| ||||||||||||||||||||||||||||||||||||||||||||||||||||
USENIX Windows NT Workshop, 1997
[Technical Program]
A Scheduling Scheme for Network Saturated NT Multiprocessors
Jørgen Sværke Hansen - Eric Jul -
Abstract:The use of high performance networking technologies, e.g., ATM networks, demands much from both operating systems and processors. During high network loads, user threads may be starved because the processor spends all its time handling interrupts. To alleviate this problem, we propose using a two level network interface servicing scheme that uses interrupts during low network loads to provide low latency, and polling threads during high network loads to avoid thread starvation. In this paper, we examine the use of such a scheme on dual-processor workstations running Windows NT connected by an ATM network. Performance evaluation of our multiprocessor prototype implementation shows that using our two level scheme can improve performance when used carefully.
1 IntroductionHigh performance networks based on, e.g., ATM often demand substantial processor time; so much that processors can become saturated with network traffic leaving little or no time for actually processing data. As part of a project concerning ATM network striping, we have considered how to efficiently handle multiple network interfaces. Processing the data that arrives on just a single high-speed network interface is a problem even for fairly high performance workstations; using several high-speed network interfaces (as we will be doing when performing network striping) will only aggravate the situation. Such processor overload can be handled by using extremely powerful processors. However, there are both economical and physical limits on how fast a processor that it is possible to use. As an alternative we propose using multiprocessors to provide sufficient processing power. Previous work in the area of multiprocessor network performance has concentrated mainly on improving the performance of higher level protocols ([1], [4] and [5]), and furthermore, these approaches use a single network interface. We consider the scheduling issues related to handling one or multiple network interfaces on multiprocessors. In the following, we first describe the problems of thread starvation, then we present a two level network interface servicing scheme that uses interrupt-driven servicing at low network loads, and polling threads at high network loads. Lastly we evaluate the performance of the two level scheme. We have implemented this scheme on dual-processor workstations running Windows NT connected by an ATM network. As network interfaces, we use Olicom ATM network interfaces, and Olicom A/S has provided us with access to the source code for the ATM network interface drivers.
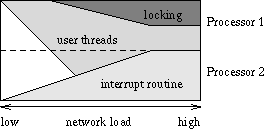
2 User Thread StarvationIn interrupt-driven kernels the total processor usage of a network application can be split into two parts, a part used by the user threads, and a part used by the interrupt-routine. Ideally, the partitioning should be such that the interrupt-routine delivers packets at the rate in which the user thread consumes them. To avoid packet loss in case of timing mismatch between user thread and interrupt-routine, a limited number of packets may be buffered in the I/O subsystem untill the user thread collects them. As long as the total demand for processing power does not exceed what is available, this should cause no problem. When processing power is a problem during heavy network loads, the threads on the system are starved due to the fact that interrupt-routines have absolute priority over any other thread in the system, and thus the bulk of processing time is used processing interrupts from the network interfaces receiving data. The actual consumers of the received data are not allowed to process the data, and this may cause upper layer buffers in the network subsystem to overflow. The result can be that a large amount of processing power is used on receiving data that is subsequently discarded. Mogul and Ramakrishnan [3] identified this problem and propose to avoid this situation (which they call receive livelock) by using interrupt-initiated polling. When a network interface issues an interrupt, its handler merely starts a polling thread. This thread is scheduled together with any other threads in the system, thus reducing the livelock problem. Another benefit from using a polling thread is that the number of interrupts and context switches per received network data unit is lowered in stress situations. The thread starvation problem is not necessarily removed by adding more processors to an interrupt-driven system. Because an interrupt steals processing time from the thread that it is interrupting, there is the danger of starving a thread during heavy network load. On a multiprocessor, a situation (which we call thread pinning) may arise where some processors are almost idle, while another processor is heavily loaded servicing the network interfaces and starving the thread that was to process the incoming data. Furthermore, in the case where a multithreaded user application is used, the user thread workload per packet may be larger than that of the interrupt-routine. This may produce suboptimal performance as illustrated in figure 1. The figure shows how the processor usage is divided between user threads, interrupt-routine and idle time on a two processor machine. As full load is reached, the interrupt-routine starts stealing processor time from the user threads. This continues until the processor usage of the interrupt-routine reaches the capacity of a single processor. If the multiple threads are sharing data, the interrupt-routine might further degrade performance, if it interrupts a thread holding a lock to shared data. As illustrated in figure 2, this will occur when the total load generated by the user threads exceeds the capacity of one processor. From that point the user threads, that are sharing processor with the interrupt-routine, may be interrupted, and thus result in that threads running on the other processor must wait for a lock held by the interrupted thread. In the figure the idle time resulting from this is marked with locking.
