Arati Baliga, Joe Kilian and Liviu Iftode
Department of Computer Science, Rutgers University, Piscataway, NJ.
All web services available today are for open storage and sharing, where the existence of the data is known to the service provider. The fundamental, implicit assumption here, is that the service provider can be completely trusted with the user data. Any content stored in the clear on these servers is vulnerable to unauthorized access by the service administrators. Further, the government could compel the service provider to turn over this data without the knowledge of the user. A more cautious user might encrypt all content that is stored on these servers. While this protects the data from unauthorized access, it cannot hide the fact that some data is stored by a particular user. The user might be subsequently coerced into revealing the encryption keys by legal instruments such as subpoenas. Thus, users may desire to hide the very presence of their data stored on public servers in such a way that its existence cannot be proven by the service providers themselves or another third party.
Storing and sharing data covertly over the internet serves several purposes. For example, this may be used as a means to share content in societies that tend to stifle free exchange of unpopular ideas. Even in more democratic countries, social taboos can force people to look for covert means for facilitating secret online collaborations. Finally, individual web users may use such covert means to backup, store and share their files online without the knowledge of the service providers.
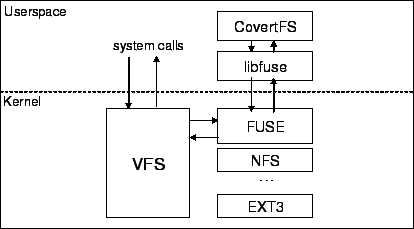
In this paper, we propose the idea of a covert web based file system, CovertFS, which facilitates secure file storage and sharing amongst a group of people and yet provides plausible deniability. CovertFS can be built on top of any publicly available media hosting and sharing service. Flickr [2], a photo sharing service from Yahoo, is an excellent example of such a service as it provides large storage and excellent API. The file system is covertly hidden within the media hosted by the user using steganographic techniques. This file system provides plausible deniability for the user and the service provider. Plausible deniability is achieved because the presence of the hidden data cannot be determined by any external parties, including the service provider.
The salient features of the file system can be stated as follows:
The design of a covert file system on a media sharing website poses several research challenges. First, an efficient way to hide the file system data within photos is necessary. Advances in steganography help us here [13,12,11]. The file system data can be encrypted and hidden within the photos in such a way that an adversary cannot detect the difference between regular photos and photos with hidden data. Secondly, we need an efficient mapping scheme of the file system blocks to images in order to fully utilize the storage capacity offered by the public server. Finally, covert file access traffic should not be distinguishable from the innocuous photo sharing traffic on the same website, originating from the ordinary users. These users are likely to download new photos and ignore photos they have already seen, they seldom update photos they have already posted and do not delete old photos until there is a shortage of storage on their account. Such access patterns should not be violated when the media website is used to access the hidden file data. In what follows, we will discuss the key design issues that can address these challenges.
To store all the files within the file system remotely, we need as many images in the Flickr account as the number of blocks on the file system. The number of files that can be stored is constrained by the account storage size within Flickr. However, Flickr and most service providers have unlimited accounts for a minimal service fee per year, providing a virtually unlimited storage capacity. Alternative designs can store mutiple file block in larger images or can span over multiple user accounts and/or multiple service providers.
Metadata, such as inode blocks, and the direct and indirect disk blocks are also stored in photos. Inodes and file block addresses can be identified directly by the name of the image where they are stored or indirectly using inode and block allocation maps, themselves stored in one or multiple images. Retrieval of the photo containing the first block of the map is done through a name that, when hashed, maps to a special value, usually a function of the encryption passphrase entered by the user.
