low probability event), the
attack capacity could be much higher than ![]() . By re-assigning link
capacities using feedback, SumUp can restrict the attack capacity to be
below
. By re-assigning link
capacities using feedback, SumUp can restrict the attack capacity to be
below ![]() even if the vote collector happens to be close to some attack edges.
even if the vote collector happens to be close to some attack edges.
Using a detailed evaluation of several existing social networks (YouTube,
Flickr), we show that SumUp successfully limits the number of bogus votes
to the number of attack edges and is also able to collect ![]() of votes from honest voters. By applying SumUp to the voting
trace and social network of Digg (an online news voting site), we have found
hundreds of suspicious articles that have been marked ``popular'' by Digg.
Based on manual sampling, we believe that at least
of votes from honest voters. By applying SumUp to the voting
trace and social network of Digg (an online news voting site), we have found
hundreds of suspicious articles that have been marked ``popular'' by Digg.
Based on manual sampling, we believe that at least ![]() of suspicious
articles exhibit strong evidence of Sybil attacks.
of suspicious
articles exhibit strong evidence of Sybil attacks.
This paper is organized as follows. In Section 2, we discuss related work and in Section 3 we define the system model and the vote aggregation problem. Section 4 outlines the overall approach of SumUp and Sections 5 and 6 present the detailed design. In Section 7, we describe our evaluation results. Finally in Section 8, we discuss how to extend SumUp to decentralize setup and we conclude in Section 9.
Ranking content is arguably one of the Web's most important problems. As users are the ultimate consumers of content, incorporating their opinions in the form of either explicit or implicit votes becomes an essential ingredient in many ranking systems. This section summarizes related work in vote-based ranking systems. Specifically, we examine how existing systems cope with Sybil attacks [6] and compare their approaches to SumUp .
PageRank [2] and HITS [12] are two popular
ranking algorithms that exploit the implicit human judgment
embedded in the hyperlink structure of web pages. A hyperlink from page A to
page B can be viewed as an implicit endorsement (or vote) of page B by the
creator of page A. In both algorithms, a page has a higher ranking if it is
linked to by more pages with high rankings. Both PageRank and HITS are
vulnerable to Sybil attacks. The attacker can significantly amplify the
ranking of a page A by creating many web pages that link to each other and also
to A. To mitigate this attack, the ranking system must probabilistically reset its
PageRank computation from a small set of trusted web pages with probability
![]() [20]. Despite probabilistic resets, Sybil
attacks can still amplify the PageRank of an attacker's page by a factor of
[20]. Despite probabilistic resets, Sybil
attacks can still amplify the PageRank of an attacker's page by a factor of
![]() [29], resulting in a big win for the attacker
because
[29], resulting in a big win for the attacker
because ![]() is small.
is small.
A user reputation system computes a reputation value for each identity in order to distinguish well-behaved identities from misbehaving ones. It is possible to use a user reputation system for vote aggregation: the voting system can either count votes only from users whose reputations are above a threshold or weigh each vote using the voter's reputation. Like SumUp , existing reputation systems mitigate attacks by exploiting two resources: the trust network among users and explicit user feedback on others' behaviors. We discuss the strengths and limitations of existing reputation systems in the context of vote aggregation and how SumUp builds upon ideas from prior work.
In EigenTrust [11] and Credence [25], each user
independently computes personalized reputation values for all users
based on past transactions or voting histories. In EigenTrust, a user
increases (or decreases) another user's rating upon a good (or bad)
transaction. In Credence [25], a user gives a high (or low) rating
to another user if their voting records on the same set of file objects are
similar (or dissimilar). Because not all pairs of users are known to
each other based on direct interaction or votes on overlapping sets of objects,
both Credence and EigenTrust use a PageRank-style algorithm to
propagate the reputations of known users in order to calculate the reputations
of unknown users. As such, both systems suffer from the same vulnerability
as PageRank where an attacker can amplify the reputation of a Sybil identity by
a factor of ![]() .
.
Neither EigenTrust nor Credence provide provable guarantees on the damage of Sybil attacks under arbitrary attack strategies. In contrast, SumUp bounds the voting power of an attacker on a single object to be no more than the number of attack edges he possesses irrespective of the attack strategies in use. SumUp uses only negative feedback as opposed to EigenTrust and Credence that use both positive and negative feedback. Using only negative feedback has the advantage that an attacker cannot boost his attack capacity easily by casting correct votes on objects that he does not care about.
DSybil [28] is a feedback-based recommendation system that provides provable guarantees on the damages of arbitrary attack strategies. DSybil differs from SumUp in its goals. SumUp is a vote aggregation system which allows for arbitrary ranking algorithms to incorporate collected votes to rank objects. For example, the ranking algorithm can rank objects by the number of votes collected. In contrast, DSybil's recommendation algorithm is fixed: it recommends a random object among all objects whose sum of the weighted vote count exceeds a certain threshold.
A number of proposals from the semantic web and peer-to-peer literature rely on the trust network between users to compute reputations [30,15,8,21,3]. Like SumUp , these proposals exploit the fact that it is difficult for an attacker to obtain many trust edges from honest users because trust links reflect offline social relationships. Of the existing work, Advogato [15], Appleseed [30] and Sybilproof [3] are resilient to Sybil attacks in the sense that an attacker cannot boost his reputation by creating a large number of Sybil identities ``behind'' him. Unfortunately, a Sybil-resilient user reputation scheme does not directly translate into a Sybil-resilient voting system: Advogato only computes a non-zero reputation for a small set of identities, disallowing a majority of users from being able to vote. Although an attacker cannot improve his reputation with Sybil identities in Appleseed and Sybilproof, the reputation of Sybil identities is almost as good as that of the attacker's non-Sybil accounts. Together, these reputable Sybil identities can cast many bogus votes.
Many proposals use trust networks to defend against Sybil attacks in the context of different
applications: SybilGuard [27] and SybilLimit [26]
help a node admit another node in a decentralized system such that
the admitted node is likely to be an honest node instead of a Sybil identity.
Ostra [18] limits the rate of unwanted communication that adversaries can
inflict on honest nodes. Sybil-resilient DHTs [5,14]
ensure that DHT routing is correct in the face of Sybil attacks.
Kaleidoscope [23] distributes proxy identities to honest clients
while minimizing the chances of exposing them to the censor with many Sybil
identities. SumUp builds on their insights and addresses a different
problem, namely, aggregating votes for online content rating. Like
SybilLimit, SumUp bounds the power of attackers according to the number of
attack edges. In SybilLimit, each
attack edge results in ![]() Sybil identities accepted by honest nodes.
In SumUp , each attack edge leads to at most one vote
with high probability. Additionally, SumUp uses user feedback
on bogus votes to further reduce the attack capacity to below the number
of attack edges. The feedback mechanism of SumUp is inspired by
Ostra [18].
Sybil identities accepted by honest nodes.
In SumUp , each attack edge leads to at most one vote
with high probability. Additionally, SumUp uses user feedback
on bogus votes to further reduce the attack capacity to below the number
of attack edges. The feedback mechanism of SumUp is inspired by
Ostra [18].
In this section, we outline the system model and formalize the vote aggregation problem that SumUp addresses.
System model: We describe SumUp in a centralized setup where a trusted central authority maintains all the information in the system and performs vote aggregation using SumUp in order to rate content. This centralized mode of operation is suitable for web sites such as Digg, YouTube and Facebook, where all users' votes and their trust relationships are collected and maintained by a single trusted entity. We describe how SumUp can be applied in a distributed setting in Section 8.
