In this section, we measure the performance of the security mechanism
as implemented by the monitors. We first make micro-benchmarks of the
individual steps in the monitoring mechanism. We then estimate the
ideal performance (ignoring effects of TLB and cache misses) of
authorized IPC from these benchmarks. We estimate that an authorized
IPC (one-way) using active capabilities could be as fast as 4 ![]() s
(and typically less than 9
s
(and typically less than 9 ![]() s ideally). In our current
implementation, our fastest one-way IPC is 9.5
s ideally). In our current
implementation, our fastest one-way IPC is 9.5 ![]() s (authorized
using active capabilities). If we have 30,000 average authorized IPCs
per second and 10% of these are bind operations (which is a very
conservative estimate), then the ideal performance cost is about 20%.
We have measured the cost of 30,000 actual active IPCs per second to
be 30-40% (9.5
s (authorized
using active capabilities). If we have 30,000 average authorized IPCs
per second and 10% of these are bind operations (which is a very
conservative estimate), then the ideal performance cost is about 20%.
We have measured the cost of 30,000 actual active IPCs per second to
be 30-40% (9.5 ![]() s per IPC). These numbers are well
below the 600% to 800% performance cost for IPC alone for COM
objects on Windows NT. Since compiled code may be executed in the
remaining 60-70% of the time, the performance impact of IPC interception
relative to language-based models may be negligible. In addition, we
believe that the number of IPCs can be reduced significantly by
judicious code placement (taking security requirements into account)
and precreation of active capabilities.
s per IPC). These numbers are well
below the 600% to 800% performance cost for IPC alone for COM
objects on Windows NT. Since compiled code may be executed in the
remaining 60-70% of the time, the performance impact of IPC interception
relative to language-based models may be negligible. In addition, we
believe that the number of IPCs can be reduced significantly by
judicious code placement (taking security requirements into account)
and precreation of active capabilities.
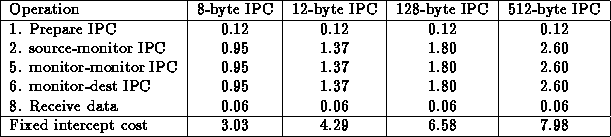
For our performance analysis, we have measured the costs of monitoring operations on a 166 MHz Pentium PC with 256K L2 cache. In our measured scenario, we have two controlled tasks, and each has a monitor that authorizes its IPC. The controlled tasks ping-pong requests back and forth, and we measure the time it takes for the authorized IPCs.
When a controlled process calls an operation the following actions are taken to authorize and forward the operation to its destination task.
Operations 1 and 8 are trivial and simply prepare to send an IPC or
receive the IPC. Operations 2, 5, and 6 are all basically IPC
operations (perhaps with data copying). Operations 3, 4, and 7
implement our authorization mechanism. The costs of all operations
except 3 and 4 are fixed for messages of the same size. Therefore, we
first list the performance costs of the fixed operations. These
values are shown in Table 5. As shown, the fixed costs
for monitoring in this configuration vary from 3.03 to 7.98 ![]() s
depending on the amount of data to be copied.
s
depending on the amount of data to be copied.
Table 1: Performance of fixed interception actions (all times in ![]() s)
s)
A response to an operation goes through the same path, except that a
new active capability descriptor may be created for a bind operation
(e.g., file open). We measured the cost of active capability
descriptor creation for a UNIX file descriptor to be 0.69 ![]() s.
Cost is kept low by pre-allocating (and reusing) the memory for these
descriptors. Of course, active capabilities may be created at content
load time to avoid bind operations.
s.
Cost is kept low by pre-allocating (and reusing) the memory for these
descriptors. Of course, active capabilities may be created at content
load time to avoid bind operations.
The cost of deriving the authorization requirements is based on the
costs of retrieving the operation authorization, determining the
operands to authorize, and determining the operations to authorize
upon the operands. We compare the costs for evaluating the operation
authorizations for two operations: UNIX-style file open and file
write. The write operation is an active operation in
which only the first operand is authorized for write permission.
Therefore, an operation authorization's ops operand indicates
that the write operation is to be authorized and the a
type indicates that active capabilities are used to authorize only
the first operand (0.41 ![]() s). The open operation is a bind
operation in which the third operand indicates the actual operations
that need to be authorized upon the first operand. Therefore, the
operation authorization's ops operand indicates that
the third operand's value determines the operations to authorize
(using the op vector) and the a type indicates a bind
operation in which only the first operand is authorized (0.48
s). The open operation is a bind
operation in which the third operand indicates the actual operations
that need to be authorized upon the first operand. Therefore, the
operation authorization's ops operand indicates that
the third operand's value determines the operations to authorize
(using the op vector) and the a type indicates a bind
operation in which only the first operand is authorized (0.48 ![]() s).
s).
