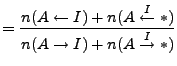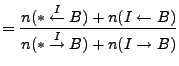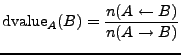Michael Piatek
Tomas Isdal
Arvind Krishnamurthy
Thomas Anderson
University of Washington
Peer-to-peer (P2P) networks have the potential to address long-standing challenges in networked systems. End hosts represent an immense pool of under-utilized bandwidth, storage, and computational resources that, when aggregated by a P2P network, can be used to absorb flash crowds, replicate data intelligently within the network, and externalize bandwidth costs. And unlike network-layer support such as IP multicast, P2P solutions can be deployed without architectural changes to the underlying network.
While significant progress has been made towards addressing the technical challenges of building P2P systems, their robustness ultimately depends on convincing users to contribute their resources, a challenge of incentive design. Early P2P systems such as Gnutella ignored incentives and were plagued by rampant free-riding, i.e., users consuming resources without contributing them [1]. Free-riding degrades system performance and limits scale. Subsequent systems such as BitTorrent explicitly built user contribution incentives into their design [4], but recent work has exposed methods of circumventing BitTorrent's incentives [11,12].
Designing robust incentives for P2P networks is challenging due to the constraints of the environment:
This paper concerns how best to design future incentive strategies for P2P networks. We proceed in two steps. First, to ground our work, we conducted a measurement study of BitTorrent. BitTorrent is a widely used P2P system and we were able to study the sharing behavior of tens of thousands of data objects and millions of users for more than one month. Surprisingly given BitTorrent's popularity, we identify widespread performance and availability problems, along with data on why these problems arise in practice. We find that problems cannot be wholly attributed to scarcity of potential data sources and/or capacity limitations. Instead, we argue that ineffective incentives account for the lack of resources, a point underscored by our measurement result that an average user joining an average swarm can get comparable download performance with only 1/100th the contribution.
A key reason for the weakness of current incentives is the duration for which they are active. Current incentives in BitTorrent operate within the context of a single object and only while clients are actively downloading. As a result, users have no reason to contribute once they have satisfied their immediate demands. This weakness implies the need for persistent incentives that operate across data objects and across time. Unfortunately, our measurements also show that most pairs of peers interact with one another in just one swarm, suggesting that long-term incentives will not arise from strategies based on direct interactions and local history alone. But, while most P2P users are transient, our study shows that a small minority of peers participate persistently and across many swarms; these users provide a scaffold for a solution.
The second part of the paper concerns our design of a solution to the problems we found in BitTorrent. We propose a new, one hop reputation protocol for P2P networks. Unlike digital currency systems, where contribution information propagates globally, or tit-for-tat, where no propagation occurs, one hop reputations limit propagation to at most one level of indirection. Surprisingly, this limited propagation suffices to provide wide coverage; we find that the majority of peers, while transient, have shared relationships through popular intermediaries one hop removed. We define a protocol that discovers these relationships, enabling a broad range of servicing policies using information beyond direct observations and local history. Through trace-driven analysis and measurements of a deployment on PlanetLab, we show that our default one hop system both improves performance for users in individual swarms and fosters the long-term incentives that are necessary for P2P systems to work well in the long run.
To understand the real challenges facing P2P designers, we collected large-scale measurements of BitTorrent in the wild. Over the course of the study we observed more than 14 million peers and 60,000 swarms accounting for thousands of terabytes of transfered data. To measure the strength of contribution incentives, we joined real swarms, exchanged data at varying rates with peers, and collected information to distinguish unique users such as client software and version and IP address. We also tracked the popularity of swarms over time, recording both direct observations of peers and second hand accounts from coordinating tracker servers, membership DHT entries, and peer gossip messages.
Our measurements provide insights into the sharing workload that extend beyond the granularity of performance for a single user or behavior in a single swarm. Specifically, we show the following:
In BitTorrent, each file is split into blocks. Clients actively downloading a file are randomly matched, with matched peers exchanging data and control information as to which blocks they have and which they need. Ideally, a data source, or seed, only needs to provide each data block to a few random clients, and the rest of the work is done by the swarm of peers. Crucially, peers distinguish among competing requests for service according to a tit-for-tat policy: each client preferentially uploads blocks only to those peers that are actively providing data to it (and then, only to those that are providing data at the highest rate). Tit-for-tat is intended to provide better performance for peers that contribute more data.
The reported effectiveness of tit-for-tat has varied widely in existing work. Theoretical analysis, simulation and small testbed studies have pointed to its robustness [2,10,15] while more recent studies of performance in the wild have exposed circumstances under which tit-for-tat breaks down [11,12,16]. For system builders to design truly robust incentive protocols, a more complete understanding of P2P workloads is required. We collect and analyze BitTorrent trace data with the overarching goal of understanding when tit-for-tat incentives work and when they don't, in the wild.
We make reference to two traces of live BitTorrent swarms collected
from a cluster of machines at the University of Washington. Between January
26
![]() and February 3
and February 3
![]() , 2007,
we measured membership and download performance for instrumented
clients participating in 13,353 swarms. We refer to this trace as
BT-1. We collected a second trace, BT-2, from the
same cluster over the month of August 2007, providing measurements of
55,523 swarms. In both traces, every hour, a measurement coordinator
crawled popular BitTorrent websites that aggregate information about
new swarms, downloading all of these. Our instrumented clients joined these swarms periodically during the trace.
We include information for only those swarms we successfully connected to at least once.
To determine peer download rates, we measured the rate at which new
blocks appeared in the peer's list of available blocks and also
recorded availability of blocks. Each client contributed resources
to the swarms at a rate of either 1, 30, or 100 KBps to examine the
performance impact of varying the contribution level.
, 2007,
we measured membership and download performance for instrumented
clients participating in 13,353 swarms. We refer to this trace as
BT-1. We collected a second trace, BT-2, from the
same cluster over the month of August 2007, providing measurements of
55,523 swarms. In both traces, every hour, a measurement coordinator
crawled popular BitTorrent websites that aggregate information about
new swarms, downloading all of these. Our instrumented clients joined these swarms periodically during the trace.
We include information for only those swarms we successfully connected to at least once.
To determine peer download rates, we measured the rate at which new
blocks appeared in the peer's list of available blocks and also
recorded availability of blocks. Each client contributed resources
to the swarms at a rate of either 1, 30, or 100 KBps to examine the
performance impact of varying the contribution level.
The download rate achieved by our measurement clients as a function of contribution rate is summarized in Figure 1 for trace BT-1. Even on the well-connected academic network used for our data collection, clients download slowly; contributing 100 KBps yields a median download rate of just 14 KBps, far short of saturating even a modest home broadband connection. Further, 25% of the time swarms were completely unavailable, i.e., delivered no data.