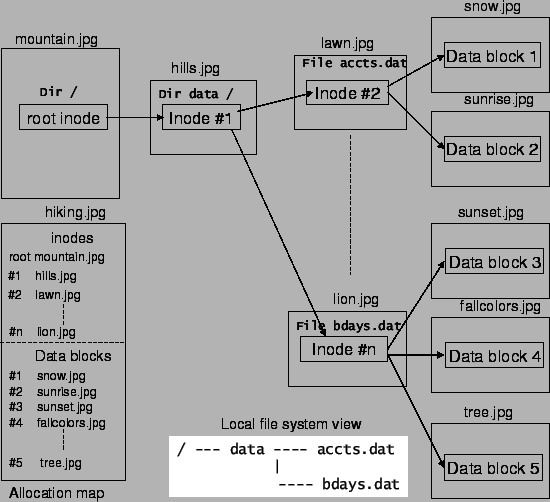 |
Fig. 1 shows the file system object hierarchy as embedded within different photos stored in the Flickr account. The photo mountain.jpg contains the root inode, which points to the only directory inode under the root directory embedded in the photo hills.jpg. The directory contains two files, whose inodes are embedded in photos lawn.jpg and lion.jpg respectively. Data blocks are contained within photos snow.jpg, sunrise.jpg, sunset.jpg, fallcolors.jpg and tree.jpg. The allocation map for inodes and data blocks are stored within the photo hiking.jpg. The figure also shows the local view of the file system, within the gray box.
To address frequent image changing due to inode and file system block updates, we propose to make photos immutable and apply an update scheme similar to one used in the log structured file system [10]. According to this scheme, modified file system objects will be hidden in new photos. To achieve this, the indirection through the allocation map is absolutely necessary.
With the proposed scheme, the allocation map becomes the file system object whose frequent changes must also be hidden. To keep the photos carrying the allocation map also immutable, we must devise a mechanism to locate the most recent copy of the map. For this, we propose two complementary schemes. The basic scheme takes advantage of the user-defined name space for photos to apriori decide the name of the photo to store the next version of the map and to embed it along with the version number in the photo of the current map (forward pointer). In this way, a file system user can easily determine when the allocation map has changed by looking at the photo name of the next map. If the new photo does not exist, the client can assume that the map has not changed and use its cached copy. As a backup, in case this chain cannot be reconstructed due to garbage photo collection, the names of the map photos are chosen such that all map to the same special value when when hashed with the user passphrase. In this way, in the worst case, a complete inspection of all the images in the account, will allow a user to discover the most recent copy of the map.
Photo garbage collection is done when the user account reaches near full capacity. The photos containing the invalidated blocks will all be deleted in a batch during this process, freeing up space in the account, yet generating traffic patterns of photo sharing users.
We build our file sharing and access control model on top of the Flickr photo sharing model. Only the owner of the Flickr account is able to modify file system content, while members of the group or others can only read files or part of the file system that is enabled selectively for read sharing by the owner.
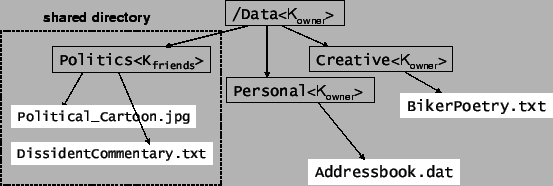
Selective sharing needs to be enabled by the owner who wants to share his files or directories with other users in the group. Each share is assigned a separate encryption passphrase as shown in Fig. 2. The directory Politics is shared with a group of friends with a separate encryption key. Every parent inode object that has a link pointing to a file or directory has a respective encryption key associated with it. Storing the encryption key in the inode allows the owner to access all the files at any time without retyping separate encryption passwords assigned to different shares. In case a separate encryption key is not assigned to any file or directory, the encryption key is replicated from the parent inode. All other directories in Fig. 2 are encrypted with the owners encryption key.
The photos corresponding to the directory to be shared (Politics
directory in the fig) are moved to the appropriate category of
photos in the Flickr account for sharing with the group. The
encryption passphrase for files within the share is given to other
users of the group. They can locate the root inode within the share
by hashing with the given passphrase. Note that the passphrase is
different for each share and can be changed by the owner at any
given time, when he decides to revoke sharing.