To alleviate these problems, the scheduling of network handling on multiprocessors needs to be considered. One possible solution to the thread pinning problem is that the interrupt-handling routine at regular intervals yields the processor, thus allowing the user thread to be rescheduled--possibly on a less loaded processor. Another solution is to utilize that some multiprocessor architectures (e.g., the Pentium Pro) have support for controlling which processor is to receive a given interrupt on the basis of a priority assigned to each processor. As long as there is only one active thread handling network data, and as long as there are fewer network interfaces than processors, this would alleviate the thread pinning problem. Alternatively, one might consider simply disabling interrupts from the network interface(s) causing the overload, but this might hinder the progress of the user threads in the case where they depend on sending data as part of their processing. Lastly, a scheme with a polling thread as described in [3] can be used. By letting one or more threads handle the network interfaces, the usual scheduling mechanism of the operating system may be used to distribute the load on the available processors. This should be able to solve the problems regarding thread pinning, interrupt-routines stealing processor time from user threads and locking. This is illustrated in figure 3. Here the polling routine does not steal cycles from the user thread, and thus the processor time is used in a way that maximizes throughput. Furthermore, as there are no interrupts, threads holding a lock cannot be interrupted. 3 Our Two Level SchemeThe problems described in the previous sections lead us to abandon pure interrupt-driven network interface handling. The network handling based on interrupt-initiated threads seems attractive when the network load is high, but it would be nice to avoid the delay caused by both issuing an interrupt and making a context switch in order to process a packet when the network load is low. We therefore use a two level scheme where interrupt-driven servicing of the network interfaces is used until a certain level of network traffic, and above that level, a polling thread scheme is used.
4 Windows NT ImplementationThis section provides a closer look at how we have implemented this scheme in Windows NT. First we give a brief description of the relevant parts of Windows NT I/O management as this provides the basis for the further discussion. Then we look at how to detect livelock in Windows NT, and finally we discuss how support for this scheme could be integrated with the current Windows NT I/O subsystem.
4.1 Windows NT I/O ManagementIn our description, we use a simplified model of a network protocol stack, where we have a transport driver placed on top of a device driver. In Windows NT, the layers interact by passing I/O Request Packets (IRPs) from one layer to the other. This is done via an I/O manager. In the following we describe how data transmission and reception is handled by this model. On data transmission, the transport driver passes an IRP to the device driver, where the IRP is either processed by a device driver dispatch routine, or--in the case where the device is busy--queued for later processing. When the transmit operation is completed, the IRP is returned to the transport driver. This causes an I/O completion routine to be called in the transport driver. This I/O completion routine is often just a queuing of the IRP for further processing. In the case, where the completion of the transmit operation relies on a hardware interrupt from the device, the dispatch routine would return, and rely on an interrupt handler to complete the transmit operation. The NT interrupt handling consists of two steps - first the hardware interrupt causes the execution of an Interrupt Service Routine (ISR) running at device Interrupt ReQuest Level (IRQL), which does minimal work (e.g., disabling interrupts). This causes a Deferred Procedure Call (DPC) to be queued. This DPC is executed by a software interrupt when the IRQL drops below Dispatch/DPC Level (this is below device IRQL, but above normal thread execution level). This DPC handles the bulk of the processing. When data is received on a device, the data is passed on to the transport driver in an IRP as described above. The IRP queues can either be managed by the device driver or the I/O manager. Transmit operations are handled by a set of device driver dispatch routines. These may rely on interrupts to signal the completion of a transmit operation, and thus a part of the transmit handling is placed in the DPC.
4.2 Detecting User Thread StarvationThe main problem is to detect user thread starvation, i.e., when to make the transition between interrupt-driven and polled I/O. We consider the following possibilities:
We have based our implementation on measuring the interrupt processing time as this is simple to implement. The transition from polled to interrupt-driven I/O is made when the polling thread lacks work to do.
4.3 Operating System SupportAs the work done by the polling thread and the interrupt handlers is almost the same, it would be beneficial to integrate support for both interrupt handling and polling in the operating system. By letting a device driver register routines explicitly for polling threads and interrupt handlers, the I/O Manager can take active part in the decisions on what type of I/O handling to use , e.g., by monitor the execution time of interrupt handlers and initiate polling.
5 ResultsIn the following, we compare our two level scheme with a standard purely interrupt-driven device driver. In order to evaluate the viability of the two level scheme, we look at network latency, thread pinning, and finally we examine the effects of user thread starvation on multithreaded applications.
