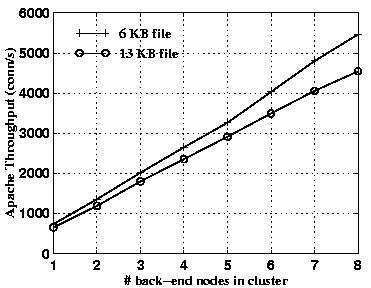
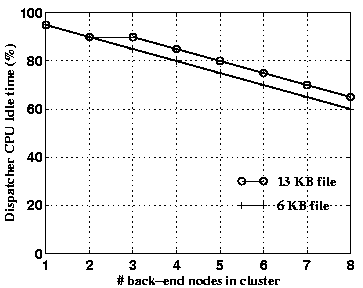
We repeated the experiments from Section 3 to demonstrate the scalability of our proposed cluster configuration. Figure 9 shows the throughput results with the Apache webserver as the number of nodes in the cluster (other than the one running the dispatcher) are increased. As shown in the figure, the throughput increases linearly with the size of the cluster. Figure 10 depicts the CPU idle time on the node running the dispatcher. The results clearly show that in this experiment, the dispatcher node is far from causing a bottleneck in the system.
A comparison with earlier results in Figure 2 and Figure 3 shows that the absolute performance in Figure 9 is less for comparable number of nodes in the cluster. In fact, the performance with Nnodes in Figure 9 was achieved with N-1 back-end nodes in our earlier results with the conventional content-based request distribution based on handoff. The reason is that with the former approach, the front-end offloads the cluster nodes by performing the request distribution task, leaving more resources on the back-end nodes for request processing. However, this very fact causes the front-end to become a bottleneck, while our proposed approach scales with the number of back-end nodes.
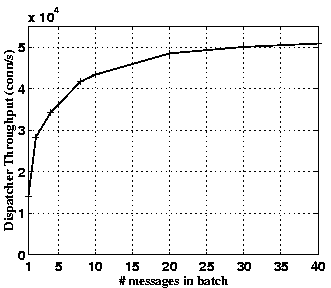
Due to a lack of network bandwidth in our PIII cluster, we were unable to extend the above experiment so as to demonstrate when the dispatcher node becomes a bottleneck. However, we devised a different experiment to indirectly measure the peak throughput afforded by our system. We wrote a small program that generated a high rate of requests for the dispatcher node. Requests generated by this program appeared to the dispatcher as if they were requests from distributor nodes from a live cluster. This program was parameterized such that we were able to vary the degree of batching in each message sent to the dispatcher. Two messages to the dispatcher are normally required per HTTP request--one to ask for a server node assignment and one to inform the dispatcher that the client connection was closed. The degree of batching determines how many of these messages are combined into one network packet sent to the dispatcher.
Figure 11 shows the peak throughput afforded by
the dispatcher as the degree of batching was increased from one to
forty. These results show that the dispatcher node (300MHz PII) can
afford a peak throughput of more than 50,000 conn/s. This number
determines the peak performance afforded by our cluster and is an
order of magnitude larger than that afforded by traditional clusters
that employ content-aware request distribution. At this peak
throughput, each HTTP connection imposes an overhead of about 20
![]() sec on the dispatcher node. The bulk of this overhead is
attributed to the overheads associated with communication. The LARD
request distribution strategy only accounts for 0.8
sec on the dispatcher node. The bulk of this overhead is
attributed to the overheads associated with communication. The LARD
request distribution strategy only accounts for 0.8 ![]() sec of the
overhead. Repeating this experiment using a 500MHz PIII PC as the
dispatcher resulted in a peak throughput of 112,000 conn/s. Also, it
is to be noted that the peak performance of the dispatcher is
independent of the size of the content requested. In contrast, the
scalability of cluster configurations with conventional content-aware
request distribution decreases as the average content size increases.
sec of the
overhead. Repeating this experiment using a 500MHz PIII PC as the
dispatcher resulted in a peak throughput of 112,000 conn/s. Also, it
is to be noted that the peak performance of the dispatcher is
independent of the size of the content requested. In contrast, the
scalability of cluster configurations with conventional content-aware
request distribution decreases as the average content size increases.
We also measured the increase in latency due to the extra
communication incurred as a result of the dispatcher being placed on a
separate node. This extra hop causes an average increase of 170
![]() sec in latency and is largely due to round trip times in a
LAN and protocol processing delays. When the layer-4 switch is used
for interfacing with the clients, an additional 8
sec in latency and is largely due to round trip times in a
LAN and protocol processing delays. When the layer-4 switch is used
for interfacing with the clients, an additional 8 ![]() sec latency is
added due to packet processing delay in the switch. This increase in
latency is insignificant in the Internet where WAN delays are usually
larger than 50 ms. Even in LAN environments, the added latency is not
likely to affect user-perceived response times.
sec latency is
added due to packet processing delay in the switch. This increase in
latency is insignificant in the Internet where WAN delays are usually
larger than 50 ms. Even in LAN environments, the added latency is not
likely to affect user-perceived response times.