A similar analogy applies to CovertFS as well. Hidden levels can be created in CovertFS. Each level has a different encryption passphrase and can only be opened when the user provides the correct passphrase. Additional levels are also mapped by using other photos within the same account. Alternatively, hidden levels may also be created involving additional user accounts on the same or other service providers.
Other set of techniques used for hiding information is called the
transform domain tools. These group of tools use techniques that
involve manipulation of algorithms and image transforms. One of the
popular techniques used for JPEG images is called the discrete
cosine transform (DCT). These methods hide information in more
significant areas of the image and may manipulate image properties
such as luminance. These techniques are far more robust and much
harder to detect using steganalysis. The tradeoff however is that
such methods can encode much smaller amount of information within
the cover. Recent research has come up with zero divergence
steganography or secure steganography that use statistical
restoration techniques
[13,12,11].
The basic idea is to thwart steganalysis methods by hiding
information in few bits within the image and adjusting other bits to
offset the deviations caused by the hidden information. Hence,
advances in steganography have made it possible to build tools that
can thwart steganalysis. We plan to use one such advanced technique
in our prototype to hide the file system data.
Traffic patterns can be obfuscated by introducing pseudo random dummy image fetches. The client can cache already visited photos to ensure that it does not download those photos too frequently. CovertFS is designed such that only new photos are uploaded and old ones are deleted when the account reaches near full capacity, which resembles the behavior of normal photo sharing users. Also, the additions are done in a batch as the file system operates in a disconnected mode, making additions in a batch to the photo store, similar to how regular users add photos. Since Flickr has an open API, several other applications have been built on top of it that perform specific tasks, customized to the user. Each of these tasks gives rise to different upload/download patterns.
The steganographic file system that gives the user
plausible deniability was first proposed by Anderson and Shamir
[6]. They did not have a working prototype of the file
system. McDonald et al [8] were the first to build a
working prototype of a steganographic file system called StegFS.
StegFS is a local file system that provides plausible deniability by
hiding files in unused disk blocks. The prototype did not require a
separate partition but worked along with the Linux ext2 partition.
Pang et al [9] demonstrated improvements to the hiding
schemes and design of StegFS, which demonstrated significant
improvements in performance. All the file systems mentioned above
work with the local hard drive and provide plausible deniability to
the user. None of these provide the ability to globally access or
share files. Since all of these hide in unused disk blocks, they run
the risk of being overwritten when the driver is not operating in
the steganographic mode. Therefore these require a high degree of
replication, severely limiting the disk space usage. CovertFS, on
the other hand, provides file sharing between geographically distant
users as well as plausible deniability. CovertFS hides files from
the service providers themselves and is built over a media sharing
service. The design considerations are significantly different in
both cases.
The gmail file system [3] allows the user to store his data as email messages in his mail account. The service provider is aware of the existence of the user files in this mail account. This file system does not allow plausible deniability or enable file sharing with others. Httpfs [7] is a network file system that provides access to files on a remote machine using the http protocol. It requires a component to run on the remote server, from where documents can be fetched on the client. This is similar to the network file system implementation but using http. For CovertFS, no such component is required on the server side. DavFS [4] allows to mount files from a WebDAV server on a local driver. WebDAV is an extension of http that allows remote collaborative authoring of web resources. DavFS allows a remote web server to be edited simultaneously by a group using standard applications. DavFS, fundamentally differs from our implementation as it requires a server component. None of the above file systems provide plausible deniability either. CovertFS can run on top of any media hosting service. The control lies with the user on how he accesses/modifies his hidden files.
The Web File system [5] provides a file system
interface to the world wide web. The goal here is completely
different from our goal. This file system allows the user to browse
the web as different files that are downloaded on the local hard
drive.
This document was generated using the LaTeX2HTML translator Version 2002-2-1 (1.70)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -split 0 -show_section_numbers -local_icons paper.tex