SumUp leverages the trust network among users to defend against Sybil
attacks [30,3,15,27,26].
Each trust link is directional. However, the creation of each link
requires the consent of both users. Typically, user ![]() creates a
trust link to
creates a
trust link to ![]() if
if ![]() has an offline social relationship to
has an offline social relationship to ![]() .
Similar to previous work [18,26], SumUp requires
that links are difficult to establish. As a result, an attacker
only possesses a small number of attack edges (
.
Similar to previous work [18,26], SumUp requires
that links are difficult to establish. As a result, an attacker
only possesses a small number of attack edges (![]() ) from
honest users to colluding adversarial identities. Even though
) from
honest users to colluding adversarial identities. Even though
![]() is small, the attacker can create many Sybil
identities and link them to adversarial entities. We refer to votes
from colluding adversaries and their Sybil identities as bogus
votes.
is small, the attacker can create many Sybil
identities and link them to adversarial entities. We refer to votes
from colluding adversaries and their Sybil identities as bogus
votes.
SumUp aggregates votes from one or more trusted vote collectors. A trusted collector is required in order to break the symmetry between honest nodes and Sybil nodes [3]. SumUp can operate in two modes depending on the choice of trusted vote collectors. In personalized vote aggregation, SumUp uses each user as his own vote collector to collect the votes of others. As each user collects a different number of votes on the same object, she also has a different (personalized) ranking of content. In global vote aggregation, SumUp uses one or more pre-selected vote collectors to collect votes on behalf of all users. Global vote aggregation has the advantage of allowing for a single global ranking of all objects; however, its performance relies on the proper selection of trusted collectors.
Vote Aggregation Problem: Any identity in the trust network including Sybils can cast a vote on any object to express his opinion on that object. In the simplest case, each vote is either positive or negative (+1 or -1). Alternatively, to make a vote more expressive, its value can vary within a range with higher values indicating more favorable opinions. A vote aggregation system collects votes on a given object. Based on collected votes and various other features, a separate ranking system determines the final ranking of an object. The design of the final ranking system is outside the scope of this paper. However, we note that many ranking algorithms utilize both the number of votes and the average value of votes to determine an object's rank [2,12]. Therefore, to enable arbitrary ranking algorithms, a vote aggregation system should collect a significant fraction of votes from honest voters.
A voting system can also let the vote collector provide negative feedback on malicious votes. In personalized vote aggregation, each collector gives feedback according to his personal taste. In global vote aggregation, the vote collector(s) should only provide objective feedback, e.g. negative feedback for positive votes on corrupted files. Such feedback is available for a very small subset of objects.
We describe the desired properties of a vote aggregation system.
Let ![]() be a trust network with
vote collector
be a trust network with
vote collector ![]() .
. ![]() is comprised of an unknown set of
honest users
is comprised of an unknown set of
honest users ![]() (including
(including ![]() ) and the attacker
controls all vertices in
) and the attacker
controls all vertices in
![]() , many of which represent
Sybil identities. Let
, many of which represent
Sybil identities. Let ![]() represent the number of attack edges
from honest users in
represent the number of attack edges
from honest users in ![]() to
to
![]() . Given that nodes in
. Given that nodes in ![]() cast
votes on a specific object, a vote aggregation mechanism
should achieve three properties:
cast
votes on a specific object, a vote aggregation mechanism
should achieve three properties:
 |
This section describes the intuition behind adaptive vote flow that SumUp uses to address the vote aggregation problem. The key idea of this approach is to appropriately assign link capacities to bound the attack capacity.
In order to limit the number of votes that Sybil identities
can propagate for an object, SumUp computes a set of max-flow
paths in the trust graph from the vote collector to all voters on a given object.
Each vote flow consumes one unit of capacity along
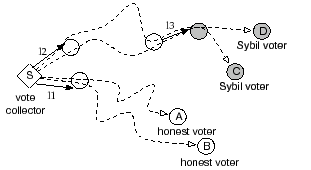
each link traversed. Figure 1 gives an example of
the resulting flows from the collector ![]() to voters A,B,C,D. When
all links are assigned unit capacity, the attack capacity using the
max-flow based approach is bounded by
to voters A,B,C,D. When
all links are assigned unit capacity, the attack capacity using the
max-flow based approach is bounded by ![]() .
.
The concept of max-flow has been applied in several reputation systems based on trust networks [3,15]. When applied in the context of vote aggregation, the challenge is that links close to the vote collector tend to become ``congested'' (as shown in Figure 1), thereby limiting the total number of votes collected to be no more than the collector's node degree. Since practical trust networks are sparse with small median node degrees, only a few honest votes can be collected. We cannot simply enhance the capacity of each link to increase the number of votes collected since doing so also increases the attack capacity. Hence, a flow-based vote aggregation system faces the tradeoff between the maximum number of honest votes it can collect and the number of potentially bogus votes collected.
The adaptive vote flow technique addresses this tradeoff
by exploiting two basic observations. First, the number of honest users
voting for an object, even a popular one, is significantly smaller than the
total number of users. For example, ![]() of popular articles on
Digg have fewer than
of popular articles on
Digg have fewer than ![]() votes which represents
votes which represents ![]() of active users.
Second, vote flow paths to honest voters tend to be only ``congested'' at links
close to the vote collector while paths to Sybil voters are also congested at a
few attack edges. When
of active users.
Second, vote flow paths to honest voters tend to be only ``congested'' at links
close to the vote collector while paths to Sybil voters are also congested at a
few attack edges. When ![]() is small, attack edges tend to be far
away from the vote collector. As shown in
Figure 1, vote flow paths to honest voters A and B are congested at
the link
is small, attack edges tend to be far
away from the vote collector. As shown in
Figure 1, vote flow paths to honest voters A and B are congested at
the link ![]() while paths to Sybil identities C and D are congested at both
while paths to Sybil identities C and D are congested at both
![]() and attack edge
and attack edge ![]() .
.
The adaptive vote flow computation uses three key ideas. First, the algorithm
restricts the maximum number of votes collected on an object to a value
![]() . As
. As ![]() is used to assign the overall capacity in the trust
graph, a small
is used to assign the overall capacity in the trust
graph, a small ![]() results in less capacity for the attacker.
SumUp can adaptively adjust
results in less capacity for the attacker.
SumUp can adaptively adjust ![]() to collect a large fraction of honest
votes on any given object. When the number of honest voters is
to collect a large fraction of honest
votes on any given object. When the number of honest voters is ![]() where
where
![]() , the expected number of bogus votes is limited to
, the expected number of bogus votes is limited to ![]() per
attack edge (Section 5.4).
per
attack edge (Section 5.4).
 |
The second important aspect of SumUp relates to capacity assignment, i.e.
how to assign capacities to each trust link in order to collect a large fraction of
honest votes and only a few bogus ones? In SumUp , the vote collector
distributes ![]() tickets downstream in a breadth-first search
manner within the trust network. The capacity assigned to a link is the number
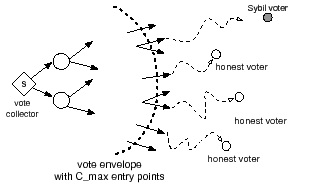
of tickets distributed along the link plus one. As Figure 2 illustrates,
the ticket distribution process introduces a vote
envelope around the vote collector
tickets downstream in a breadth-first search
manner within the trust network. The capacity assigned to a link is the number
of tickets distributed along the link plus one. As Figure 2 illustrates,
the ticket distribution process introduces a vote
envelope around the vote collector ![]() ; beyond the envelope all links have
capacity
; beyond the envelope all links have
capacity ![]() . The vote envelope contains
. The vote envelope contains ![]() nodes that can be viewed as
entry points. There is enough capacity within the envelope to collect
nodes that can be viewed as
entry points. There is enough capacity within the envelope to collect
![]() votes from entry points. On the other hand, an attack edge beyond
the envelope can propagate at most
votes from entry points. On the other hand, an attack edge beyond
the envelope can propagate at most ![]() vote regardless of the number of Sybil
identities behind that edge. SumUp re-distributes tickets based on
feedback to deal with attack edges within the envelope.
vote regardless of the number of Sybil
identities behind that edge. SumUp re-distributes tickets based on
feedback to deal with attack edges within the envelope.
