This section details the design and implementation of four sample file systems we wrote based on Wrapfs. The examples range from simple to complex:
These examples are experimental and intended to illustrate the kinds of file systems that can be written using Wrapfs. We do not consider them to be complete solutions. Whenever possible, we illustrate potential enhancements to our examples. We hope to convince readers of the flexibility and simplicity of writing new file systems using Wrapfs.
Users' home directory files are often considered private and personal. Normally, these files are read by their owner or by the root user (e.g., during backups). Other sanctioned file access includes files shared via a common Unix group. Any other access attempt may be considered a break-in attempt. For example, a manager might want to know if a subordinate tried to cd to the manager's ~/private directory; an instructor might wish to be informed when anyone tries to read files containing homework solutions.
The one place in a file system where files are initially searched is the vnode lookup routine. To detect access problems, we first perform the lookup on the lower file system, and then check the resulting status. If the status was one of the error codes ``permission denied'' or ``file not found,'' we know that someone was trying to read a file they do not have access to, or they were trying to guess file names. If we detect one of these two error codes, we also check if the current process belongs to the super-user or the file's owner by inspecting user credentials. If it was a root user or the owner, we do nothing. Otherwise we print a warning using the in-kernel log facility. The warning contains the file name to which access was denied and the user ID of the process that tried to access it.
We completed the implementation of Snoopfs in less than one hour (on all three platforms). The total number of lines of C code added to Wrapfs was less than 10.
Snoopfs can serve as a prototype for a more elaborate intrusion detection file system. Such a file system can prohibit or limit the creation or execution of setuid/setgid programs; it can also disallow overwriting certain executables that rarely change (such as /bin/login) to prevent attackers from replacing them with trojans.
Lb2fs is a trivial file system that multiplexes file access between two identical replicas of a file system, thus balancing the load between them. To avoid concurrency and consistency problems associated with writable replicas, Lb2fs is a read-only file system: vnode operations that can modify the state of the lower file system are disallowed. The implementation was simple; operations such as write, mkdir, unlink, and symlink just return the error code ``read-only file system.'' We made a simplifying assumption that the two replicas provide service of identical quality, and that the two remote servers are always available, thus avoiding fail-over and reliability issues.
The one place where new vnodes are created is in the lookup function. It takes a directory vnode and a pathname and it returns a new vnode for the file represented by the pathname within that directory. Directory vnodes in Lb2fs store not one, but two vnodes of the lower level file systems--one for each replica; this facilitates load-balancing lookups in directories. Only non-directories stack on top of one vnode, the one randomly picked. Lb2fs's lookup was implemented as follows:
The implications of this design and implementation are twofold. First, once a vnode is created, all file operations using it go to the file server that was randomly picked for it. A lookup followed by an open, read, and close of a file, will all use the same file server. In other words, the granularity of our load balancing is on a per-file basis.
Second, since lookups happen on directory vnodes, we keep the two lower directory vnodes, one per replica. This is so we can randomly pick one of them to lookup a file. This design implies that every open directory vnode is opened on both replicas, and only file vnodes are truly randomly picked and load-balanced. The overall number of lookups performed by Lb2fs is twice for directory vnodes and only once for file vnodes. Since the average number of files on a file system is much larger than the number of directories, and directory names and vnodes are cached by the VFS, we expect the performance impact of this design to be small.
In less than one day we designed, implemented, tested, and ported Lb2fs. Many possible extensions to Lb2fs exist. It can be extended to handle three or a variable number of replicas. Several additional load-balancing algorithms can be implemented: round-robin, LRU, the most responsive/available replica first, etc. A test for downed servers can be included so that the load-balancing algorithm can avoid using servers that recently returned an I/O error or timed out (fail-over). Servers that were down can be added once again to the available pool after another timeout period.
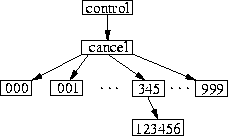
One cause of high loads on news servers in recent years has been the need to process many articles in very large flat directories representing newsgroups such as control.cancel and misc.jobs.offered. Significant resources are spent on processing articles in these few newsgroups. Most Unix directories are organized as a linear unsorted sequence of entries. Large newsgroups can have hundreds of thousands of articles in one directory, resulting in delays processing any single article.
When the operating system wants to lookup an entry in a directory with Nentries, it may have to search all N entries to find the file in question. Table 2 shows the frequency of all file system operations that use a pathname on our news spool over a period of 24 hours.
It shows that the bulk of all operations are for looking up files, so these should run very fast regardless of the directory size. Operations that usually run synchronously (unlink and create) account for about 10% of news spool activity and should also perform well on large newsgroups.
Usenetfs is a file system that rearranges the directory structure from being flat to one with small directories containing fewer articles. By breaking the structure into smaller directories, it improves the performance of looking up, creating, or deleting files, since these operations occur on smaller directories. The following sections summarize the design and implementation of Usenetfs. More detailed information is available in a separate report[23].
We had three design goals for Usenetfs. First, Usenetfs should not require changing existing news servers, operating systems, or file systems. Second, it should improve performance of these large directories enough to justify its overhead and complexity. Third, it should selectively manage large directories with little penalty to smaller ones.