The poor performance of P2P networks cannot be explained by users simply lacking the capacity to offer peers a high average download rate, nor can poor availability be attributed to a long tail of fundamentally unpopular objects. Regarding performance, measurements of more than 100,000 BitTorrent peers in 2006 put average upload capacity at more than 400 KBps [8]. Skew in the capacity distribution is significant; the average value is roughly 10X the median. Regarding availability, our measurement results show that for many seemingly unpopular objects, the existence of replicas is not as much a problem as the persistence of replicas. The vast majority of swarms would have significantly more replicas if downloaders would simply continue to share after completing. We evaluate this by comparing available replicas assuming peers persist for either one day or one week after their initial observation. For trace BT-2, the median increase in available replicas is a factor of 3.
These measurements point to a problem of incentives. If users could be convinced to contribute all of their capacity, download performance would increase. If users were convinced to persist as object replicas, availability would improve. Realizing these benefits requires understanding the causes of today's weak incentives, the topic we turn to next.
The strength of a contribution incentive is the return it provides for contribution, i.e., the ratio of uploaded to downloaded bytes. This section details two workload properties that weaken contribution incentives in BitTorrent. First, we examine how the distribution of bandwidth capacity among peers influences the incentive they have to make that capacity available. Second, we quantify the number of swarms for which random, altruistic contributions dominate performance.
Capacity: In BitTorrent, returns are known to diminish as contribution increases [12]. Peers at the low end of the capacity spectrum see large returns on their contributions, i.e., 10 bytes contributed might earn 15 reciprocated. This is balanced by reduced returns for peers with greater capacity. If the disparity between returns for high and low capacity peers were limited, contribution incentives would be only slightly weakened. In BitTorrent, however, the disparity is extreme. In our traces, increasing contributions 100-fold yields a 2-fold median marginal improvement in performance (shown for BT-1 in Figure 1).
The diminishing returns for contributions is particularly damaging for aggregate P2P resources as the majority of capacity is held by a small minority of users. Figure 2 shows the cumulative fraction of total capacity attributable to peers when ordered by individual capacity. If they were to contribute fully, the top 10% of peers would account for 80% of total capacity. Thus, for the highest capacity peers—those whose increased contribution would most help performance--the contribution incentive is weakest.
Altruism: A user's downloaded bytes come from either other peers actively downloading the object or seeds that have completed their downloads and continue to make data available. Because seeds do not have requests, they have no tit-for-tat basis for making servicing decisions, often doing so randomly in current implementations. An overabundance of seeds weakens contribution incentives as most users receive data regardless of contribution. Conversely, too few seeds also weakens incentives since peers quickly run out of data to trade, becoming blocked.
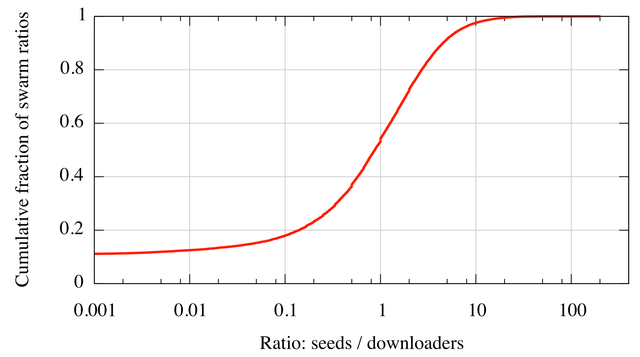
Figure 3 summarizes the amount of seed-based altruism in our BT-2 trace. For each swarm, we compute the ratio of observed seeds and downloaders. This estimates the fraction of data a downloading peer is likely to receive at random, i.e., independent of contribution. The data shows that no one circumstance dominates. 11% of swarm observations show no active seeds (ratio 0) while 50% of swarms have just as many randomly contributing seeds as actively downloading peers.
Given the range of operating conditions we observe in practice, it is unsurprising that the BitTorrent performance picture is unclear. Some swarms enjoy a glut of altruistic donations, weakening contribution incentives and enabling free-riding. Other swarms are starved for data, causing performance to be constrained by availability rather than contribution. For the minority remaining swarms, the strength of the contribution incentive is tied to the bandwidth capacity distribution, with the majority of capacity being held by peers with little reason to contribute, leading to slow download rates.
In contrast to the standard game-theoretic tit-for-tat strategy, BitTorrent's variant is rate-based. Instead of trading with peers byte for byte, reciprocation for a BitTorrent peer is decided only relative to its competitors and is apportioned equally among successfully competing peers. For instance, if a client ![]() with capacity 20 receives data from peers
with capacity 20 receives data from peers ![]() ,
, ![]() , and
, and ![]() at rates 5, 7, and 10 and selects only two peers at a time for reciprocation,
at rates 5, 7, and 10 and selects only two peers at a time for reciprocation, ![]() will send data to
will send data to ![]() and
and ![]() at rate 10 apiece. This approach favors utilization over fairness and stateless operation over stability. Peers simply give away bandwidth if they are poorly matched in terms of rates and maintain only a short-term local history about each peer with which to make servicing decisions, switching peers frequently as short-term status changes.
at rate 10 apiece. This approach favors utilization over fairness and stateless operation over stability. Peers simply give away bandwidth if they are poorly matched in terms of rates and maintain only a short-term local history about each peer with which to make servicing decisions, switching peers frequently as short-term status changes.
An alternative to basing tit-for-tat decisions on rate is instead basing them on total data volume. This is the approach taken by the eDonkey file sharing network, which stores per-peer state recording the amount of data sent and received, using this to rank peers with competing requests. From the perspective of strengthening contribution incentives, a switch from rate to volume seems promising, primarily because it offers the potential for long-term repeat interactions. Seeds might be willing to share files long after completion, improving availability, because in doing so they would contribute to peers whose memory of those contributions would induce reciprocation if the situation were reversed. Similarly, if high capacity peers were mismatched with low capacity peers, the contribution imbalance could be bounded or ignored—assuming repeat interactions would result in eventual repayment.
Unfortunately, volume-based tit-for-tat does not seem to have solved the performance problem in practice. Pucha et al. report a median download rate of 10 Kbps in the eDonkey network [14]—short of our observed median performance for BitTorrent swarms. Although numerous technical differences prohibit an apples-to-apples comparison, we hypothesize that the failure of volume-based tit-for-tat to promote contribution in eDonkey can be traced to a workload property that it likely shares with BitTorrent—a lack of pairwise repeat interactions.
