
We first define the file download problem more formally, and
then outline the goals and motivation for our work.
Consider a content server with a network link of bandwidth Rnbytes/s and a population of N clients concurrently downloading
shared files. We use the term file to mean a unique ordered
set of data blocks; thus it could refer to any segment of a larger data
set. Suppose that each client i can receive data at a sustained
rate
![]() ,
with an average client rate Rc bytes/s.
The goal is to schedule block reads from disks and block
transfers to clients in order to maximize X(N), the system
throughput for N concurrent requests, or the number of download
requests completed per time unit. Unless it is saturated, the server
should be fair and it should complete each request in the minimum time that the
network allows: a request from client i to download a file of
length L bytes should complete after approximate delay L/Rci.
,
with an average client rate Rc bytes/s.
The goal is to schedule block reads from disks and block
transfers to clients in order to maximize X(N), the system
throughput for N concurrent requests, or the number of download
requests completed per time unit. Unless it is saturated, the server
should be fair and it should complete each request in the minimum time that the
network allows: a request from client i to download a file of
length L bytes should complete after approximate delay L/Rci.
Since this paper focuses on the design of the server and its storage
system, we will claim success when the server is network-limited,
i.e., it consumes all of its available network bandwidth. Suppose
the average file length is L bytes. For low client
loads, the server may be limited by the aggregate network bandwidth to
its clients:
![]() .
If the client population is large, or
if the clients have high-speed links, then the
server may be limited by its own network link:
.
If the client population is large, or
if the clients have high-speed links, then the
server may be limited by its own network link:
![]() (with
unicast). We assume without loss of generality that the server's CPU
and memory system are able to sustain the peak data rate Rnwhen serving large files.
(with
unicast). We assume without loss of generality that the server's CPU
and memory system are able to sustain the peak data rate Rnwhen serving large files.
Our objective, then, is to minimize the memory and storage resources needed to
feed content to the network at the peak rate Rn for a sufficiently
large client population:
![]() .
Suppose the content server has a memory of
size M and D disks delivering a peak bandwidth of Rd byte/s
each. Our purpose is to explore how block reordering
can reduce the number of disks D needed for a given M, and/or
reduce the M needed for a given D and Rd. Equivalently, we
may view the objective as maximizing the network speed Rn or
client population size N that a given configuration (M,D) can
support. The problem is uninteresting
for small Rn, e.g., in serverless P2P systems that distribute
server functions across many slow clients. The problem is most
interesting for servers in data centers with high-capacity
network links, serving large client populations with slow transfer
rates Rc. N may be quite large for commercial content servers
with a large bandwidth disparity relative to their clients: IP network
bandwidth prices are dropping [13], while broadband
deployments for the ``last mile'' to clients continue to lag behind.
Although our approach does not require
multicast support, it is compatible with multicast and
N may be even larger when it exists.
.
Suppose the content server has a memory of
size M and D disks delivering a peak bandwidth of Rd byte/s
each. Our purpose is to explore how block reordering
can reduce the number of disks D needed for a given M, and/or
reduce the M needed for a given D and Rd. Equivalently, we
may view the objective as maximizing the network speed Rn or
client population size N that a given configuration (M,D) can
support. The problem is uninteresting
for small Rn, e.g., in serverless P2P systems that distribute
server functions across many slow clients. The problem is most
interesting for servers in data centers with high-capacity
network links, serving large client populations with slow transfer
rates Rc. N may be quite large for commercial content servers
with a large bandwidth disparity relative to their clients: IP network
bandwidth prices are dropping [13], while broadband
deployments for the ``last mile'' to clients continue to lag behind.
Although our approach does not require
multicast support, it is compatible with multicast and
N may be even larger when it exists.
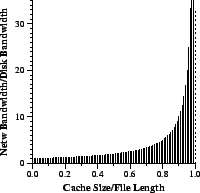 |
| Figure 1: The maximum ratio of network bandwidth to disk bandwidth, as a function of the portion of the data set size that fits in the cache. The system is heavily disk-limited unless the bulk of the data set fits in memory. though. |
The server's memory of size M consists of a common pool of shared buffers. A server uses these buffers for some combination of disk buffering, network buffering, and data caching. For example, suppose the server fetches data from storage in blocks of size Bbytes. A typical server would buffer each fetched block until all client transmits of the block to clients have completed; the surplus memory acts as a cache over blocks recently fetched for some client i that are deemed likely to be needed soon for another client j requesting the same file. Caching is effective for small files that can reside in the cache in their entirety until the next request [6]. However, if j's request arrives t time units after i's, then the server has already fetched up to tRci bytes of the file into memory and delivered them to i. The memory needed to cache the segment until j is ready to receive it grows with the inter-arrival time t. If Rci > Rcj then the required cache space continues to grow as the transfers progress--when the system is constrained to deliver the data in order to both clients, as for conventional file servers.