The final key idea in SumUp is to leverage user feedback to penalize attack edges that continuously propagate bogus votes. One cannot penalize individual identities since the attacker may always propagate bogus votes using new Sybil identities. Since an attack edge is always present in the path from the vote collector to a malicious voter [18], SumUp re-adjusts capacity assignment across links to reduce the capacity of penalized attack edges.
In this section, we present the basic capacity assignment algorithm that achieves two of the three desired properties discussed in Section 3: (a) Collect a large fraction of votes from honest users; (b) Restrict the number of bogus votes to one per attack edge with high probability. Later in Section 6, we show how to adjust capacity based on feedback to deal with repeatedly misbehaved adversarial nodes.
We describe how link capacities are assigned given a particular ![]() in
Section 5.1 and present a fast algorithm to calculate
approximate max-flow paths in Section 5.2. In
Section 5.3, we introduce an additional optimization strategy
that prunes links in the trust network so as to reduce the number of attack
edges. We formally analyze the security properties of SumUp in
Section 5.4 and show how to adaptively set
in
Section 5.1 and present a fast algorithm to calculate
approximate max-flow paths in Section 5.2. In
Section 5.3, we introduce an additional optimization strategy
that prunes links in the trust network so as to reduce the number of attack
edges. We formally analyze the security properties of SumUp in
Section 5.4 and show how to adaptively set ![]() in
Section 5.5.
in
Section 5.5.
The goal of capacity assignment is twofold. On the one hand, the
assignment should allow the vote collector to gather a large fraction of honest
votes. On the other hand, the assignment should minimize the attack capacity
such that
![]() .
.
As Figure 2 illustrates, the basic idea of capacity assignment
is to construct a vote envelope around the vote collector with at least
![]() entry points. The goal is to minimize the chances of including an
attack edge in the envelope and to ensure that there is enough capacity within
the envelope so that all vote flows from
entry points. The goal is to minimize the chances of including an
attack edge in the envelope and to ensure that there is enough capacity within
the envelope so that all vote flows from ![]() entry points can reach the
collector.
entry points can reach the
collector.
We achieve this goal using a ticket distribution mechanism which
results in decreasing capacities for links with increasing
distance from the vote collector. The distribution mechanism is best
described using a propagation model where the vote collector is to spread
![]() tickets across all links in the trust graph. Each ticket
corresponds to a capacity value of 1. We associate each node with
a level according to its shortest path distance from the vote collector,
tickets across all links in the trust graph. Each ticket
corresponds to a capacity value of 1. We associate each node with
a level according to its shortest path distance from the vote collector, ![]() .
Node
.
Node ![]() is at level 0. Tickets are distributed to nodes one
level at a time. If a node at level
is at level 0. Tickets are distributed to nodes one
level at a time. If a node at level ![]() has received
has received ![]() tickets
from nodes at level
tickets
from nodes at level ![]() , the node consumes one ticket and
re-distributes the remaining tickets evenly across all its outgoing
links to nodes at level
, the node consumes one ticket and
re-distributes the remaining tickets evenly across all its outgoing
links to nodes at level ![]() , i.e.
, i.e.
![]() . The
capacity value of each link is set to be one plus the number of
tickets distributed on that link. Tickets
are not distributed to links connecting nodes at the same level or from
a higher to lower level. The set of nodes with positive incoming tickets
fall within the vote envelope and thus
represent the entry points.
. The
capacity value of each link is set to be one plus the number of
tickets distributed on that link. Tickets
are not distributed to links connecting nodes at the same level or from
a higher to lower level. The set of nodes with positive incoming tickets
fall within the vote envelope and thus
represent the entry points.
Ticket distribution ensures that all ![]() entry points have positive vote
flows to the vote collector. Therefore, if there exists an edge-independent
path connecting one of the entry points to an outside voter, the corresponding
vote can be collected. We show in Section 5.4 that such a
path exists with good probability. When
entry points have positive vote
flows to the vote collector. Therefore, if there exists an edge-independent
path connecting one of the entry points to an outside voter, the corresponding
vote can be collected. We show in Section 5.4 that such a
path exists with good probability. When ![]() is much smaller than
the number of honest nodes (
is much smaller than
the number of honest nodes (![]() ),
the vote envelope is very small. Therefore, all attack edges reside outside
the envelope, resulting in
),
the vote envelope is very small. Therefore, all attack edges reside outside
the envelope, resulting in
![]() with high probability.
with high probability.
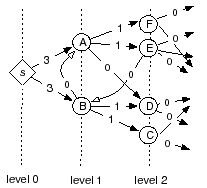 |
Figure 3 illustrates an example of the ticket
distribution process. The vote collector (![]() )
is to distribute
)
is to distribute ![]() =6 tickets among all links.
Each node collects tickets from its lower level neighbors, keeps one
to itself and re-distributes the rest evenly across all
outgoing links to the next level. In Figure 3,
=6 tickets among all links.
Each node collects tickets from its lower level neighbors, keeps one
to itself and re-distributes the rest evenly across all
outgoing links to the next level. In Figure 3, ![]() sends 3 tickets down each of its outgoing links. Since A has more
outgoing links (
sends 3 tickets down each of its outgoing links. Since A has more
outgoing links (![]() ) than its remaining tickets (
) than its remaining tickets (![]() ), link
A
), link
A![]() D receives no tickets. Tickets are not distributed to
links between nodes at the same level (B
D receives no tickets. Tickets are not distributed to
links between nodes at the same level (B![]() A) or to links
from a higher to lower level (E
A) or to links
from a higher to lower level (E![]() B). The final number of
tickets distributed on each link is shown in Figure 3.
Except for immediate outgoing edges from the vote collector, the capacity
value of each link is equal to the amount of tickets it receives plus
one.
B). The final number of
tickets distributed on each link is shown in Figure 3.
Except for immediate outgoing edges from the vote collector, the capacity
value of each link is equal to the amount of tickets it receives plus
one.
Once capacity assignment is done, the task remains
to calculate the set of max-flow paths from the vote collector to
all voters on a given object. It is possible to use existing
max-flow algorithms such as Ford-Fulkerson and Preflow push [4] to compute
vote flows. Unfortunately, these existing algorithms require ![]() running
time to find each vote flow, where
running
time to find each vote flow, where ![]() is the number of edges in the graph.
Since vote aggregation only aims to collect a large fraction of honest votes,
it is not necessary to compute exact max-flow paths.
In particular, we can exploit the structure of capacity assignment to compute a set of
approximate vote flows in
is the number of edges in the graph.
Since vote aggregation only aims to collect a large fraction of honest votes,
it is not necessary to compute exact max-flow paths.
In particular, we can exploit the structure of capacity assignment to compute a set of
approximate vote flows in ![]() time, where
time, where ![]() is the diameter of
the graph. For expander-like networks,
is the diameter of
the graph. For expander-like networks,
![]() . For practical social
networks with a few million users,
. For practical social
networks with a few million users,
![]() .