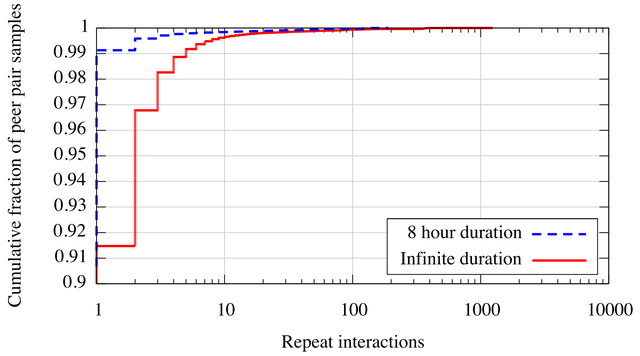
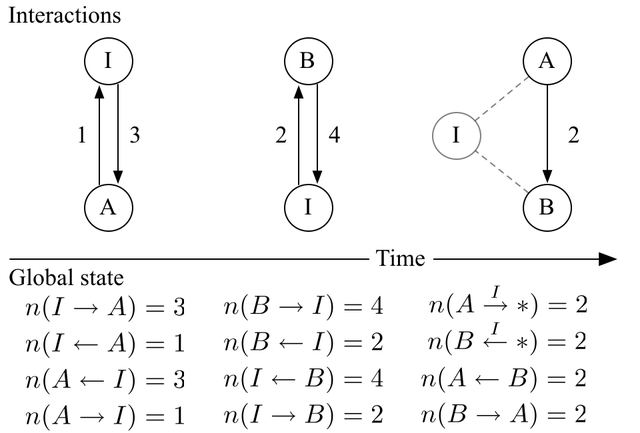
We say that two peers share an interaction if either sends or receives data from the other. Peers exhibit repeat interactions if they exchange data in multiple swarms. Figure 4 reports the frequency of repeat interactions in the BT-2 trace, conditioned on a pair having interacted in at least one swarm. Because our trace data provides only coarse-grained observations of peer membership, i.e., we do not actively probe observed peers repeatedly to determine departure time, we give the distribution of repeat interactions assuming peers persist for either an infinite duration or an 8 hour interval. Assuming infinite duration overestimates the number of repeat interactions, while assuming an 8 hour duration may underestimate it for some long-lived peers. In either case, however, the chance of enabling long-term incentives via repeat interactions is slim. Even assuming infinite duration, more than 91.5% of peer pairs that occur in a single swarm do not arise in any other swarm over the course of our trace.
The apparent lack of repeat interactions suggests that direct,
pairwise exchange based on local history alone will not suffice to
enable the long-term contribution incentives needed to address the
performance and availability problems we observe in the wild. But,
although direct interactions appear insufficient, our
workload measurements do provide a hint as to the effectiveness of
indirect reciprocation; i.e., instead of peer ![]() deciding
whether to service the requests of
deciding
whether to service the requests of ![]() only on the basis of
only on the basis of ![]() 's
contributions to
's
contributions to ![]() , indirect reciprocation might see
, indirect reciprocation might see ![]() contributing to
contributing to ![]() due to
due to ![]() 's contributions to
's contributions to ![]() , who has
previously contributed to
, who has
previously contributed to ![]() .
.
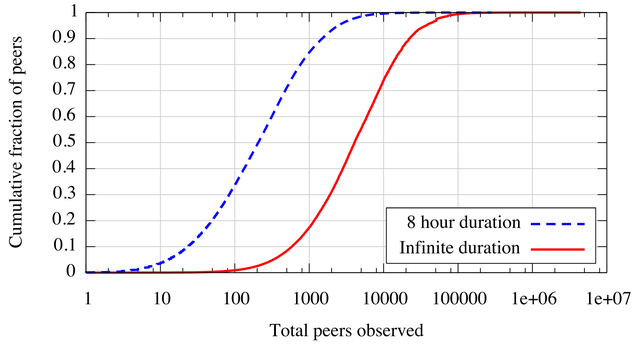
Our data shows that most peers share an indirect relationship of this type. Further, a small number peers account for most of these intermediaries. 97% of all peers observed in trace BT-2 are connected either directly or through an intermediary among the most popular 2000 peers. This is due to a workload characteristic. Although most peers connect to only hundreds of other peers, a small minority is more extensively connected. Figure 5 shows the distribution of peer connectivity in trace BT-2.
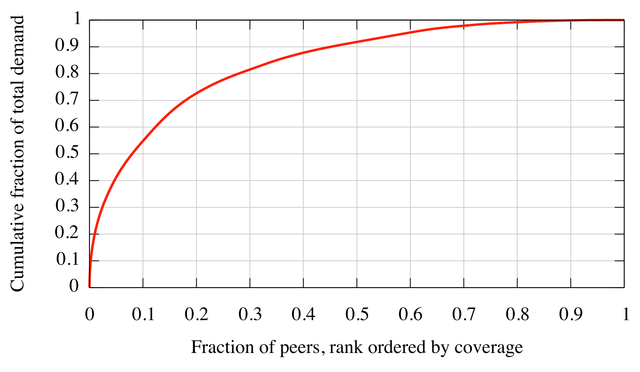
The disparity in peer popularity is reflected in the distribution of demand as well. Figure 6 shows the distribution of total demand observed in our trace. We first ordered peers by popularity, i.e., the number of other peers with which they share a swarm. Next, we computed the cumulative fraction of demand attributable to these ordered peers. The top 25% of peers account for 78% of demand.
Although repeat interactions are rare for the majority of peer pairs, a small minority of popular users have much wider coverage. In this section, we describe a new, one hop reputation propagation protocol designed to enable long-term reciprocation beyond this minority via indirect reciprocation. The main goal of one hop reputations is to foster persistent contribution incentives by recognizing and rewarding contributions made by users across swarms and over time. To achieve this, clients maintain a persistent history of interactions and, upon request, serve as intermediaries attesting to the behavior of others.
The key idea behind our scheme is to restrict the amount of indirection between contributing and reciprocating peers to at most one level of intermediaries. This restriction limits the propagation of information, promoting scalability, and allows for local reasoning about the trustworthiness of intermediaries, thereby fostering robustness.
While our measurements show that most peers share a one hop relationship, discovering and using these relationships requires more information than is available through direct observation alone. Peers need to name one another persistently across interactions and exchange messages about third party behavior. In Section 3.1, we define a protocol for exchanging the information required to discover intermediaries and to mediate indirect reciprocation.
Our protocol provides information but does not prescribe how that information must be used, separating the mechanism for exchanging information from the policy for using it. In Section 3.1, we specify a default policy designed to maximize coverage, i.e., the fraction of pairs of peers that can evaluate one another using one hop reputations. We also describe the resistance of our default policy to various forms of strategic manipulation, but we do not claim to be robust to all forms of attack. Instead, our design is intended to allow peers to freely evolve their strategies independently, and we consider several potential alternatives.
|
Our one hop reputation protocol can be broken down into two facets: the state maintained at each peer and messages used to propagate state between peers.
