Xiao Zhang Sandhya Dwarkadas Girts Folkmanis Kai Shen
Department of Computer Science, University of Rochester
1 Introduction
Hardware counters are commonplace on modern processors, providing detailed information such as instruction mix, rate of execution (instructions per cycle), branch (control flow) prediction accuracy, and memory access behaviors (including miss rates at each level of the memory hierarchy as well as bus activity). These counters were originally provided for hardware verification and debugging purposes. Recently, they have also been used to support a variety of tasks concerning software systems and applications, including adaptive CPU scheduling [2,6,11,15,18], performance monitoring/debugging [1,5,19], workload pattern identification [4,7], and adaptive application self-management [8].
Except for guiding CPU scheduling, so far the operating system's involvement in managing the processor counter statistics has been limited. Typically the OS does little more than expose the statistics to user applications. Additional efforts mostly concern the presentation of counter statistics. For instance, the PAPI project [5] proposed a portable cross-platform interface that applications could use to access hardware events of interests, which hides the differences and details of each hardware platform from the user.
In this paper, we argue that processor hardware counters are a first-class resource, warranting general OS utilization and requiring direct OS management. Our discussion is within the context of the increasing ubiquity and variety of hardware resource-sharing multiprocessors. Examples are memory bus-sharing symmetric multiprocessors (SMPs), L2 cache-sharing chip multiprocessors (CMPs), and simultaneous multithreading (SMTs), where many hardware resources including even the processor counter registers are shared.
Processor metrics can identify hardware resource contention on resource-sharing multiprocessors in addition to providing useful information on application execution behavior. We reinforce existing results to demonstrate multiple uses of counter statistics in an online continuous fashion. We show (via modification of the Linux scheduler) that on-line processor hardware metrics-based simple heuristics may improve both the performance and the fairness of CPU scheduling. We also demonstrate the effectiveness of using hardware metrics for application-level online workload modeling.
A processor usually has a limited number of counter registers to which a much larger number of hardware metrics can map. Different uses such as system-level functions (e.g., CPU scheduling) and user-level tasks (e.g., workload profiling) may desire conflicting sets of processor counter statistics at the same time. We demonstrate that such simultaneous use is possible via time-division multiplexing.
Finally, the utilization of processor counter statistics may bring security risks. For instance, a non-privileged user application may learn execution characteristics of other applications when processor counters report combined hardware metrics of two resource-sharing sibling processors. We argue that the OS should be aware of such risks and minimize them when needed.
2 Counter Statistics Usage Case Studies
We present two usage case studies of processor hardware counter statistics: operating system CPU scheduling and online workload modeling. In both cases, the processor counter statistics are utilized in a continuous online fashion (as opposed to ad hoc infrequent uses).
2.1 Efficient and Fair CPU Scheduling
It is well known that different pairings of tasks on resource-sharing multiprocessors may result in different levels of resource contention and thus differences in performance. Resource contention also affects fairness since a task may make less progress under higher resource contention (given the same amount of CPU time). A fair scheduler should therefore go beyond allocating equal CPU time to tasks. A number of previous studies [2,6,18,11,10,15] have explored adaptive CPU scheduling to improve system performance and some have utilized processor hardware statistics. The case for utilizing processor counter statistics in general CPU scheduling can be strengthened if a counter-based simple heuristic improves both scheduling performance and fairness.
In this case study, we consider two simple scheduling policies using hardware counter statistics. The first (proposed by Fedorova et al. [11]) uses instruction-per-cycle (IPC) as an indicator of whether a task is CPU-intensive (high IPC) or memory-access-intensive (low IPC). The IPC scheduler tries to pair high-IPC tasks with low-IPC tasks to reduce resource contention. The second is a new policy that directly measures the usage on bottleneck resources and then matches each high resource-usage task with a low resource-usage task on resource-sharing sibling processors. In the simple case of SMPs, a single resource -- the memory bus -- is the bottleneck.
Our implementation, based on the Linux 2.6.10 kernel, requires only a small change to the existing CPU scheduler. We monitor the bus utilization (or IPC) of each task using hardware counter statistics. During each context switch, we try to choose one ready task whose monitored bus utilization (IPC) is complementary to the task or tasks currently running on the other CPU or CPUs (we use last-value prediction as a simple yet reasonable predictor, although other more sophisticated prediction schemes [9] could easily be incorporated). Note that our implementation does not change the underlying Linux scheduler's assignation of equal CPU time to CPU-bound tasks within each scheduling epoch. By smoothing out overall resource utilization over time, however, the scheduler may improve both fairness and performance, since with lower variation in resource contention, tasks tend to make more deterministic progress.