5.1 MethodologyTo produce an overload situation on the receiving machine, a Dual Pentium Pro 200 MHz host was used as the transmitting side, and a Dual Pentium 133 MHz machine as the receiver. Both machines were running Windows NT 4.0 with service pack 3. The two machines were each equipped with two Olicom RapidFire 155 Mbps ATM adapters. All performance tests have been made using the TCP/IP protocol stack shipped with Windows NT on top of the Olicom driver configured to use Classical IP with a PVC between each pair of network adapters. As network load generator we use the network performance measurement tool netperf. Again, to overload the receiver, we use the UDP protocol. In our two level scheme we used a threshold of 50%, i.e., the transition to polling was made, if an interrupt-routine used more than 50% of the processing time on a single processor for a period of more than two seconds.
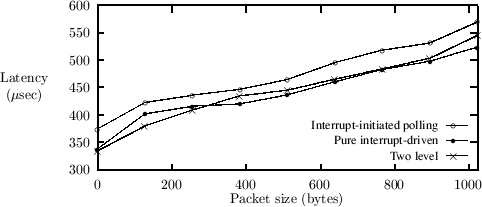
5.2 LatencyTo compare the overhead introduced by using the polling routine, we compare the latency of a pure interrupt-driven system, our two level scheme, and an interrupt-initiated polling routine. The interrupt-initiated polling routine is obtained by modifying the two level scheme implementation, so that all the DPC does is to signal the polling thread. The measurements are illustrated in figure 4, and show that the two level and pure interrupt-driven schemes have about the same latency, which is between 25 and 50 sec higher than the interrupt-initiated polling scheme. Thus, the overhead of monitoring the execution time of the interrupt-routine is negligible, and low latency is achieved at low network load.
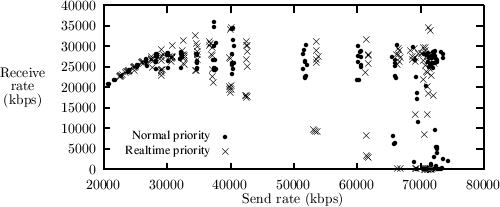
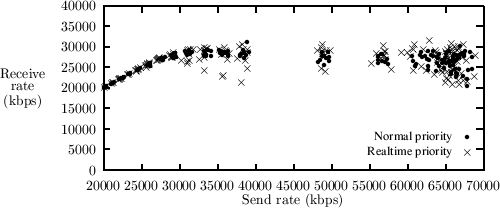
5.3 Thread PinningWhen thread pinning occurs, we expect to see two different levels on the rate of received data, one high level corresponding to the case where the user thread and interrupt-routine execute on different processors, and a low level in the case where they are executing on the same processor. We look at user threads running both at normal and real-time priority. User threads at real-time priority should be more vulnerable to interrupt-routines stealing cycles, as they can only be preempted by threads with higher real-time priority. In figure 5 we show how thread pinning occurs on the receiving machine during a throughput measurement using 1024 bytes UDP packets at various send rates. In order to show the instability and variation in throughput, we conducted 10 measurements for a series of send rates for each priority, and show each of these measurements as a single dot in the graph. As can be seen from the figure, the received rate of the normal priority threads only split into two levels during extremely heavy load. This is due to the fact that only during maximum network load does the interrupt-routine run continuously and thus preventing rescheduling of the user thread. When using the two level scheme (see figure 6), the throughput is more stable although there still is some variation in the measurements at high network load. The polling thread may be interrupted by other threads than our test application, and thus small variations may occur.
When using the real-time priority user level threads, we see that the two levels occur at much lower network load (see figure 5). As the real-time threads are not preempted, they are stuck on the same processor unless they are suspended by system calls or they voluntarily suspends execution. During these tests another problem surfaced--it was often the case that the send rate varied quite a bit, e.g., during tests where a 512 bytes UDP packet was used, the send rate could vary between 32 Mbps and 44 Mbps. This was caused by the sending thread and the interrupt-routine sharing processor. As the load generated by the interrupt-routine on the sending side was lower than 50% polling was not used. In order to evaluate the benefit of polling in this situation, we temporarily reduced the threshold to 20%. This gave a much more stable send rate at approximately 41 Mbps. As the send rate is lower when using a polling thread, this indicates that the polling thread does not run continuously due to the low network load. Thus, the polling routine degrades performance slightly as it consumes processor time without processing interrupts.
5.4 Multithreaded serverIn order to evaluate the effects of interrupt-handling and polling on a multithreaded server, we modified the netperf program, so that multiple threads were used. One thread receives the packets, and places them in a work queue, and one or more worker threads removes packets from the work queue, and simulates processing of the packet. The amount of work done for each packet can be varied, so that the effects of the workload per packet can be studied. Furthermore, we simulate shared data structures by making it possible to specify that a certain amount of the workload must be performed in a critical region. In the following we first show the results of varying the workload in the case where there is no locking, and then we look at the effects of varying the amount of locking at a fixed workload.