Per-peer state: One hop reputations extend volume-based tit-for-tat to incorporate reputation intermediaries. Intermediaries serve two purposes: bootstrapping connections between new peer pairs and maintaining accounting information regarding indirect reciprocation. Every client records each peer it has interacted with, either directly during data transfer or indirectly when that peer acts as an intermediary attesting to the behavior of others. Each peer is identified by a self-generated public/private key pair. While a peer can freely create new identities, our default policy rewards long-term persistence and includes provisions for mitigating Sybil attacks [6], creating little incentive to do so. Table 1 lists the state maintained by each client, which is indexed by the public key of its peers.
Figure 7 provides an example of the use of this
information to bootstrap a new connection. In this case, a one hop
intermediary ![]() bootstraps the interaction between peers
bootstraps the interaction between peers ![]() and
and ![]() who have not previously interacted. In the first two interactions,
who have not previously interacted. In the first two interactions, ![]() exchanges data directly with
exchanges data directly with ![]() and
and ![]() . These uninformed exchanges are infrequent and
serve to bootstrap a reputation. At this point,
. These uninformed exchanges are infrequent and
serve to bootstrap a reputation. At this point, ![]() can serve
as an intermediary between
can serve
as an intermediary between ![]() and
and ![]() . When they meet,
. When they meet, ![]() and
and ![]() exchange control traffic (defined below) allowing them to recognize
their common relationship with
exchange control traffic (defined below) allowing them to recognize
their common relationship with ![]() . Because
. Because ![]() has contributed to
has contributed to ![]() in the past and
in the past and ![]() has received prior service from
has received prior service from ![]() ,
, ![]() can use
its local history regarding
can use
its local history regarding ![]() to inform its valuation of
to inform its valuation of ![]() .
.
Because the interactions between ![]() ,
, ![]() , and
, and ![]() may not occur within the
context of a single swarm, peers may need to contact intermediaries across multiple sessions. To
aid in this, each client stores its current IP address and TCP port, indexed by its public key, in a
DHT. Many popular P2P services already include a DHT,
e.g., Kademlia is used in BitTorrent and eDonkey. Although existing DHTs are generally robust,
we do not evaluate their resistance to strategic or malicious behavior, instead opting to
use provided values as hints only. Identity is independently verified using cryptographic
keys and key
may not occur within the
context of a single swarm, peers may need to contact intermediaries across multiple sessions. To
aid in this, each client stores its current IP address and TCP port, indexed by its public key, in a
DHT. Many popular P2P services already include a DHT,
e.g., Kademlia is used in BitTorrent and eDonkey. Although existing DHTs are generally robust,
we do not evaluate their resistance to strategic or malicious behavior, instead opting to
use provided values as hints only. Identity is independently verified using cryptographic
keys and key
![]() IP mappings are locally cached.
IP mappings are locally cached.
State propagation: In the example of
Figure 7, peer pairs ![]() and
and ![]() learn
about one another directly through data transfer, requiring no
explicit signaling. However, when
learn
about one another directly through data transfer, requiring no
explicit signaling. However, when ![]() and
and ![]() meet, they must exchange
messages indicating which peers (possible intermediaries) they share
in common
and their status with those shared peers.
In our protocol, this is a multi-step process.
meet, they must exchange
messages indicating which peers (possible intermediaries) they share
in common
and their status with those shared peers.
In our protocol, this is a multi-step process.
In addition to facilitating identification of common intermediaries
among peer pairs (Steps 1, 2), top ![]() sets also bootstrap the local
histories of new peers in the system. Each entry in the topK message contains a bit indicating whether the entry
corresponds to an intermediary that can mediate a direct transfer or a
gossip entry for a popular intermediary with whom the sender does not
have a direct or indirect relationship. This is an optimization, effectively using
two hop propagation to bootstrap one hop reputations. A
client relying on direct, local observations alone to derive the
coverage of potential intermediaries would have to directly observe
them multiple times in distinct swarms
before identifying those with high coverage. In the interim, new users
would be unable to evaluate the quality of peers in good standing with
popular intermediaries. Instead of relying on direct observations
alone, peers may incorporate the gossip intermediaries included in the
top
sets also bootstrap the local
histories of new peers in the system. Each entry in the topK message contains a bit indicating whether the entry
corresponds to an intermediary that can mediate a direct transfer or a
gossip entry for a popular intermediary with whom the sender does not
have a direct or indirect relationship. This is an optimization, effectively using
two hop propagation to bootstrap one hop reputations. A
client relying on direct, local observations alone to derive the
coverage of potential intermediaries would have to directly observe
them multiple times in distinct swarms
before identifying those with high coverage. In the interim, new users
would be unable to evaluate the quality of peers in good standing with
popular intermediaries. Instead of relying on direct observations
alone, peers may incorporate the gossip intermediaries included in the
top ![]() sets of their directly connected peers, combining this
information with direct observations in their local history. Care must be taken
when incorporating this information to prevent
strategic manipulation, an issue we will discuss later.
sets of their directly connected peers, combining this
information with direct observations in their local history. Care must be taken
when incorporating this information to prevent
strategic manipulation, an issue we will discuss later.
Our state exchange protocol provides information about peers that enables a range of valuation policies. In this section, we propose a default policy designed to maximize coverage. However, peers are not required to follow this policy, and we present it as just one plausible design point among several alternatives. Other options are possible, e.g., trading coverage for resistance to strategic manipulation and collusion.
Our default policy is the indirection-enabled analogue of volume-based tit-for-tat. When a peer makes servicing decisions, it restricts contribution to only those peers who have a positive or near positive “balance” with the system as a whole. This limits the potential for free-riding, if most peers have a one hop basis for making decisions. In this section, we define precisely how each client ranks the requests of others using one hop information and how membership of possible intermediaries in the top ![]() set is decided.
set is decided.
Computing reputations: The value of a one hop reputation for
peer ![]() from the perspective of a peer
from the perspective of a peer ![]() is determined by three
factors: 1) the volume of data excshanged between
is determined by three
factors: 1) the volume of data excshanged between ![]() and
and ![]() (if any),
2)
(if any),
2) ![]() 's valuation of
's valuation of ![]() 's attesting intermediaries, and 3)
's attesting intermediaries, and 3) ![]() 's
reputation with each attesting intermediary. We denote
's
reputation with each attesting intermediary. We denote ![]() 's valuation of
intermediary
's valuation of
intermediary ![]() as
as ![]() and the valuation of peer
and the valuation of peer ![]() at
intermediary
at
intermediary ![]() by
by ![]() , defining these precisely in
Equations 1 and 2, respectively.
