The current Linux scheduler has the following two characteristics.
First is a single run queue which is protected by a run queue lock. The run queue is organized as a single double-linked list for all runnable tasks in the system. The scheduler traverses the entire run queue to locate the most deserving process, while holding the run queue lock to ensure exclusive access. As the number of processors increases, the lock contention increases.
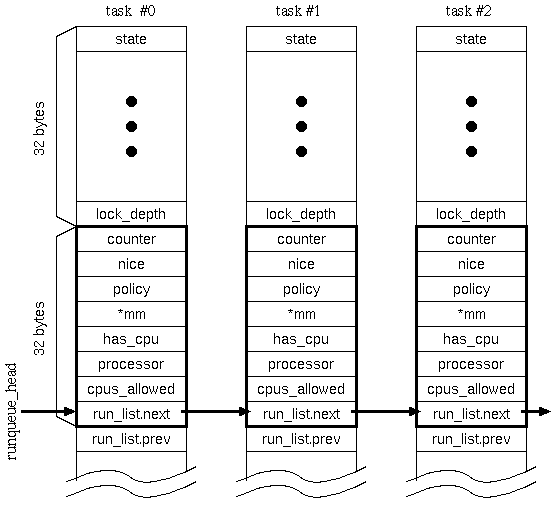
Second is the alignment of task structures in physical memory space. The task structure, which contains the process information, is always aligned on an 8KB boundary in physical address space. The problem of this implementation is that each variable in the task structure is always stored at the same offset address of a page frame. This leads to a strong possibility of cache line conflicts for each variable while the scheduler is traversing the long single run queue. At the same time, a large number of cache misses occur.
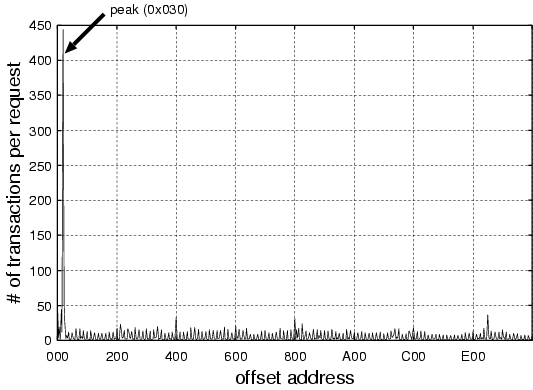
We observed the memory bus transactions by using hardware bus tracer GATES [2]. GATES (General purpose memory Access TracE System) can capture memory transactions on the memory bus of a shared memory multiprocessor system during program execution. Figure 1 shows the statistics of memory traffic on a shared memory bus captured by GATES. In this observation, 256 apache web server processes (httpd) are running on an 4-way Pentium Pro 200 MHz server with 512KB L2-cache each. The vertical axis and the horizontal axis represent the number of transactions per single web request and the page offset address, respectively. As shown in this figure, we can see that a tremendous number of transactions occur on the offset address 0x30. This cache line contains the useful variables of a task structure for scheduling. Figure 2 shows scheduler related variables in a task structure of the 2.4.4 kernel. The 32 bytes block surrounded by the thick line contains the variables which is referred to calculate the priority of each process. And this block also contains the pointer (run_list.next) to the next task structure. The scheduler traverses all of task structures on the run queue by referring this pointer. During the run queue traversal, the block of each task structure is successively transfered to the few cache lines corresponding to the page offset address from 0x20 to 0x3f. This causes a lot of cache conflicts on these cache lines, and a large amount of bus transactions are generated seen as Figure 1.
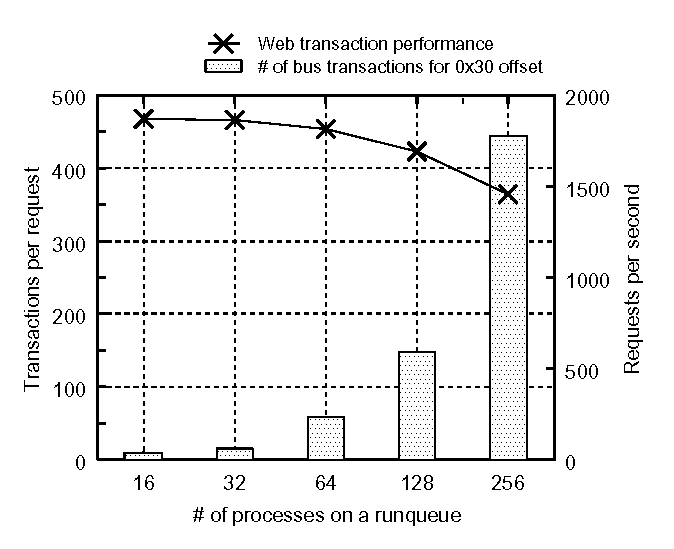
Figure 3 shows the number of transactions to the offset address 0x30 and the web transaction performance. The horizontal axis represents the number of httpd processes linked to the run queue. As the number of httpd processes on the run queue increases, the number of transactions significantly increases and the web transaction performance correspondingly decreases.
|
On SMP systems, the run queue is protected by the run queue lock. When traversing the run queue causes frequent cache misses, the time the processor must spend waiting to fill the cache just adds to the overall traversal time. As the traversal time becomes longer, so does the hold time for the run queue lock. On a multiprocessor system, this contention for cache lines translates into increased lock contention, which becomes a bottleneck for scaling.