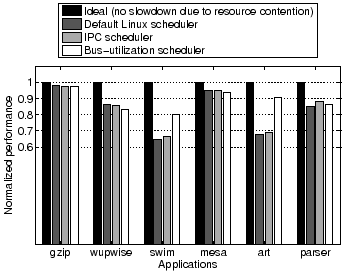
For experiments on SPEC-CPU2000 applications, we run gzip, parser, and swim (low, medium, and high bus utilization, respectively) on one CPU, and mesa, wupwise, and art (again, low, medium, and high bus utilization, respectively) on the other CPU. In this scenario, ideally, complementary tasks (high-low, medium-medium) should be executed simultaneously in order to smooth out resource demand. We define the normalized application performance as "execution time under ideal condition
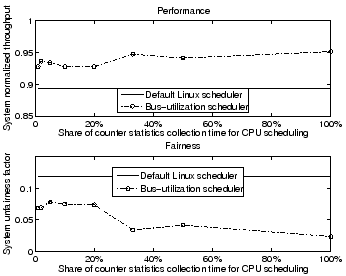
We define two metrics to quantify the overall system performance and fairness. The system normalized performance metric is defined as the geometric mean of each application's normalized performance. The unfairness factor metric is defined as the coefficient of variation (standard deviation divided by the mean) of all application performance. Ideally, the system normalized performance should be 1 (i.e., no slowdown due to resource contention) and the unfairness factor 0 (i.e., all applications are affected by exactly the same amount). Compared to the default Linux scheduler, the bus-utilization scheduler improves system performance by 7.9% (from 0.818 to 0.883) and reduces unfairness by 58% (from 0.178 to 0.074). Compared to the IPC scheduler, it improves system performance by 6.5% and reduces unfairness by 55%. The IPC scheduler is inferior to the bus-utilization scheduler because IPC does not always accurately reflect the utilization of the shared bus resource.
 |
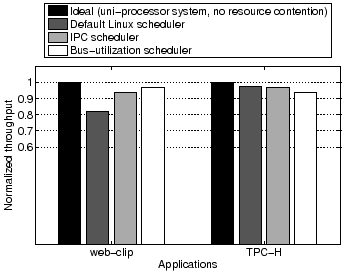
We also experimented with counter statistics-assisted CPU scheduling using two server applications. The first is the Apache 2.0.44 web server hosting a set of video clips, synthetically generated following the file size and access popularity distribution of the 1998 World Cup workload [3]. We call this workload web-clip. The second application is the TPC-H benchmark running on the MySQL 5.0.17 database. We choose a subset of 17 relatively short TPC-H queries appropriate for an interactive server workload. The datasets we generated for the two workloads are at 316MB and 362MB respectively. For our experiments, we first warmup the server memory so that no disk I/O is performed during performance measurement. Figure 2 presents server throughput normalized to that when running alone without resource contention (ideal). Compared to the default Linux scheduler, the bus-utilization scheduler improves system throughput by 6.4% (from 0.894 to 0.952) and reduces unfairness by 80% (from 0.118 to 0.024). In this case, the IPC scheduler's performance is close to that of the bus-utilization scheduler, with system throughput at 0.951 and an unfairness factor of 0.025.
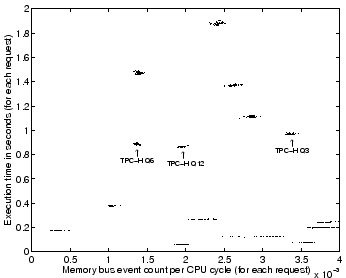
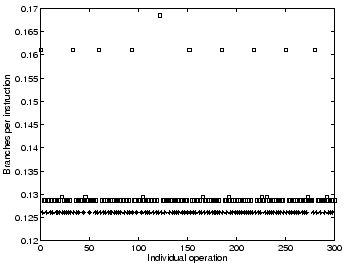
In a server system, online continuous collection of per-request information can help construct workload models, classify workload patterns, and support performance projections (as shown in Magpie [4]). Past work has mostly focused on the collection of software metrics like request execution time. We argue that better server request modeling may be attained by adding processor hardware counter statistics. We support this argument using a simple experiment. We ran our TPC-H workload for 10 minutes and monitored around 1000 requests. For each request, we collected its execution time and memory bus utilization (measured using processor hardware counters). The per-request plot of these two metrics is presented in Figure 3.
As can be seen from our result, the counter statistics can assist request classification. For instance, while TPC-H query Q3, Q6, and Q12 all exhibit similar execution time, they vary in their need for memory bandwidth, making it easy to distinguish them if this statistic is used. Further, hardware statistics can also help project performance on new computing platforms. For example, by migrating to a machine with a faster processor but identical memory system, a memory-access-heavy request (TPC-H Q3) would show less performance improvement than one with lower bandwidth requirements (TPC-H Q6). Software metrics alone may not provide such differentiation.
 |
3 Managing Resource Competition
Although many hardware metrics can be configured for observation, a processor usually has a limited number of counter registers to which the hardware metrics must map. Additionally, the configurations of some counter metrics are in conflict with each other and thus these metrics cannot be observed together. Existing mechanisms for processor counter statistics collection [1,20,17] do not support competing statistics collections simultaneously (i.e., during the same period of program execution).