, defining these precisely in
Equations 1 and 2, respectively.
Top K membership: Our default policy for populating
top ![]() sets is based on the number of direct and indirect
observations of each potential intermediary. When a client directly
observes a peer, its occurrence count is incremented by one. In
addition to direct observation, our default policy also integrates
indirect observations in the form of top
sets is based on the number of direct and indirect
observations of each potential intermediary. When a client directly
observes a peer, its occurrence count is incremented by one. In
addition to direct observation, our default policy also integrates
indirect observations in the form of top ![]() sets from peers. In this
case, occurrence counts are updated fractionally, weighted by the
number of received bytes from the peer reporting an observation
relative to others in the recent past.
sets from peers. In this
case, occurrence counts are updated fractionally, weighted by the
number of received bytes from the peer reporting an observation
relative to others in the recent past.
If an intermediary is unavailable or refuses an update message, its occurrence count is reduced by 20% or 2, whichever is larger. This AIMD policy is intended to promote agreement on intermediaries with wide coverage while quickly pruning popular peers that become overwhelmed or unavailable. Overhead concerns are treated further in Section 4.1.
Liquidity: Peers have an incentive to keep in good standing with intermediaries that have high coverage. Peers gain standing with a popular intermediary by either satisfying its direct requests (direct contribution) or contributing to peers that have satisfied the intermediary's requests one hop removed (indirect contribution). In the former case, there is a net increase in the sum total of reputation values at the intermediary. In the latter case, the reputation of one peer is simply transferred to another. Thus, the sum total of reputation values at an intermediary—the liquidity the intermediary provides the system—is limited by the intermediary's demand. This can result in a disabling shortage. Two peers may share many intermediaries that cannot be used because of a lack of standing with those intermediaries, reducing the effective coverage of otherwise popular intermediaries. This situation will arise unless popular intermediaries generate enough demand to allow one hop trading in satisfying their requests to cover the remainder of demand in the system.
To address this problem, the demand recorded in attestation receipts obtained for direct contributions is inflated by a fixed amount by all intermediaries. Because the inflation factor depends on the fraction of total demand generated by popular intermediaries, its value is workload dependent. In our traces, the most popular 2000 peers account for 1.6% of total demand, suggesting that an inflation factor of 100 provides sufficient liquidity.
Although the demand of the minority of popular users relative to total user demand varies little over the course of our trace, this may not be a reliable workload characteristic. If fixed, a static inflation factor will suffice to maintain sufficient liquidity even as users join and leave the system. If not, intermediaries will need to adjust their value at the cost of introducing true economic inflation into the system. This requires only a policy change. Intermediaries can mint receipts with higher or lower byte values which peers can recognize and incorporate into their valuation of intermediaries.
Intermediary incentives: In addition to providing
sufficient liquidity, inflating the value recorded in attesting
receipts also creates an incentive to serve as an intermediary. In the
common case that two peers have not directly interacted, their
valuation of one another is based on standing with popular
intermediaries, trading in indirect attestations 1:1, i.e., 1 byte
contributed for 1 byte attested. But, satisfying an intermediary's
requests directly results in a 1:![]() exchange, where
exchange, where ![]() is the inflation factor of intermediary receipts. Because of their
higher returns, peers prioritize the requests of popular
intermediaries. This
preferential treatment requires an intermediary to continue
mediating transactions:
if it stops responding to queries and updates, it will be pruned from
the set of preferred intermediaries by peers that it ignores.
is the inflation factor of intermediary receipts. Because of their
higher returns, peers prioritize the requests of popular
intermediaries. This
preferential treatment requires an intermediary to continue
mediating transactions:
if it stops responding to queries and updates, it will be pruned from
the set of preferred intermediaries by peers that it ignores.
A large body of work on P2P reputation systems has documented a well-known set of challenges for incentive design. These include bootstrapping new users, Sybil attacks, collusion, and free-riding. To date, no comprehensive solution has emerged that addresses all of these issues, nor do we claim that our approach does. Instead, we have explicitly designed our system to separate the protocol mechanisms of reputation propagation and maintenance from the policy for acting on that information. As a result, our scheme supports a range of policies operating at different levels of vulnerability to well-known attacks. Our measurements of BitTorrent suggests that vulnerability to attack is a negative attribute, but not necessarily a fatal one. In this section, we detail several of these policies and the risks they carry.
Direct, deficit 1 block-based tit-for-tat: This is the most conservative policy we consider, ignoring most available information in the interest of (near) strategy-proof operation. Peers make the positive first step in the traditional tit-for-tat game, sending at most one unreciprocated data block to a peer. For strategic adversaries, attacks are limited. Free-riders obtain at most one block, and while they might collect many blocks by repeating the game with a large number of peers, our measurements show that most swarms have hundreds of peers or fewer while most objects are comprised of thousands of data blocks. Sybil attacks are similarly frustrated. Collusion carries little benefit—the valuation of a peer is based only on the directly observed behavior of that peer. Bootstrapping is straightforward, as adherents to this strategy willingly contribute the single data block needed to start playing the game. Finally, unfairness in data exchanged is sharply bounded per-peer. The strategic robustness of this approach comes primarily at the cost of a lack of long-term incentives; seeds would limit their contribution to just one block, further reducing availability.
Direct, volume-based tit-for-tat: This strategy eliminates the bound on unfairness in block deficit tit-for-tat. Peers contribute their full capacity, realizing that free-riders / Sybil identities might never reciprocate and seed contributions may never be repaid due to the small chance of repeat interactions. Willingness to make such contributions increases utilization while retaining the collusion resistance of local reasoning as in deficit tit-for-tat. However, because repeat interactions are infrequent, long-term contribution incentives remain weak.
Indirect contribution, reputation
![]() 1.0
1.0
![]() : This is our default policy. The value of
: This is our default policy. The value of ![]() controls the level of indirect imbalance a peer is willing to tolerate. However, because one hop reputations do not provide precise global accounting, peers contributing data due to third-party standing accept the risk that the intermediaries they choose to mediate an exchange may not have wide coverage. But, as we will show in Section 4, most one hop interactions can be mediated by multiple intermediaries with wide coverage for observed workloads.
controls the level of indirect imbalance a peer is willing to tolerate. However, because one hop reputations do not provide precise global accounting, peers contributing data due to third-party standing accept the risk that the intermediaries they choose to mediate an exchange may not have wide coverage. But, as we will show in Section 4, most one hop interactions can be mediated by multiple intermediaries with wide coverage for observed workloads.