.
Our approximation algorithm works incrementally by finding one vote flow for a voter
at a time. Unlike the classic Ford-Fulkerson algorithm, our approximation
performs a greedy search from the voter to the collector in
![]() time instead of a breadth-first-search from the collector which
takes
time instead of a breadth-first-search from the collector which
takes ![]() running time. Starting at a voter, the greedy search
strategy attempts to explore a node at a lower level if there exists an
incoming link with positive capacity. Since it is not always possible to find
such a candidate for exploration, the approximation algorithm
allows a threshold (
running time. Starting at a voter, the greedy search
strategy attempts to explore a node at a lower level if there exists an
incoming link with positive capacity. Since it is not always possible to find
such a candidate for exploration, the approximation algorithm
allows a threshold (![]() ) of non-greedy steps which explores nodes at the same
or a higher level. Therefore, the number of nodes visited by the greedy search
is bounded by
) of non-greedy steps which explores nodes at the same
or a higher level. Therefore, the number of nodes visited by the greedy search
is bounded by ![]() . Greedy search works well in practice. For
links within the vote envelope, there is more capacity for lower-level links
and hence greedy search is more likely to find a non-zero capacity path by
exploring lower-level nodes. For links outside the vote envelope, greedy
search results in short paths to one of the vote entry points.
. Greedy search works well in practice. For
links within the vote envelope, there is more capacity for lower-level links
and hence greedy search is more likely to find a non-zero capacity path by
exploring lower-level nodes. For links outside the vote envelope, greedy
search results in short paths to one of the vote entry points.
We introduce an optimization strategy that performs link pruning to reduce the
number of attack edges, thereby reducing the
attack capacity. Pruning is performed prior to link capacity assignment and
its goal is to bound the in-degree of each node to a small value,
![]() . As a result, the number of attack edges is reduced if some
adversarial nodes have more than
. As a result, the number of attack edges is reduced if some
adversarial nodes have more than ![]() incoming edges from honest
nodes. We speculate that the more honest neighbors an adversarial node has,
the easier for it to trick an honest node into trusting it.
Therefore, the number of attack edges in the pruned network
is likely to be smaller than those in the original network. On the other hand,
pruning is unlikely to affect honest users since each honest node only attempts
to cast one vote via one of its incoming links.
incoming edges from honest
nodes. We speculate that the more honest neighbors an adversarial node has,
the easier for it to trick an honest node into trusting it.
Therefore, the number of attack edges in the pruned network
is likely to be smaller than those in the original network. On the other hand,
pruning is unlikely to affect honest users since each honest node only attempts
to cast one vote via one of its incoming links.
Since it is not possible to accurately discern honest identities from
Sybil identities, we give all identities the chance to have their votes
collected. In other words, pruning should never disconnect a node.
The minimally connected network that
satisfies this requirement is a tree rooted at the vote collector. A tree
topology minimizes attack edges but is also overly restrictive for honest nodes because
each node has exactly one path from the collector: if that path is saturated,
a vote cannot be collected. A better tradeoff is
to allow each node to have at most
![]() incoming links
in the pruned network so that honest nodes have a large set of
diverse paths while limiting each adversarial node to only
incoming links
in the pruned network so that honest nodes have a large set of
diverse paths while limiting each adversarial node to only ![]() attack
edges. We examine the specific parameter choice of
attack
edges. We examine the specific parameter choice of ![]() in
Section 7.
in
Section 7.
Pruning each node to have at most ![]() incoming links is done in
several steps. First, we remove all links except those connecting nodes
at a lower level (
incoming links is done in
several steps. First, we remove all links except those connecting nodes
at a lower level (![]() ) to neighbors at the next level (
) to neighbors at the next level (![]() ). Next, we remove
a subset of incoming links at each node so that the remaining links do not
exceed
). Next, we remove
a subset of incoming links at each node so that the remaining links do not
exceed ![]() . In the third step, we add back links removed in step
one for nodes with fewer than
. In the third step, we add back links removed in step
one for nodes with fewer than ![]() incoming links. Finally,
we add one outgoing link back to nodes that have no outgoing links after step
three, with priority given to links going to the next level. By preferentially preserving
links from lower to higher levels, pruning does not interfere with SumUp 's
capacity assignment and flow computation.
incoming links. Finally,
we add one outgoing link back to nodes that have no outgoing links after step
three, with priority given to links going to the next level. By preferentially preserving
links from lower to higher levels, pruning does not interfere with SumUp 's
capacity assignment and flow computation.
This section provides a formal analysis of the security properties of SumUp assuming an expander graph. Various measurement studies have shown that social networks are indeed expander-like [13]. The link pruning optimization does not destroy a graph's expander property because it preserves the level of each node in the original graph.
Our analysis provides bounds on the expected attack capacity, ![]() , and the
expected fraction of votes collected if
, and the
expected fraction of votes collected if ![]() honest users vote. The
average-case analysis assumes that each attack edge is a random link in the
graph. For personalized vote aggregation, the expectation is taken over
all vote collectors which include all honest nodes. In the unfortunate but rare
scenario where an adversarial node is close to the vote collector, we can use
feedback to re-adjust link capacities (Section 6).
honest users vote. The
average-case analysis assumes that each attack edge is a random link in the
graph. For personalized vote aggregation, the expectation is taken over
all vote collectors which include all honest nodes. In the unfortunate but rare
scenario where an adversarial node is close to the vote collector, we can use
feedback to re-adjust link capacities (Section 6).
Theorem 5.1 is for expected capacity per attack edge. In the worse case
when the vote collector is adjacent to some adversarial nodes, the attack
capacity can be a significant fraction of ![]() . Such rare worst case
scenarios are addressed in Section 6.
. Such rare worst case
scenarios are addressed in Section 6.
When ![]() honest users vote on an object, SumUp should ideally
set
honest users vote on an object, SumUp should ideally
set ![]() to be
to be ![]() in order to collect a large fraction of honest votes
on that object. In practice,
in order to collect a large fraction of honest votes
on that object. In practice, ![]() is very small for any object, even a very
popular one. Hence,
is very small for any object, even a very
popular one. Hence,
![]() and the expected capacity per attack
edge is 1. We note that even if
and the expected capacity per attack
edge is 1. We note that even if ![]() , the attack capacity is still
bounded by
, the attack capacity is still
bounded by ![]() per attack edge.
per attack edge.
It is impossible to precisely calculate the number of honest votes (![]() ).
However, we can use the actual number of votes collected by SumUp as a lower
bound estimate for
).
However, we can use the actual number of votes collected by SumUp as a lower
bound estimate for ![]() . Based on this intuition, SumUp adaptively sets
. Based on this intuition, SumUp adaptively sets
![]() according to the number of votes collected for each object. The
adaptation works as follows: For a given object, SumUp starts with a small
initial value for
according to the number of votes collected for each object. The
adaptation works as follows: For a given object, SumUp starts with a small
initial value for ![]() , e.g.
, e.g. ![]() . Subsequently, if the number of
actual votes collected exceeds
. Subsequently, if the number of
actual votes collected exceeds ![]() where
where ![]() is a constant less than
is a constant less than ![]() , SumUp
doubles the
, SumUp
doubles the ![]() in use and re-runs the capacity assignment and vote
collection procedures. The doubling of
in use and re-runs the capacity assignment and vote
collection procedures. The doubling of ![]() continues until the
number of collected votes becomes less than
continues until the
number of collected votes becomes less than ![]() .
.
