The use of a distributed file system on a mobile client is often hindered by poor network connectivity. Although disconnected operation [8] is feasible, a mobile client with an extensive amount of updates should not defer propagating them to a server for too long. Damage, theft or destruction of the client before update propagation will result in loss of those updates. Further, their timely propagation may be critical to successful collaboration and in reducing the likelihood of update conflicts.
Propagation of updates from a mobile client is often impeded by weak connectivity in the form of wireless or wired networks that are low-bandwidth or intermittent. Aggressive update propagation under these conditions increases the demand on scarce bandwidth. A major component to bandwidth demand is the shipping of large files in their entirety. Two obvious solutions to the problem are delta shipping and data compression. The former tries to ship only the incremental differences between versions of files, and the latter ``compresses out'' the redundancies of files before shipping the files. Unfortunately, as discussed later in this paper, both of these methods have shortcomings that limit their usefulness.
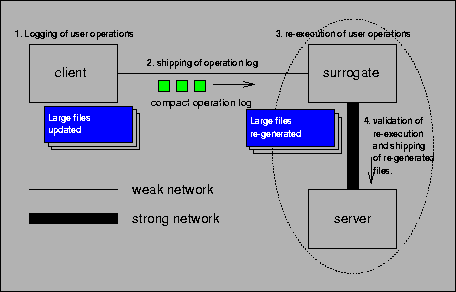
In this paper, we focus on a radically different solution, which is called operation-based update propagation (or operation shipping for brevity). It is motivated by two observations. First, large files are often created or modified by user operations that can be easily intercepted and compactly represented. Second, the cost of shipping and re-executing the user operations is often significantly smaller than that of shipping the large files over a weak network.
To propagate a file, the client ships the operation to a surrogate client that is well connected to the server, as shown in Figure 1. The surrogate re-executes the operation, validates that the re-generated file is identical to the original, and then propagates the file via its high-speed connection to the server. If the file re-generated by the surrogate does not match that from the original execution, the system falls back to shipping the original from the client to the server over the slow connection. This validation and fall-back mechanism is essential to ensure the correctness of update propagation.
The use of a surrogate in our approach ensures that server scalability and security are preserved -- servers are not required to execute potentially malicious and long-running code, nor are they required to instantiate the execution environments of the numerous clients they service. In our model, we assume each mobile client has pre-arranged for a suitable surrogate of an appropriate machine type, at an adequate level of security, possessing suitable authentication tickets, and providing an appropriate execution environment. This assumption is reasonable, since many users of mobile clients also own powerful and well connected personal desktops in their offices, and they can pre-arrange for these otherwise idle personal machines as the surrogates.
Even though the idea of operation shipping is conceptually simple, there are many details that have to be addressed to make it work in practice. In the rest of this paper, we describe how we handle these details by implementing a prototype based on the Coda File System. Our experiment confirms the substantial performance gains of this approach. Depending on the metric and the specific application, we have observed improvements ranging from a factor of three to nearly three orders of magnitude.