Indirect / random excess contribution: For many types of strategic behavior, e.g., free-riding, limiting damage depends on reducing contributions when the reputation of a peer cannot be reliably ascertained. Much like the utilization / robustness tradeoff of deficit ![]() tit-for-tat, peers are faced with a choice when considering what to do with any excess capacity that remains after servicing all requests based on one hop information. Continuing to service requests—essentially at random—enables free-riding behavior, with its effectiveness growing as the amount of random contributions increases.
tit-for-tat, peers are faced with a choice when considering what to do with any excess capacity that remains after servicing all requests based on one hop information. Continuing to service requests—essentially at random—enables free-riding behavior, with its effectiveness growing as the amount of random contributions increases.
Permitting indirection greatly expands the range of attacks available to a strategic client or a set of colluding clients. We consider several attacks, but do not claim to make indirect contribution under our default policy fully resistant to all forms of strategic or malicious behavior. For increased robustness, clients are free to adopt an alternate policy that is more conservative.
Comprehensive evaluation of incentive systems is often frustrated by an overabundance of metrics. For example, protocol designers can choose among fairness, utilization, bootstrapping time, overhead, and resistance to strategic or malicious behavior. As we observed in Section 3.3, optimizing for one of these metrics often comes at the expense of another. Further, evaluating the ability of an incentive strategy to promote long-term incentives—a necessity for increasing availability in P2P systems—requires a model of user behavior that is itself long-term.
In this section, we provide a threefold analysis of our system to partially address these evaluation challenges. First, we describe the key parameters of our prototype implementation. These parameters control overhead, which we evaluate for our observed workload. Second, we use trace data to examine the coverage of one hop reputations; coverage distills many existing metrics for the quality of reputation systems including bootstrapping time, susceptibility to free-riding, and return on investment. Finally, we report experimental results obtained on PlanetLab using a prototype implementation of our system that we have layered on top of the popular Azureus BitTorrent client. Our PlanetLab experiments measure the real-world performance improvement that can be obtained by using the additional information one hop reputations provide.
|
Section 3 describes how reputation information is propagated and used by peers, but we have deliberately delayed assigning several workload-dependent parameters to provide context. These parameters and the values assigned in our prototype are listed in Table 2. We consider the influence of each of these parameters.
Top K set size: The exchange of top ![]() sets serves two purposes. First, it allows peers to agree on shared intermediaries for data exchange. Second, it allows peers to quickly learn which intermediaries have wide coverage (and are therefore most valuable). When
sets serves two purposes. First, it allows peers to agree on shared intermediaries for data exchange. Second, it allows peers to quickly learn which intermediaries have wide coverage (and are therefore most valuable). When ![]() is large, peers have a higher chance of discovering shared intermediaries and information about intermediaries is propagated more rapidly. In our implementation, peers exchange top
is large, peers have a higher chance of discovering shared intermediaries and information about intermediaries is propagated more rapidly. In our implementation, peers exchange top ![]() sets of size 2000. As each entry in the set is a 128 bit public key identifying an intermediary and a gossip bit, bidirectional exchange requires less than 64 kilobytes of data per peer connection, a small fraction of the megabytes of object data typically transferred between peer pairs.
sets of size 2000. As each entry in the set is a 128 bit public key identifying an intermediary and a gossip bit, bidirectional exchange requires less than 64 kilobytes of data per peer connection, a small fraction of the megabytes of object data typically transferred between peer pairs.
Synchronization, mediating intermediaries: The intersection of top ![]() sets forms a set of possible intermediaries that can facilitate indirect reciprocation. Of these, peers in our implementation select a random subset of size 10 to act as the mediators for the transfer. Clients synchronize state with intermediaries after every 10 MB transferred. This parameter controls the update burden on the most popular intermediaries, a potential scalability bottleneck.
sets forms a set of possible intermediaries that can facilitate indirect reciprocation. Of these, peers in our implementation select a random subset of size 10 to act as the mediators for the transfer. Clients synchronize state with intermediaries after every 10 MB transferred. This parameter controls the update burden on the most popular intermediaries, a potential scalability bottleneck.
We measure the number of updates at popular intermediaries using our trace data. Total demand of the 14 million peers in our trace, calculated by counting distinct peers in each swarm and multiplying by swarm file size, is 26,752 terabytes (roughly 2 GB per user). Assuming perfect agreement and static membership in top ![]() sets, each of the most popular intermediaries will need to process 1.4 million updates
sets, each of the most popular intermediaries will need to process 1.4 million updates
![]() . Updates are signed and include a hash (16 bytes), timestamp (4 bytes), 128 bit sender and receiver public keys (32 bytes), and bytes sent and received (16 bytes, 68 bytes total). These updates will be distributed over intermediaries, yielding an overhead of 3 MB per day for each popular intermediary
. Updates are signed and include a hash (16 bytes), timestamp (4 bytes), 128 bit sender and receiver public keys (32 bytes), and bytes sent and received (16 bytes, 68 bytes total). These updates will be distributed over intermediaries, yielding an overhead of 3 MB per day for each popular intermediary
![]() . In practice, individual peers will differ in their views of the quality of intermediaries, reducing load, and will also differ in their relative share of total demand and hence update traffic. Also, data exchange between actively downloading peers will be mediated by direct tit-for-tat after the initial exchange, further reducing load. Finally, the size of top
. In practice, individual peers will differ in their views of the quality of intermediaries, reducing load, and will also differ in their relative share of total demand and hence update traffic. Also, data exchange between actively downloading peers will be mediated by direct tit-for-tat after the initial exchange, further reducing load. Finally, the size of top ![]() sets can be increased if necessary to further distribute load.
sets can be increased if necessary to further distribute load.