We show that this adaptive strategy is robust, i.e. the maximum value of the
resulting ![]() will not dramatically exceed
will not dramatically exceed ![]() regardless of the number of bogus votes cast by adversarial nodes.
Since adversarial nodes attempt to cast enough bogus votes to saturate attack
capacity, the number of votes collected is at most
regardless of the number of bogus votes cast by adversarial nodes.
Since adversarial nodes attempt to cast enough bogus votes to saturate attack
capacity, the number of votes collected is at most ![]() where
where
![]() .
The doubling of
.
The doubling of ![]() stops when the number of collected votes is less than
stops when the number of collected votes is less than
![]() . Therefore, the maximum value of
. Therefore, the maximum value of ![]() that stops
the adaptation is one that satisfies the following inequality:
that stops
the adaptation is one that satisfies the following inequality:
Since
![]() , the adaptation terminates with
, the adaptation terminates with
![]() . As
. As
![]() ,
we derive
,
we derive
![]() . The adaptive strategy
doubles
. The adaptive strategy
doubles ![]() every iteration, hence it overshoots by at most a factor of
two. Therefore, the resulting
every iteration, hence it overshoots by at most a factor of
two. Therefore, the resulting ![]() found is
found is
![]() . As we can see, the attacker can only affect the
. As we can see, the attacker can only affect the
![]() found by an additive factor of
found by an additive factor of ![]() . Since
. Since ![]() is small, the
attacker has negligible influence on the
is small, the
attacker has negligible influence on the ![]() found.
found.
The previous analysis is done for the expected case with random attack edges.
Even in a worst case scenario where some attack edges are very
close to the vote collector, the adaptive strategy is still resilient against manipulation.
In the worst case scenario, the attack capacity is proportional to ![]() ,
i.e.
,
i.e.
![]() .
Since no vote aggregation scheme can defend
against an attacker who controls a majority of immediate links from the vote
collector, we are only interested in the case where
.
Since no vote aggregation scheme can defend
against an attacker who controls a majority of immediate links from the vote
collector, we are only interested in the case where ![]() . The
adaptive strategy stops increasing
. The
adaptive strategy stops increasing ![]() when
when
![]() , thus resulting in
, thus resulting in
![]() . As we can see,
. As we can see,
![]() must be greater than
must be greater than ![]() to prevent the attacker from causing SumUp
to increase
to prevent the attacker from causing SumUp
to increase ![]() to infinity. Therefore, we set
to infinity. Therefore, we set ![]() by default.
by default.
The basic design presented in Section 5 does not address the worst case
scenario where ![]() could be much higher than
could be much higher than ![]() . Furthermore, the basic
design only bounds the number of bogus votes collected on a single object. As
a result, adversaries can still cast up to
. Furthermore, the basic
design only bounds the number of bogus votes collected on a single object. As
a result, adversaries can still cast up to ![]() bogus votes on every
object in the system. In this section, we utilize feedback to address both
problems.
bogus votes on every
object in the system. In this section, we utilize feedback to address both
problems.
SumUp maintains a penalty value for each link and uses the
penalty in two ways. First, we adjust each link's capacity assignment so that
links with higher penalties have lower capacities. This helps reduce ![]() when some attack edges happen to be close to the vote collector. Second, we
eliminate links whose penalties have exceeded a certain threshold. Therefore,
if adversaries continuously misbehave, the attack capacity will drop
below
when some attack edges happen to be close to the vote collector. Second, we
eliminate links whose penalties have exceeded a certain threshold. Therefore,
if adversaries continuously misbehave, the attack capacity will drop
below ![]() over time. We describe how SumUp calculates and uses penalty
in the rest of the section.
over time. We describe how SumUp calculates and uses penalty
in the rest of the section.
The vote collector can choose to associate negative feedback with voters if he believes their votes are malicious. Feedback may be performed for a very small set of objects-for example, when the collector finds out that an object is a bogus file or a virus.
SumUp keeps track of a penalty value, ![]() , for each link
, for each link ![]() in the trust network. For each voter receiving negative feedback, SumUp
increments the penalty values for all links along the path to that voter.
Specifically, if the link being penalized has capacity
in the trust network. For each voter receiving negative feedback, SumUp
increments the penalty values for all links along the path to that voter.
Specifically, if the link being penalized has capacity ![]() ,
SumUp increments the link's penalty by
,
SumUp increments the link's penalty by ![]() . Scaling the increment
by
. Scaling the increment
by ![]() is intuitive; links with high capacities are close to the vote
collector and hence are more likely to propagate some bogus votes even if they
are honest links. Therefore, SumUp imposes a lesser penalty on
high capacity links.
is intuitive; links with high capacities are close to the vote
collector and hence are more likely to propagate some bogus votes even if they
are honest links. Therefore, SumUp imposes a lesser penalty on
high capacity links.
It is necessary to penalize all links along the path instead of just the immediate link to the voter because that voter might be a Sybil identity created by some other attacker along the path. Punishing a link to a Sybil identity is useless as adversaries can easily create more such links. This way of incorporating negative feedback is inspired by Ostra [18]. Unlike Ostra, SumUp uses a customized flow network per vote collector and only allows the collector to incorporate feedback for its associated network in order to ensure that feedback is always trustworthy.
The capacity assignment in Section 5.1 lets each node distribute incoming tickets evenly across all outgoing links. In the absence of feedback, it is reasonable to assume that all outgoing links are equally trustworthy and hence to assign them the same number of tickets. When negative feedback is available, a node should distribute fewer tickets to outgoing links with higher penalty values. Such adjustment is particularly useful in circumstances where adversaries are close to the vote collector and hence might receive a large number of tickets.
The goal of capacity adjustment is to compute a weight,
![]() , as a function of the link's penalty. The
number of tickets a node distributes to its outgoing link
, as a function of the link's penalty. The
number of tickets a node distributes to its outgoing link ![]() is
proportional to the link's weight, i.e.
is
proportional to the link's weight, i.e.
![]() .
The question then becomes how to compute
.
The question then becomes how to compute ![]() . Clearly, a link with a high penalty value
should have a smaller weight, i.e.
. Clearly, a link with a high penalty value
should have a smaller weight, i.e. ![]()
![]()
![]() if
if ![]()
![]()
![]() .
Another desirable property is that if the penalties
on two links increase by the same amount,
the ratio of their weights remains unchanged. In other words,
the weight function should satisfy:
.
Another desirable property is that if the penalties
on two links increase by the same amount,
the ratio of their weights remains unchanged. In other words,
the weight function should satisfy:
![]() . This requirement matches our intuition that
if two links have accumulated the same amount of additional penalties over a period
of time, the relative capacities between them should remain the same.
Since the exponential function satisfies both requirements, we
use
. This requirement matches our intuition that
if two links have accumulated the same amount of additional penalties over a period
of time, the relative capacities between them should remain the same.
Since the exponential function satisfies both requirements, we
use
![]() by default.
by default.
Capacity adjustment cannot reduce the attack capacity to below ![]() since each
link is assigned a minimum capacity value of one. To further reduce
since each
link is assigned a minimum capacity value of one. To further reduce ![]() , we
eliminate those links that received high amounts of negative feedback.
, we
eliminate those links that received high amounts of negative feedback.