Since each file request accesses each block of the file exactly once, block accesses are uniformly distributed over the entire file length. As the number of clients increases, and as client rates and arrival times vary, the block access request stream shows less temporal locality and becomes effectively random. Of course, there is spatial locality when the server delivers each block in sequence; the system may exploit this by using a larger block size B, as discussed below (or, equivalently, by prefetching more deeply). Suppose without loss of generality that the content consists of a single file of length L >> M, or any number of equally popular files with aggregate size L. Then the probability of any block access being a cache hit is Phit = M/L, and Pmiss = 1 - M/L is the probability that the access requires a disk fetch. Then the server's storage system must be capable of sustaining block fetches at rate (Rn/B)(1 - M/L). Figure 1 shows the role of cache size in determining the number of disks required to sustain this rate.
 |
|
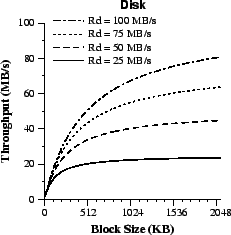
Figure 2: Disk throughput with random block accesses in a disk with positioning time Tpos = 0.005s across different transfer block sizes, and sequential disk transfer rates Rd. We show that as Rd increases, block size must exceed one megabyte to achieve peak disk throughput. |
 |
|
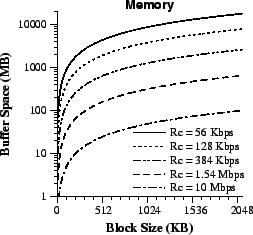
Figure 3: Minimum buffer space required to support clients at different rates in a server with a 1 Gbps network link. The minimum buffer space can reach several gigabytes for large populations of clients with bandwidth less than 1 Mbps. |
The areal density of magnetic storage has been doubling every year, and disks today spin several times faster than ten years ago [13]. While these trends increase sequential disk bandwidth, throughput for random block accesses (IOPS) has not kept pace. Seek costs tend to dominate random accesses, and these costs are limited by mechanical movement and are not improving as rapidly. Unfortunately, the block miss stream for a content server degrades to random access as the client population N increases, for the same reasons outlined above.
One solution is to increase the block size B. This reduces the rate
of disk operations required to sustain a given effective bandwidth,
which is inversely proportional to B. This technique can significantly reduce the
number of disks required. Suppose each disk has an average head
positioning time per access of Tpos seconds (seek plus
half-rotation). Every disk access moves a block of size B bytes, and
takes time
Tpos + B/Rd. Thus, each disk supports
![]() random accesses per time unit, and the aggregate peak
disk bandwidth for D disks becomes
random accesses per time unit, and the aggregate peak
disk bandwidth for D disks becomes
![]() bytes/s. The server needs
bytes/s. The server needs
![]() disks to fully pipeline the network.
For example, Figure 2 illustrates the disk random
access throughput when
Tpos = 0.005 s, a typical value. With
block size B = 256 KB, and disks of Rd = 50 MB/s, the disk
throughput Xd becomes roughly 25 MB/s. We need about D=5 such
disks to feed a server network link of Rn = 1 Gb/s.
disks to fully pipeline the network.
For example, Figure 2 illustrates the disk random
access throughput when
Tpos = 0.005 s, a typical value. With
block size B = 256 KB, and disks of Rd = 50 MB/s, the disk
throughput Xd becomes roughly 25 MB/s. We need about D=5 such
disks to feed a server network link of Rn = 1 Gb/s.
However, Figure 3 shows that
this approach consumes large amounts of memory with large
client populations.
Depending on the buffering scheme the
minimum memory size M for N active clients is
![]() .
The 1 Gb/s server can support N = 664 T1 (1.544
Mbps = 193 KB/s) client connections, consuming a minimum
M = 87 MB just for device buffering with B = 256 KB. If we increase
the block size to B = 1 MB then disk throughput becomes Xd = 40MB/s, the number of disks drops to D=4, and the minimum memory
grows to M = 325 MB. If instead,
we assume slower clients with Rc = 56 Kbps, the
server needs a minimum M = 2.18 GB
and M = 8.7 GB for block size B = 256 KB and B = 1 MB,
respectively. In media servers using large block sizes it is common
to eliminate the cache and partition memory into separate buffer
regions for each client; each region is sufficient to hold any blocks
in transit between the disk and the network for that
client [4].
.
The 1 Gb/s server can support N = 664 T1 (1.544
Mbps = 193 KB/s) client connections, consuming a minimum
M = 87 MB just for device buffering with B = 256 KB. If we increase
the block size to B = 1 MB then disk throughput becomes Xd = 40MB/s, the number of disks drops to D=4, and the minimum memory
grows to M = 325 MB. If instead,
we assume slower clients with Rc = 56 Kbps, the
server needs a minimum M = 2.18 GB
and M = 8.7 GB for block size B = 256 KB and B = 1 MB,
respectively. In media servers using large block sizes it is common
to eliminate the cache and partition memory into separate buffer
regions for each client; each region is sufficient to hold any blocks
in transit between the disk and the network for that
client [4].
In this section we explained why accesses at the block level appear increasingly random as the client population Ngrows. This minimizes the benefit of conventional caching and weakens the locality of the disk accesses from the cache miss stream. The combination of these effects increases server cost, since more disks and/or more memory are needed to fill any given network link. For example, the experiments in this paper use disks with average sequential throughput of Rd = 33 MByte/s, but a conventional FTP server under even modest load delivers a per-disk throughput of roughly 10 MB/s, including cache hits. Thus we need about a dozen such disks to feed a network link of 1 Gb/s.