For our system to work well, the key factor is whether or not the majority of interactions have a one hop basis for computing reputations. In short, do one hop reputations provide good coverage? We find that they do, arriving at this conclusion using our BT-2 trace of peer interactions to examine the number of overlapping peers in randomly chosen top ![]() sets, assuming all peers use one hop reputations and the parameters of Table 2. Figure 9 shows the number of shared intermediaries between two randomly chosen peers with local histories built up according to our trace. This data indicates the amount of local history that peers can build. Some users participate in only a few swarms, while others participate in hundreds. Applying one hop reputations provides a measure of both coverage and convergence. Coverage is measured by pairwise overlap among the top
sets, assuming all peers use one hop reputations and the parameters of Table 2. Figure 9 shows the number of shared intermediaries between two randomly chosen peers with local histories built up according to our trace. This data indicates the amount of local history that peers can build. Some users participate in only a few swarms, while others participate in hundreds. Applying one hop reputations provides a measure of both coverage and convergence. Coverage is measured by pairwise overlap among the top ![]() sets of randomly matched peers. The median number of shared intermediaries is 83 and more than 99% of peers have at least one common entry in their top
sets of randomly matched peers. The median number of shared intermediaries is 83 and more than 99% of peers have at least one common entry in their top ![]() sets. The most useful shared intermediaries are those with wide coverage, and we say that a top
sets. The most useful shared intermediaries are those with wide coverage, and we say that a top ![]() set has converged if it overlaps with the most widely used intermediaries measured over the top
set has converged if it overlaps with the most widely used intermediaries measured over the top ![]() sets of all peers. For some long-lived peers that participate in many swarms, convergence is high, but other peers participate in only a few swarms, limiting their view. When intermediaries with relatively limited coverage mediate transfers, the potential for returns is diminished. Fortunately, our data shows that most randomly matched peers share several intermediaries that are among the 2000 with widest coverage (Global overlap, Figure 9).
sets of all peers. For some long-lived peers that participate in many swarms, convergence is high, but other peers participate in only a few swarms, limiting their view. When intermediaries with relatively limited coverage mediate transfers, the potential for returns is diminished. Fortunately, our data shows that most randomly matched peers share several intermediaries that are among the 2000 with widest coverage (Global overlap, Figure 9).
Most peers have several choices when deciding which intermediaries to use to mediate their transfers. Using all available intermediaries or only several of the most popular distributes the risk of choosing an intermediary with poor coverage, but contacting potentially hundreds of shared intermediaries per-peer increases overhead. Popular intermediaries that become overloaded may refuse updates from peers that generate too many. To avoid this, we evaluate a default policy of randomly choosing a maximum of ten intermediaries from the shared set for randomly paired peers. Section 4.1 describes how this limit controls overhead. In Figure 10, we examine whether good coverage can be maintained given this limit, finding that even when randomly subsampling shared intermediaries, most interactions will still be mediated through several with wide coverage. 96% of randomly chosen peer pairs share an intermediary that is among the 2000 most popular when randomly sub-sampling, with a median overlap of size 9.
In the remainder of this section, we describe the implications of high one hop coverage on three properties: bootstrapping time for new users, free-riding, and return on investment for contributions.
Bootstrapping new users: Coverage of popular intermediaries and convergence of top ![]() sets controls the bootstrapping time of one hop reputations. The results of Figures 9 and 10 demonstrate that agreement among top
sets controls the bootstrapping time of one hop reputations. The results of Figures 9 and 10 demonstrate that agreement among top ![]() sets is high, assuming local history built up according to our trace. This includes peers that have participated in the system at least once. We next examine how quickly one hop reputations can bootstrap new peers that have no local history. Bootstrapping a one hop reputation is a two step process. First, clients need enough observations to ascertain which intermediaries have high coverage. Second, they need to encounter peers that have established relationships with high coverage intermediaries. We consider both aspects.
sets is high, assuming local history built up according to our trace. This includes peers that have participated in the system at least once. We next examine how quickly one hop reputations can bootstrap new peers that have no local history. Bootstrapping a one hop reputation is a two step process. First, clients need enough observations to ascertain which intermediaries have high coverage. Second, they need to encounter peers that have established relationships with high coverage intermediaries. We consider both aspects.
Taken together, these results show that new users are likely to both encounter an opportunity to gain standing with a popular intermediary (Figure 12) and recognize that opportunity (Figure 11).
Free-riding: The coverage achieved by one hop reputations for today's workloads suggests that free-riding can be deterred without the significant sacrifices in utilization required by schemes such as deficit 1 block-based tit-for-tat. Because peers usually have a one hop basis for making servicing decisions, the majority of each user's capacity can be allocated to peers that can demonstrate their contributions. However, we do not claim that one hop reputations prohibit free-riding, as selfish peers in large swarms may still be able to scavenge enough altruistic excess capacity to complete file downloads. Rather, our goal is simply to limit the opportunities for effective free-riding by providing peers with more information. Under today's reputation systems, the random contributions that enable free-riding are necessary because obtaining information about good peers requires making contributions to all peers, beneficial or not.
Return on investment: The return on investment for contributed bytes is the amount of reciprocated bytes generated by that contribution. For reputations that persist over short time periods, as in BitTorrent's tit-for-tat, return on investment is immediate and can be measured or computed. For persistent reputation schemes, however, return on investment can be a misleading measure of incentive strength. For instance, volume-based tit-for-tat maintains state regarding each contribution, providing 1:1 returns on all contributions eventually if peers do not leave the system permanently and continue to make requests. But, as we observed in Section 2.4, repeat, direct interactions are extremely rare for today's workloads, suggesting that peers would need to tolerate lengthy delays before receiving reciprocation. Particularly in P2P networks, waiting for reciprocation opportunities dampens returns as some peer departures are permanent.
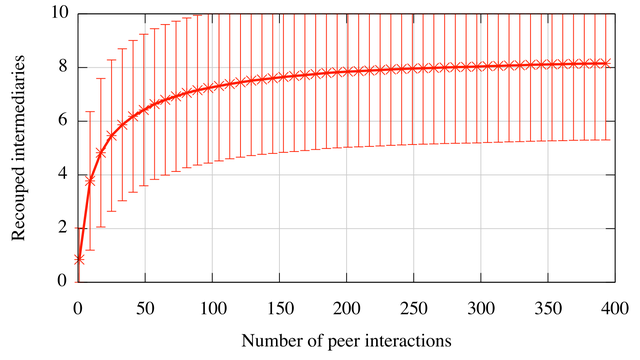
Because one hop reputations have persistent memory, we evaluate the returns from contribution in terms of the number of interactions required to recoup contributed bytes. Each time a peer contributes data due to indirect, one hop standing, that contribution is mediated through a subset of the shared intermediaries between sender and receiver. The contributing peer earns reciprocation for that contribution only if it later can use some of those intermediaries to mediate another transfer where it acts as receiver. A contributing peer will see poor returns if it selects a mediating intermediary that has poor coverage.
We use the one hop reputations for peers in our BT-2 trace to compute the number of interactions required to repeat the use of an intermediary from the set mediating a random initial contribution. Figure 13 shows results averaged over 1000 trials with error bars showing standard deviation. For each sample, we compute a size 10 random subset of shared intermediaries between two randomly drawn peers, interpreting this set as the mediating intermediaries in a potential transfer. We then repeat this process, computing the overlap between subsequent mediating sets and the original contribution set. Figure 13 shows that, on average, peers will encounter 8 of the 10 initially used intermediaries within a few hundred peer interactions. Although this implies that returns for one hop contributions are not 1:1 for our default policy, peers do see a higher opportunity for returns on contributions when compared with direct, long-term reciprocation schemes that require tens of thousands of interactions before payback occurs, if at all.