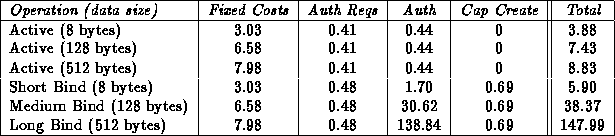
Both the Lava Nucleus and language-based security systems must authorize bind operations (e.g., file open and socket connect). Language-based systems do not authorize further use of the resultant descriptors (i.e., access operations), so they cannot revoke them. In Table 5, we show the costs of authorizing using both authorization (for a bind operation) and access capabilities (for an access operation). As will be the case in language-based systems, the cost of verifying operations using authorization capabilities varies based on the size of the object name string (e.g., file path) and the number of authorization capabilities that are examined. In this example, the authorization capability verification does not include additional actions, such as checking inode information. We would expect similar performance for authorization in language-based system given that both systems are optimized.
Authorization using active capabilities also includes the time for
retrieving the active capability from the descriptor (approximately
0.20 ![]() s).
s).
Table 2: Performance of authorization
Table 5 summarizes the performance of the Lava security
model using address space protection. For access operations, IPC
costs range from about 4 to 9 ![]() s depending on the amount of data
to be copied. Given 30,000 4
s depending on the amount of data
to be copied. Given 30,000 4 ![]() s IPCs per second, a 12%
overhead on processing is incurred. This percentage can be reduced by
the percentage of IPCs that can be eliminated by linking content in
the same address space. Bind operations can incur a much greater cost
(6 to 150+
s IPCs per second, a 12%
overhead on processing is incurred. This percentage can be reduced by
the percentage of IPCs that can be eliminated by linking content in
the same address space. Bind operations can incur a much greater cost
(6 to 150+ ![]() s). However, language-based implementations also
need to perform the same bind operations (either at load time for a
new class or access time for system objects), so the operating system
implementation should be faster. In general, since active capability
creation is a reasonable cost operation, where possible, it should be
used to eliminate unnecessary bind operations.
s). However, language-based implementations also
need to perform the same bind operations (either at load time for a
new class or access time for system objects), so the operating system
implementation should be faster. In general, since active capability
creation is a reasonable cost operation, where possible, it should be
used to eliminate unnecessary bind operations.
Table 3: Performance for different types of authorizations and data
sizes (all times in ![]() s)
s)
The actual performance of the entire IPC path for an active operation
using 8-byte IPCs is 9.5 ![]() s if the monitors and controlled
processes are small-address-space tasks and 14
s if the monitors and controlled
processes are small-address-space tasks and 14 ![]() s if only the
monitors are small-address-space tasks. In the small-address-space
case, the additional costs are incurred by the 22 cache misses on data
and an slightly higher IPC cost for redirected IPC than the basic IPC
benchmarked above. In the large-address-space case, TLB misses become
a factor. Despite the performance degradation from ideal, the overall
performance for 30,000 IPCs per second is about 30% for
small-address-space content processes and 40% for large-address-space
content processes.
s if only the
monitors are small-address-space tasks. In the small-address-space
case, the additional costs are incurred by the 22 cache misses on data
and an slightly higher IPC cost for redirected IPC than the basic IPC
benchmarked above. In the large-address-space case, TLB misses become
a factor. Despite the performance degradation from ideal, the overall
performance for 30,000 IPCs per second is about 30% for
small-address-space content processes and 40% for large-address-space
content processes.
Unfortunately, we do not yet have performance numbers for handling large data transfers. However, the use of shared memory between monitors and a monitor and its controlled process can reduce the performance impact (if security requirements allow its use). For example, on a write operation, only the reference to the data and the data size need to be copied to the monitor for integrity reasons. If the controlled task modifies the data, it has no effect on the security of the operation as long as the operation does not complete before the data is copied to the destination. Therefore, only a single copy of the write data from the destination's monitor to destination is really required. Therefore, 8-byte IPCs can be used on two of the three IPCs in the authorized path. Also, Lava enables flexible memory mapping, so a bind operation that enables a large amount of data transfer may prepare shared memory for implementing such transfers efficiently.
Therefore, we believe that the performance of an operating system-level mechanism for controlling fine-grained is comparable to that of a language-based mechanism, particularly if references are typically passed between processes rather than object data. Since compiled code can execute significantly faster than JIT Java code, it is not unreasonable to estimate that the compiled code can do more processing in the remaining 60-70% of the time than the Java code can do in 100% of the time. Given the additional security benefits of operating system and address space protection (execute compiled code with complete mediation), these security models are worthy of strong consideration.