We use a heuristic for link elimination: we remove a link if its penalty exceeds a threshold value. We use a default threshold of five. Since we already prune the trust network (Section 5.3) before performing capacity assignment, we add back a previously pruned link if one exists after eliminating an incoming link. The reason why link elimination is useful can be explained intuitively: if adversaries continuously cast bogus votes on different objects over time, all attack edges will be eliminated eventually. On the other hand, although an honest user might have one of its incoming links eliminated because of a downstream attacker casting bad votes, he is unlikely to experience another elimination due to the same attacker since the attack edge connecting him to that attacker has also been eliminated. Despite this intuitive argument, there always exist pathological scenarios where link elimination affects some honest users, leaving them with no voting power. To address such potential drawbacks, we re-enact eliminated links at a slow rate over time. We evaluate the effect of link elimination in Section 7.
|
In this section, we demonstrate SumUp 's security property using real-world social networks and voting traces. Our key results are:
For the evaluation, we use a number of network datasets from different online social networking sites [17] as well as a synthetic social network [24] as the underlying trust network. SumUp works for different types of trust networks as long as an attacker cannot obtain many attack edges easily in those networks. Table 1 gives the statistics of various datasets. For undirected networks, we treat each link as a pair of directed links. Unless explicitly mentioned, we use the YouTube network by default.
To evaluate the Sybil-resilience of SumUp , we inject ![]() attack edges
by adding
attack edges
by adding ![]() adversarial nodes each with links from
adversarial nodes each with links from ![]() random honest nodes in the network. The attacker always casts the maximum bogus
votes to saturate his capacity. Each experimental run
involves a randomly chosen vote collector and a subset of nodes which serve as honest
voters. SumUp adaptively adjusts
random honest nodes in the network. The attacker always casts the maximum bogus
votes to saturate his capacity. Each experimental run
involves a randomly chosen vote collector and a subset of nodes which serve as honest
voters. SumUp adaptively adjusts ![]() using an initial
value of
using an initial
value of ![]() and
and ![]() . By default, the
threshold of allowed non-greedy steps is
. By default, the
threshold of allowed non-greedy steps is ![]() . We plot the average
statistic across five experimental runs in all graphs. In
Section 7.6, we apply SumUp on the real world voting trace of
Digg to examine how SumUp can be used to resist Sybil attacks in the wild.
. We plot the average
statistic across five experimental runs in all graphs. In
Section 7.6, we apply SumUp on the real world voting trace of
Digg to examine how SumUp can be used to resist Sybil attacks in the wild.
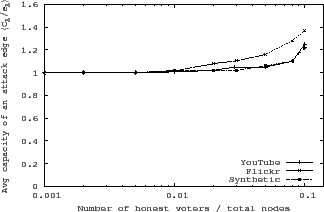
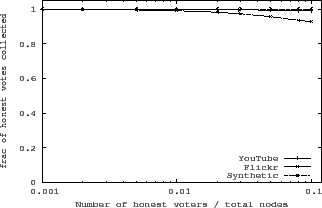
The main goal of SumUp is to limit attack capacity while allowing
honest users to vote. Figure 4 shows that the average attack
capacity per attack edge remains close to ![]() even when the number of honest
voters approaches
even when the number of honest
voters approaches ![]() . Furthermore, as shown in
Figure 5, SumUp manages to collect more than
. Furthermore, as shown in
Figure 5, SumUp manages to collect more than
![]() of all honest votes in all networks. Link pruning is disabled in these
experiments. The three networks under evaluation have very different sizes and
degree distributions (see Table 1). The fact that all three
networks exhibit similar performance suggests that SumUp is robust against
the topological details. Since SumUp adaptively sets
of all honest votes in all networks. Link pruning is disabled in these
experiments. The three networks under evaluation have very different sizes and
degree distributions (see Table 1). The fact that all three
networks exhibit similar performance suggests that SumUp is robust against
the topological details. Since SumUp adaptively sets ![]() in these
experiments, the results also confirm that adaptation works well in finding a
in these
experiments, the results also confirm that adaptation works well in finding a
![]() that can collect most of the honest votes without significantly increasing
attack capacity. We point out that the results in Figure 4
correspond to a random vote collector. For an unlucky vote collector close to
an attack edge, he may experience a much larger than average attack capacity.
In personalized vote collection, there are few unlucky collectors. These
unlucky vote collectors need to use their own feedback on bogus votes to reduce
attack capacity.
that can collect most of the honest votes without significantly increasing
attack capacity. We point out that the results in Figure 4
correspond to a random vote collector. For an unlucky vote collector close to
an attack edge, he may experience a much larger than average attack capacity.
In personalized vote collection, there are few unlucky collectors. These
unlucky vote collectors need to use their own feedback on bogus votes to reduce
attack capacity.
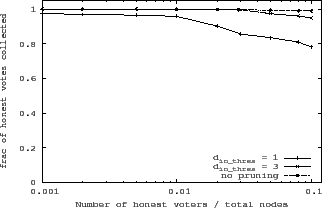
Benefits of pruning:
The link pruning optimization, introduced in Section 5.3,
further reduces the attack capacity by capping the number of attack edges an
adversarial node can have. As Figure 6 shows, pruning
does not affect the fraction of honest votes collected if the threshold
![]() is greater than 3. Figure 6 represents data from
the YouTube network and the results for other networks are similar.
SumUp uses the default threshold (
is greater than 3. Figure 6 represents data from
the YouTube network and the results for other networks are similar.
SumUp uses the default threshold (![]() ) of 3.
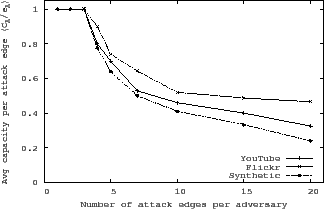
Figure 7 shows that the average attack capacity is
greatly reduced when adversarial nodes have more than 3 attack edges. Since
pruning attempts to restrict each node to at most 3 incoming links,
additional attack edges are excluded from vote flow computation.
) of 3.
Figure 7 shows that the average attack capacity is
greatly reduced when adversarial nodes have more than 3 attack edges. Since
pruning attempts to restrict each node to at most 3 incoming links,
additional attack edges are excluded from vote flow computation.
 |
 |
 |
 |
 |
 |
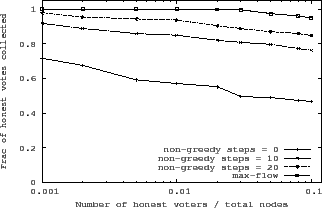
SumUp uses a fast greedy algorithm to calculate approximate max vote flows to
voters. Greedy search enables SumUp to collect a majority of votes while using a
small threshold (![]() ) of non-greedy steps. Figure 8
shows the fraction of honest votes collected for the pruned YouTube graph. As we can
see, with a small threshold of 20, the fraction of votes collected is more than
) of non-greedy steps. Figure 8
shows the fraction of honest votes collected for the pruned YouTube graph. As we can
see, with a small threshold of 20, the fraction of votes collected is more than ![]() .
Even when disallowing non-greedy steps completely, SumUp
manages to collect
.
Even when disallowing non-greedy steps completely, SumUp
manages to collect ![]() of votes.
of votes.