The main idea for improving performance for large flat directories is to
break them into smaller ones. Since article names are composed of
sequential numbers, we take advantage of that. We create a hierarchy
consisting of one thousand directories as depicted in Figure
4.
Usenetfs needs to determine if a directory is managed or not. We co-opted a seldom used mode bit for directories, the setuid bit, to flag a directory as managed by Usenetfs. Using this bit lets news administrators control which directories are managed, using a simple chmod command.
The last issue was how to convert an unmanaged directory to be managed by Usenetfs: creating some of the 000-999 subdirectories and moving existing articles to their designated locations. Experimentally, we found that the number of truly large newsgroups is small, and that they rarely shrunk. Given that, and for simplicity, we made the process of turning directory management on/off an off-line process triggered by the news administrator with a provided script.
Usenetfs is the first non-trivial file system we designed and implemented using Wrapfs. By ``non-trivial'' we mean that it took us more than a few hours to achieve a working prototype from the Wrapfs template. It took us one day to write the first implementation, and several more days to test it and alternate restructuring algorithms (discussed elsewhere[23]).
We accomplished most of the work in the functions encode_filename and decode_filename. They check the setuid bit of the directory to see if it is managed by Usenetfs; if so, they convert the filename to its managed representation and back.
Cryptfs is the most involved file system we designed and implemented based on Wrapfs. This section summarizes its design and implementation. More detailed information is available elsewhere[24].
We used the Blowfish[17] encryption algorithm--a 64 bit block cipher designed to be fast, compact, and simple. Blowfish is suitable in applications where the keys seldom change such as in automatic file decryptors. It can use variable length keys as long as 448 bits. We used 128 bit keys.
We picked the Cipher Block Chaining (CBC) encryption mode because it allows us to encrypt byte sequences of any length--suitable for encrypting file names. We decided to use CBC only within each encrypted block. This way ciphertext blocks (of 4-8KB) do not depend on previous ones, allowing us to decrypt each block independently. Moreover, since Wrapfs lets us manipulate file data in units of page size, encrypting them promised to be simple.
To provide stronger security, we encrypt file names as well. We do not encrypt ``.'' and ``..'' to keep the lower level Unix file system intact. Furthermore, since encrypting file names may result in characters that are illegal in file names (nulls and ``/''), we uuencode the resulting encrypted strings. This eliminates unwanted characters and guarantees that all file names consist of printable valid characters.
Only the root user is allowed to mount an instance of Cryptfs, but can not automatically encrypt or decrypt files. To thwart an attacker who gains access to a user's account or to root privileges, Cryptfs maintains keys in an in-memory data structure that associates keys not with UIDs alone but with the combination of UID and session ID. To acquire or change a user's key, attackers would not only have to break into an account, but also arrange for their processes to have the same session ID as the process that originally received the user's passphrase. This is a more difficult attack, requiring session and terminal hijacking or kernel-memory manipulations.
Using session IDs to further restrict key access does not burden users during authentication. Login shells and daemons use setsid(2) to set their session ID and detach from the controlling terminal. Forked processes inherit the session ID from their parent. Users would normally have to authorize themselves only once in a shell. From this shell they could run most other programs that would work transparently and safely with the same encryption key.
We designed a user tool that prompts users for passphrases that are at least 16 characters long. The tool hashes the passphrases using MD5 and passes them to Cryptfs using a special ioctl(2). The tool can also instruct Cryptfs to delete or reset keys.
Our design decouples key possession from file ownership. For example, a group of users who wish to edit a single file would normally do so by having the file group-owned by one Unix group and add each user to that group. Unix systems often limit the number of groups a user can be a member of to 8 or 16. Worse, there are often many subsets of users who are all members of one group and wish to share certain files, but are unable to guarantee the security of their shared files because there are other users who are members of the same group; e.g., many sites put all of their staff members in a group called ``staff,'' students in the ``student'' group, guests in another, and so on. With our design, users can further restrict access to shared files only to those users who were given the decryption key.
One disadvantage of this design is reduced scalability with respect to the number of files being encrypted and shared. Users who have many files encrypted with different keys have to switch their effective key before attempting to access files that were encrypted with a different one. We do not perceive this to be a serious problem for two reasons. First, the amount of Unix file sharing of restricted files is limited. Most shared files are generally world-readable and thus do not require encryption. Second, with the proliferation of windowing systems, users can associate different keys with different windows.
Cryptfs uses one Initialization Vector (IV) per mount, used to jump-start a sequence of encryption. If not specified, a predefined IV is used. A superuser mounting Cryptfs can choose a different IV, but that will make all previously encrypted files undecipherable with the new IV. Files that use the same IV and key produce identical ciphertext blocks that are subject to analysis of identical blocks. CFS[2] is a user level NFS-based encryption file system. By default, CFS uses a fixed IV, and we also felt that using a fixed one produces sufficiently strong security.
One possible extension to Cryptfs might be to use different IVs for different files, based on the file's inode number and perhaps in combination with the page number. Other more obvious extensions to Cryptfs include the use of different encryption algorithms, perhaps different ones per user, directory, or file.