Our evaluation thus far has focused on the ability of one hop reputations to promote strong contribution incentives through wide coverage and returns on contribution, improving performance by providing users with a reason to contribute more capacity. In this section, we focus on the concrete performance improvement one hop reputations can provide, regardless of strengthened incentives.
Because one hop reputations include not only an accounting of transfers but also the rate of those transfers (ref. Table 1), users can make intelligent decisions about which peers are likely to disseminate data rapidly. In BitTorrent today, peers do not maintain historical information about peer capacities and must rely on tit-for-tat to funnel data to high capacity peers. Unfortunately, high capacity goes unnoticed by tit-for-tat when the data available to trade is the limiting factor for performance, as is the case when a file first becomes available or when seed capacity is limited. In both cases, quickly utilizing the full capacity of the swarm depends on high capacity peers receiving data first so they can quickly replicate it, reducing the amount of time required for other peers to gain data to trade.
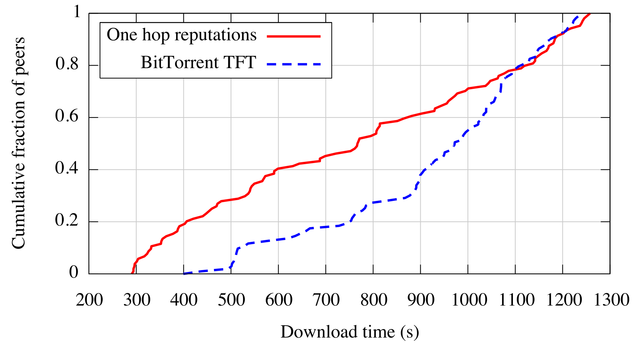
To measure the performance benefit realized by using rate information, we deployed our prototype one hop reputation implementation on PlanetLab, comparing its performance with the original Azureus BitTorrent implementation on which it is layered. Figure 14 compares the completion times for 100 peers downloading a 25 MB file using BitTorrent in one trial and one hop reputations in the next with simultaneous arrivals in both trials. Before conducting the one hop download trial, we first primed the local histories of participants by distributing a different 25 MB file. We record the download times required to download the second file while using the local history built up during the priming run. To adhere to the skewed bandwidth distribution typical of end-hosts in BitTorrent swarms, we used application level bandwidth capacity limits with values drawn from the percentiles of the end-host capacity distribution for BitTorrent clients given in [12].
One hop reputations improve performance for roughly 75% of PlanetLab hosts, providing a median reduction in download time from 972 seconds to 766 seconds. This performance improvement is attributable to the ability of historical information to allow peers to quickly find good tit-for-tat peerings. This is particularly true for the seed, which distributes data randomly in the reference implementation of BitTorrent. Rather than relying on random selection, a one hop seed can preferentially give data to users it knows have high capacity. These peers amplify the initial contributions of the seed, pumping data into the systems rapidly and increasing utilization relative to that of random selection, which may give initial data to slow peers that cannot quickly replicate it.
Our focus on incentives has led us to build a protocol layer for exchanging peer reputation information, one that can be shared across time and across content distribution applications. While incentives could be added to any content distribution system, it can be quite difficult to design a robust incentive system when participation is ephemeral and identities are not persistent, as we have seen in BitTorrent.
The research community has made considerable progress towards understanding BitTorrent dynamics; we use many of these insights in the design of our one hop reputation system. Qui and Srikant [15] analytically model the BitTorrent protocol, showing that in certain conditions, it achieves a Nash equilibrium. Unfortunately, our measurements show that these conditions are typically not met in practice in live BitTorrent usage. Bharambe et al. [2] use simulation to show that BitTorrent engages in progressive taxation, taking from high capacity peers to give unreciprocated bandwidth to low capacity peers. BitTyrant [12] exploits this observation, showing that clients can strategically deploy their upload bandwidth to significantly improve their local performance, and in the bargain, reduce performance of the swarm. Locher et al. [11] and Sirivianos et al. [16] made similar points, showing that BitTorrent provides weak protection against free riding clients. Our measurement results of BitTorrent in the wild are compatible with the results of those papers, expanding on previous studies of only a subset of swarms with a large number of active downloaders. Our data is broader, showing that in most BitTorrent swarms incentives are inoperable. Wang et al. [18] and Tribler [13] argue for using third party helpers to improve client performance in BitTorrent. While we show that increased upload contribuion only marginally improves download rates in BitTorrent, instead we generalize the notion of helpers, using one hop reputations to provide an incentive for third parties to do work on behalf of others.
Our work has the most in common with recent work on the design of reputation systems for various P2P applications. Karma [17] focuses on building a robust, incentive compatible distributed hash table as a basis for trading a digital currency. DHTs are a particularly difficult venue for robust incentives, as peers are both ephemeral and have little repeated interaction. To address this, Karma sets up a replicated system of banks on top of the DHT to serve as reputation authorities. In our one hop reputation system, popular nodes serve as a kind of ad-hoc bank without any additional mechanism beyond peer gossip of popular nodes and signed receipts. Our use of indirection is similar in some respects to EigenTrust [9] and multi-level tit-for-tat [21]. EigenTrust focused on the problem of inauthentic files, computing a global reputation for every participant. Reputations in our system are local, and clients are free to evolve their strategy independently over time. Multi-level tit-for-tat demonstrated that much of the value of EigenTrust can be achieved with only a few levels of indirection, an insight we use in the design of one hop reputations.
Finally, we observe that our protocol for propagating reputations allows peers to make their own policy decisions, making it possible for peers to choose among policies for allocating their bandwidth. As such, the one hop protocol may also be able to incorporate a number of previously proposed reputation systems, such as Bayesian estimation [3], PPay [20], PeerTrust [19], among others [5,7]. However, we must leave the full exploration of these issues to future work.
To deliver on their potential benefits, P2P systems need robust contribution incentives. In this paper, we have described the pitfalls undermining currently deployed incentive strategies, finding that decisions based on direct observations and local history will not suffice to overcome the performance and availability problems on which today's P2P networks falter. Our measurements motivate the design of one hop reputations, a protocol for propagating reputations that extends the information peers have available for making servicing decisions. We propose a default policy for the use of this information, finding that for observed workloads, one hop reputations can provide wide coverage and positive, long-term contribution incentives. Through deployment on PlanetLab, we show that one hop reputations can improve short-term download performance for peers as well.
We would like to thank the anonymous reviewers and our shepherd, Emin Gün Sirer, for their valuable feedback. This research was partially supported by the National Science Foundation, CSR-PDOS #0720589.