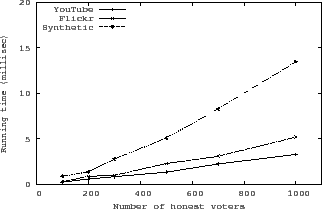
Figure 9 shows the running time of greedy-search for different
networks. The experiments are performed on a single machine with an AMD
Opteron 2.5GHz CPU and 8GB memory. SumUp takes around ![]() ms to collect
ms to collect
![]() votes from a single vote collector on YouTube and Flickr. The synthetic network incurs
more running time as its links are more congested than those in YouTube and
Flickr. The average non-greedy steps taken in the synthetic network is
votes from a single vote collector on YouTube and Flickr. The synthetic network incurs
more running time as its links are more congested than those in YouTube and
Flickr. The average non-greedy steps taken in the synthetic network is ![]() as opposed to
as opposed to ![]() for the YouTube graph. Greedy-search dramatically reduces
the flow computation time. As a comparison, the Ford-Fulkerson
max-flow algorithm requires
for the YouTube graph. Greedy-search dramatically reduces
the flow computation time. As a comparison, the Ford-Fulkerson
max-flow algorithm requires ![]() seconds to collect 1000 votes for the YouTube graph.
seconds to collect 1000 votes for the YouTube graph.
 |
SybilLimit is a node admission protocol that leverages the trust network to
allow an honest node to accept other honest nodes with high probability. It
bounds the number of Sybil nodes accepted to be ![]() . We can apply
SybilLimit for vote aggregation by letting each vote collector compute a fixed
set of accepted users based on the trust network. Subsequently, a vote is
collected if and only if it comes from one of the accepted users. In contrast,
SumUp does not calculate a fixed set of allowed users; rather, it dynamically
determines the set of voters that count toward each object. Such dynamic
calculation allows SumUp to settle on a small
. We can apply
SybilLimit for vote aggregation by letting each vote collector compute a fixed
set of accepted users based on the trust network. Subsequently, a vote is
collected if and only if it comes from one of the accepted users. In contrast,
SumUp does not calculate a fixed set of allowed users; rather, it dynamically
determines the set of voters that count toward each object. Such dynamic
calculation allows SumUp to settle on a small ![]() while still
collecting most of the honest votes. A small
while still
collecting most of the honest votes. A small ![]() allows SumUp to bound attack
capacity by
allows SumUp to bound attack
capacity by ![]() .
.
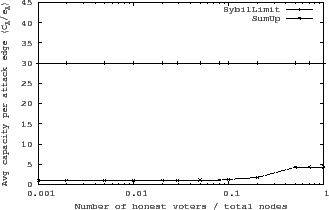
Figure 10 compares the average attack capacity
in SumUp to that of SybilLimit for the un-pruned YouTube network. The attack capacity in
SybilLimit refers to the number of Sybil nodes that are accepted by the vote
collector. Since SybilLimit aims to accept nodes instead of votes, its attack
capacity remains ![]() regardless of the number of actual honest
voters. Our implementation of SybilLimit uses the optimal set of parameters
(
regardless of the number of actual honest
voters. Our implementation of SybilLimit uses the optimal set of parameters
(![]() ,
, ![]() ) we determined manually. As Figure 10
shows, while SybilLimit allows
) we determined manually. As Figure 10
shows, while SybilLimit allows ![]() bogus votes per attack edge,
SumUp results in approximately 1 vote per attack edge when the fraction of honest voters
is less than
bogus votes per attack edge,
SumUp results in approximately 1 vote per attack edge when the fraction of honest voters
is less than ![]() . When all nodes vote, SumUp leads to much lower attack
capacity than SybilLimit even though both have the same
. When all nodes vote, SumUp leads to much lower attack
capacity than SybilLimit even though both have the same ![]() asymptotic
bound per attack edge. This is due to two reasons. First, SumUp 's bound of
asymptotic
bound per attack edge. This is due to two reasons. First, SumUp 's bound of
![]() in Theorem 5.1 is a loose upper bound of the actual average
capacity. Second, since links pointing to lower-level nodes are not eligible
for ticket distribution, many incoming links of an adversarial nodes have zero
tickets and thus are assigned capacity of one.
in Theorem 5.1 is a loose upper bound of the actual average
capacity. Second, since links pointing to lower-level nodes are not eligible
for ticket distribution, many incoming links of an adversarial nodes have zero
tickets and thus are assigned capacity of one.
 |
We evaluate the benefits of capacity adjustment and link elimination when
the vote collector provides feedback on the bogus votes collected.
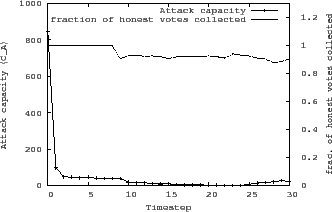
Figure 11 corresponds to the worst case scenario
where one of the vote collector's four outgoing links is an attack edge.
At every time step, there are 400 random honest users voting on an object and
the attacker also votes with its maximum capacity.
When collecting votes on the first object at time step 1, adaption results in
![]() because
because
![]() . Therefore, the attacker manages to cast
. Therefore, the attacker manages to cast
![]() votes and outvote honest users. After incorporating the vote collector's
feedback after the first time step, the adjacent attack edge incurs a penalty
of
votes and outvote honest users. After incorporating the vote collector's
feedback after the first time step, the adjacent attack edge incurs a penalty
of ![]() which results in drastically reduced
which results in drastically reduced ![]() (
(![]() ). If the vote
collector continues to provide feedback on malicious votes, 90% of
attack edges are eliminated after only 12 time steps. After another 10 time
steps, all attack edges are eliminated, reducing
). If the vote
collector continues to provide feedback on malicious votes, 90% of
attack edges are eliminated after only 12 time steps. After another 10 time
steps, all attack edges are eliminated, reducing ![]() to zero. However,
because of our decision to slowly add back eliminated links, the attack
capacity doesn't remains at zero forever. Figure 11 also shows
that link elimination has little effects on honest nodes as the fraction of
honest votes collected always remains above
to zero. However,
because of our decision to slowly add back eliminated links, the attack
capacity doesn't remains at zero forever. Figure 11 also shows
that link elimination has little effects on honest nodes as the fraction of
honest votes collected always remains above ![]() .
.
|
In this section, we ask the following questions: Is there evidence of Sybil attacks in real world content voting systems? Can SumUp successfully limit bogus votes from Sybil identities? We apply SumUp to the voting trace and social network crawled from Digg to show the real world benefits of SumUp .
Digg [1] is a popular news aggregation site where any
registered user can submit an article for others to vote on. A
positive vote on an article is called a digg. A negative vote is
called a bury. Digg marks a subset of submitted articles as
``popular'' articles and displays them on its front page. In
subsequent discussions, we use the terms popular or popularity only to refer to the popularity status of an article
as marked by Digg. A Digg user can create a ``follow'' link to another user if
he wants to browse all articles submitted by that user.
We have crawled Digg to obtain
the voting trace on all submitted articles since Digg's launch
(2004/12/01-2008/09/21) as well as the complete ``follow'' network
between users. Unfortunately, unlike diggs, bury data is only
available as a live stream. Furthermore, Digg does not reveal the
user identity that cast a bury, preventing us from evaluating
SumUp 's feedback mechanism. We have been streaming bury data since
2008/08/13. Table 2 shows the basic statistics of
the Digg ``follow'' network and the two voting traces, one with bury
data and one without. Although the strongly connected component (SCC)
consists of only ![]() of total nodes,
of total nodes, ![]() of votes come from nodes
in the SCC.
of votes come from nodes
in the SCC.
 |
 |
There is enormous incentive for an attacker to get a submitted article marked as popular, thus promoting it to the front page of Digg which has several million page views per day. Our goal is to apply SumUp on the voting trace to reduce the number of successful attacks on the popularity marking mechanism of Digg. Unfortunately, unlike experiments done in Section 7.2 and Section 7.5, there is no ground truth about which Digg users are adversaries. Instead, we have to use SumUp itself to find evidence of attacks and rely on manual sampling and other types of data to cross check the correctness of results.