Competition for counter statistics can result from several scenarios. Since system functions typically require continuous collection of a specific set of hardware metrics over all program executions, any user-initiated counter statistics collection may conflict with them. In addition, on some resource-sharing hardware processors (particularly SMTs), sibling processors share the same set of counter registers. Possible resource competition may arise when programs on sibling processors desire conflicting counter statistics simultaneously. Finally, a single application may request the use of conflicting counter statistics, potentially for different purposes.
In such contexts, processor counter statistics should be multiplexed for simultaneous competing uses and carefully managed for effective and fair utilization. The OS's basic mechanism to resolve resource competition is time-division multiplexing (alternating different counter register setups at interrupts) according to certain allocation shares. Time-division multiplexing of counter statistics has already been employed in SGI IRIX to resolve internal conflicts among multiple hardware metrics requested by a single user. Our focus here is to manage the competition between system-level functions and application-level tasks from multiple users.
The time-division multiplexing of hardware counter statistics is viable only when uses of counter statistics can still be effective (or sustain only slight loss of effectiveness) with partial-time sampled program execution statistics. Our allocation policy consists of two parts. First, the fraction of counter access time apportioned to system-level functions must be large enough to fulfill intended objectives but as small as possible to allow sufficient access to user-level tasks. Since the system-level functions are deterministic, we can statically provision a small but sufficiently effective allocation share for them. Second, when multiple user applications desire conflicting hardware counter statistics simultaneously (e.g., when they run on sibling processors that share hardware counter registers), they divide the remaining counter statistics access time using any fair-share scheduler. We recognize that in order to be effective, certain applications might require complete monopoly of the hardware counters (e.g., when a performance debugger must find out exactly where each cycle of the debugged program goes [1]). The superuser may change the default allocation policy in such cases.
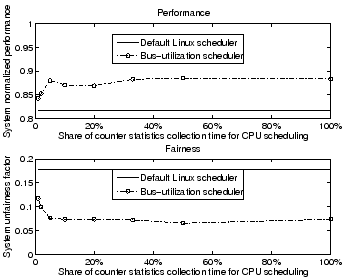
Figures 4 and 5 show the scheduling results for SPEC-CPU2000 applications and server applications respectively, as the share of counter statistics collection time is varied. The experimental setup, metrics used, and applications are the same as in Section 2.1. In general, scheduling effectiveness depends on application behavior variability. Applications with high behavior variability may be difficult to predict even with more sophisticated non-linear table-based predictors [9]. However, for SPEC-CPU2000 applications, our results suggest that with only a 5% share of counter statistics collection time, the CPU scheduling performance and fairness approximates that attained with full counter statistics collection. For server applications, a 33% share is needed since the behavior of individual requests fluctuates and is more variable. These results indicate that the effectiveness of a counter statistics-assisted CPU scheduler may be fully realized with only a fraction of counter statistics collection time.
 |
 |
Exposing processor counter statistics to non-privileged users and utilizing them in system functions may introduce new security risks. We examine two such issues.
Here we show a simple example of how the private RSA key in OpenSSL [14] may be stolen. One vital step in the RSA algorithm is to calculate Xd where d is the private key and X is the input. In OpenSSL, modular exponentiation is decomposed into a series of modular squares and modular multiplications. By knowing the sequence of squares and multiplications, one can infer the private key with high chance. For example, X11 is decomposed into ((X2)2
 |
The direct exposure of hardware counter statistics to non-privileged user applications may exacerbate existing risks in the following ways.
To prevent such undesirable information leaks, the system must be judicious in exposing hardware statistics to non-privileged user applications. Relevant hardware statistics can be withheld due to the above security concerns. Note that a fundamental tradeoff exists between security and versatility in information disclosure. In particular, withholding contention-dependent hardware statistics may impair an application's ability to employ adaptive self-management. Such tradeoffs should be carefully weighed to develop a balanced policy for hardware statistics exposure.
With the increasing ubiquity of multiprocessor, multithreaded, and multicore machines, resource-aware policies at both the operating system and user level are becoming imperative for improved performance, fairness, and scalability. Hardware counter statistics provide a simple and efficient mechanism to learn about resource requirements and conflicts without application involvement. In this paper, we have made the case for direct OS management of hardware counter resource competition and security risks through demonstration of its utility both within the operating system and at user level. Ongoing work includes development of the API and policies for hardware counter resource management within the kernel.