Unlike many implementations of Unix, K42 executes much of the fork code in the client, both in the parent and in the forked child, and does not grab a global tree-lock thereby improving concurrency. Concretely, the parent sets up the memory state of the child. It has a record of all the memory mappings (regions) associated with itself, much the same as the Linux kernel keeps track of all regions associated with a process. After setting up the memory of the child, it passes the rest of the state to the child. In Linux, execution normally starts in the child at the instruction of the fork system call. However, in K42, a significant amount of code is executed in the child before branching to the instruction following the fork. This code is similar to what would have been executed in the kernel, such as setting up the file descriptor table, etc.
The K42 model of removing this code from the kernel has several advantages. It reduces the amount of code in the kernel. Any errors that occur in it do not crash the system, but only bring down the process involved in the fork. Perhaps most importantly, it yields an easier programming model as the code does not have to be written assuming fixed sized stacks or written to use a limited amount of pinned memory.
Although implementing the code in user space simplifies programming, the K42 requirement of not holding a global lock throughout such an operation requires careful coding to avoid potential race conditions. Another performance advantage, but programming difficulty, is that when performing a fork-chain collapse (reducing the length of the tree representing forked processes), we do not hold a lock across all the operations but rather lock each individual node independently. Thus, the algorithm must allow for the possibility of multiple in-flight requests (remove and insert). This is discussed in greater detail below.
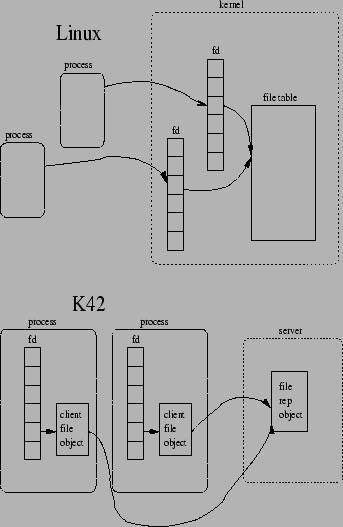
The object-oriented nature of K42 has serious implications when replicating structures such as the file descriptor (fd) table. In Linux, a fd is a pointer into a table (see Figure 3) with associated file reference counts that are incremented when a fork occurs. However, in Linux, the fd table takes kernel memory for each process because it is stored in the kernel's data structure for the process image. In K42, the fd array, which is maintained in user space, points to a series of client file object instances that are in each process's address space (see Figure 3, more information on file descriptor manipulation in K42 is presented in Section 4.5). There is a little more memory that must be replicated on a fork for the fd table in K42.
Although K42's approach avoids explicit replication of the fd array, it introduces post-fork authentication issues. Each of the object instances contains authentication information providing a particular client the right to access a given file. The authentication information contains a PID and thus, although valid for the parent, does not provide the child with permission to access that same file. A call on each file object must be made for the child to obtain permission. This could be an expensive operation if the parent had a large number of open files. It is especially unfortunate because it is unlikely the child will access many of those files as its mostly likely action is to exec. We avoid this potential performance bottleneck by lazily granting access to the child on first access to the file server.
As is frequently the case in programming large systems, the tradeoffs are not clear, and although some aspects of K42's implementation of fork simplified programming or improved performance, other aspects made it more complicated or hurt performance. For K42 native processes (that do not support fork) the model of performing much of the process creation code in user space has been a win. Unfortunately, fork has difficult performance issues. The overhead of implementing fork and exec in user level comes from (1) the cost of passing state from parent to child, rather than just copying in kernel, (2) the extra fault overhead to map in data structures the parent passed to child copy-on-write, (3) the cost of initializing (on exec) and re-initialing (on fork) the system function implemented in user level (e.g., the fd array, memory allocation, etc), and (4) the overhead from our end-to-end authentication scheme (for each file being passed to the child, the server needs to be involved to provide access). Although we bought back most of the fork performance lost due to these issues by lazy (re)initialization, there is still some performance loss and work is underway to reclaim it. Fortunately the performance of fork for most server applications (some benchmarks notwithstanding) is not critical.