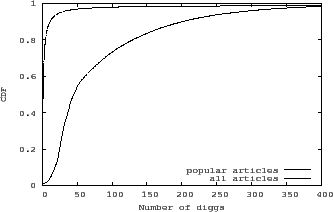
Digg's popularity ranking algorithm is intentionally not revealed to the public in order to mitigate gaming of the system. Nevertheless, we speculate that the number of diggs is a top contributor to an article's popularity status. Figure 12 shows the distribution of the number of diggs an article received before it was marked as popular. Since more than 90% of popular articles are marked as such within 24 hours after submission, we also plot the number of diggs received within 24 hours of submission for all articles. The large difference between the two distributions indicates that the number of diggs plays an important role in determining an article's popularity status.
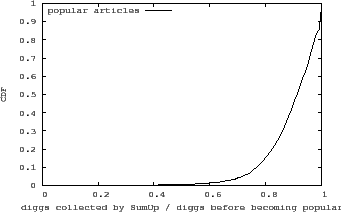
Instead of simply adding up the actual number of diggs, what if Digg uses SumUp to collect all votes on an article? We use the identity of Kevin Rose, the founder of Digg, as the vote collector to aggregate all diggs on an article before it is marked as popular. Figure 13 shows the distribution of the fraction of votes collected by SumUp over all diggs before an article is marked as popular. Our previous evaluation on various network topologies suggests that SumUp should be able to collect at least 90% of all votes. However, in Figure 13, there are a fair number of popular articles with much fewer than the expected fraction of diggs collected. For example, SumUp only manages to collect less than 50% of votes for 0.5% of popular articles. We hypothesize that the reason for collecting fewer than the expected votes is due to real world Sybil attacks.
Since there is no ground truth data to verify whether few collected diggs are indeed
the result of attacks, we resort to manual inspection. We classify a popular
article as suspicious if its fraction of diggs collected is less than a given
threshold. Table 3 shows the result of manually inspecting
30 random articles out of all suspicious articles. The random samples for
different thresholds are chosen independently. There are a number of obvious
bogus articles such as advertisements, phishing articles and obscure political
opinions. Of the remaining, we find many of them have an unusually large
fraction (![]() 30%) of new voters who registered on the same day as the
article's submission time. Some articles also have very few total diggs since
becoming popular, a rare event since an article typically receives hundreds of
votes after being shown on the front page of Digg. We find no obvious evidence
of attack for roughly half of the sampled articles. Interviews with Digg
attackers [10] reveal that, although there is a fair amount of
attack activities on Digg, attackers do not usually promote obviously bogus
material. This is likely due to Digg being a highly monitored system with
fewer than a hundred articles becoming popular every day. Instead, attackers
try to help paid customers promote normal or even good content
or to boost their profiles within the Digg community.
30%) of new voters who registered on the same day as the
article's submission time. Some articles also have very few total diggs since
becoming popular, a rare event since an article typically receives hundreds of
votes after being shown on the front page of Digg. We find no obvious evidence
of attack for roughly half of the sampled articles. Interviews with Digg
attackers [10] reveal that, although there is a fair amount of
attack activities on Digg, attackers do not usually promote obviously bogus
material. This is likely due to Digg being a highly monitored system with
fewer than a hundred articles becoming popular every day. Instead, attackers
try to help paid customers promote normal or even good content
or to boost their profiles within the Digg community.
As further evidence that a lower than expected fraction of collected diggs signals a possible attack, we examine Digg's bury data for articles submitted after 2008/08/13, of which 5794 are marked as popular. Figure 14 plots the correlation between the average number of bury votes on an article after it became popular vs. the fraction of the diggs SumUp collected before it was marked as popular. As Figure 14 reveals, the higher the fraction of diggs collected by SumUp , the fewer bury votes an article received after being marked as popular. Assuming most bury votes come from honest users that genuinely dislike the article, a large number of bury votes is a good indicator that the article is of dubious quality.
What are the voting patterns for suspicious articles? Since ![]() diggs come from nodes within the SCC, we expect only
diggs come from nodes within the SCC, we expect only ![]() of
diggs to originate from the rest of the network, which mostly consists of nodes
with no incoming follow links. For most suspicious articles, the
reason that SumUp collecting fewer than expected diggs is due to an
unusually large fraction of votes coming from outside the SCC
component. Since Digg's popularity marking algorithm is not known,
attackers might not bother to connect their Sybil
identities to the SCC or to each other. Interestingly, we found 5
suspicious articles with sophisticated voting patterns where one voter
is linked to many identities (
of
diggs to originate from the rest of the network, which mostly consists of nodes
with no incoming follow links. For most suspicious articles, the
reason that SumUp collecting fewer than expected diggs is due to an
unusually large fraction of votes coming from outside the SCC
component. Since Digg's popularity marking algorithm is not known,
attackers might not bother to connect their Sybil
identities to the SCC or to each other. Interestingly, we found 5
suspicious articles with sophisticated voting patterns where one voter
is linked to many identities (![]() ) that also vote on the same
article. We believe the many identities behind that single voter are
likely Sybil identities because those identities were all created on
the same day as the article's submission. Additionally, those
identities all have similar usernames.
) that also vote on the same
article. We believe the many identities behind that single voter are
likely Sybil identities because those identities were all created on
the same day as the article's submission. Additionally, those
identities all have similar usernames.
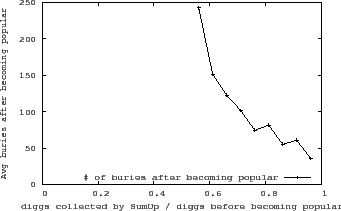 |
Even though SumUp is presented in a centralized setup such as a content-hosting Web site, it can also be implemented in a distributed fashion in order to rank objects in peer-to-peer systems. We outline one such distributed design for SumUp . In the peer-to-peer environment, each node and its corresponding user is identified by a self-generated public key. A pair of users create a trust link relationship between them by signing the trust statement with their private keys. Nodes gossip with each other or perform a crawl of the network to obtain a complete trust network between any pair of public keys. This is different from Ostra [18] and SybilLimit [26] which address the harder problem of decentralized routing where each user only knows about a small neighborhood around himself in the trust graph. In the peer-to-peer setup, each user naturally acts as his own vote collector to aggregate votes and compute a personalized ranking of objects. To obtain all votes on an object, a node can either perform flooding (like in Credence [25]) or retrieve votes stored in a distributed hash table. In the latter case, it is important that the DHT itself be resilient against Sybil attacks. Recent work on Sybil-resilient DHTs [14,5] addresses this challenge.
This paper presented SumUp , a content voting system that leverages the trust network among users to defend against Sybil attacks. By using the technique of adaptive vote flow aggregation, SumUp aggregates a collection of votes with strong security guarantees: with high probability, the number of bogus votes collected is bounded by the number of attack edges while the number of honest votes collected is high. We demonstrate the real-world benefits of SumUp by evaluating it on the voting trace of Digg: SumUp detected many suspicious articles marked as ``popular'' by Digg. We have found strong evidence of Sybil attacks on many of these suspicious articles.
We thank Alan Mislove and Krishna Gummadi for making their social network traces publicly available. We are grateful to Krishna Gummadi (our shepard), Haifeng Yu, Aditya Dhananjay, Michael Paik, Eric Hielscher, and the anonymous reviewers whose comments have helped us improve the paper. This work is supported by NSF CAREER Award CNS-0747052.
This document was generated using the LaTeX2HTML translator Version 2002-2-1 (1.71)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -split 0 -show_section_numbers -local_icons -no_navigation paper.tex
The translation was initiated by Nguyen Tran on 2009-02-27