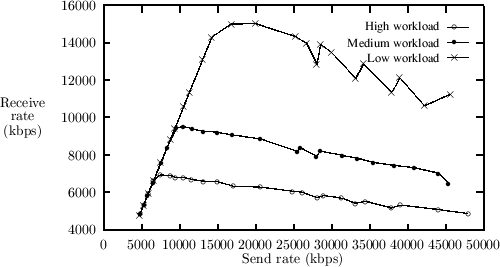
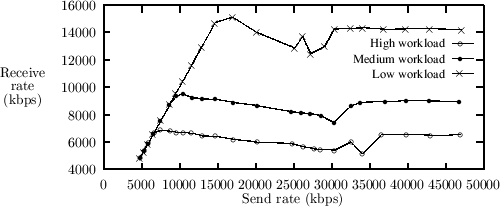
5.4.1 The Effects of WorkloadAs depicted in figure 1 we would expect--in the case were the purely interrupt-driven system is used--the rate of received data to rise to a maximum level and then drop to a lower level corresponding to the situation where the interrupt-routine has exclusive access to one processor. Using polling this should not occur--instead the rate of received data should stabilize near the maximum level. In figure 7 we see how the average throughput of the purely interrupt-driven system drops as the network load increases. However, there is no indication of the low level of network activity. When using the two level scheme (see figure 8), the throughput is almost the same level during high network load as in the case where there is no overload. Figure 8 also illustrates one of the problems with using a fixed processor load limit for deciding when to use thread-based network handling. When the user thread part of the processing of network traffic is large, the overload situation may arise even though the network traffic is not at or near the peak rate. In our case, where the shift occurs at 50%, which in this case corresponds to a transmit rate of 30 to 35 Mbps, the effects of thread-based network handling are first seen above this level.
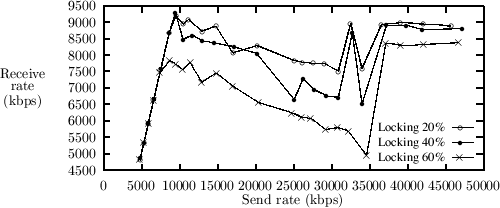
5.4.2 The Effects of LockingIn order to evaluate the effects of sharing data, we conducted a series of throughput measurements, where the user threads were required to hold a lock for either 20%, 40% or 60% of the total packet processing time. In figure 9 we see the effects of interrupt-driven I/O on the part of the graph below the 30000 Kbps send rate, and the effects of using a polling thread above. In the part of the graph representing measurements from interrupt-driven I/O, the slope of the 60% locking curve is considerable steeper than the 20% locking curve, which indicates that increased locking has a negative effect on the received rate. There is no large difference between the curves for 20% and 40% locking, thus the effects of locking are noticeable in the slope of the curves only when a large amount of locking is used. Furthermore, the difference in throughput between the different locking percentages are much lower when the polling thread is used. This indicates that interrupts have influence on locking--especially when intensive locking is used, and that polling threads perform better.
5.5 SummaryOur results show, that problems regarding scheduling of interrupt-routines on multiprocessors exist. In case of extreme network load, user threads may experience thread pinning. Windows NT real-time threads are particularly vulnerable to user thread starvation as they are not rescheduled during high network load due to the lack of preemption. This can be avoided by using polling threads. Alternatively, an interrupt system, which interrupts the thread with the lowest priority, could be used. When using multithreaded applications on multiprocessors, problems with thread starvation may also be experienced. In the case where user threads are sharing data protected by locks, the effects of the user thread starvation caused by interrupt-routines may get worse. This can also be alleviated by using polling threads. The fixed threshold used to shift to polling is a problem in the case where applications have different or variable workloads per packet. As workload intensive applications experience starvation at lower processor loads a threshold based on a fixed processor load is not flexible enough to accommodate a wide range of applications. It would possibly be better to base the shift from interrupt-driven to polling on packet discards in the I/O system.
6 Related WorkThe problems with livelock and the use of polling as a mean to avoid this was first described by Mogul and Ramakrishnan [3]. Furthermore, they reduced the latency increase imposed by pure polling by using interrupts to initiate the polling thread. A periodic polling scheme has been suggested by Smith and Traw [6], where clocked interrupts are used to service an ATM network interface in order to reduce the total number of interrupts. In the Windows NT Kernel-Mode Driver Reference Guide [2] it is suggested, that periodic polling should be used to complete sends, when the total load on the processor, on which the interrupt-routine is executing, exceeds a certain level. This would also reduce user thread starvation, but does not address the problems of unevenly balanced load on multiprocessors.
7 ConclusionWe propose a two level device servicing system that uses interrupt handling during low network loads in order to provide low latency and polling during high network loads in order to prevent user thread starvation. This can be integrated in the I/O system of Windows NT. Our current prototype on a couple of dual processor workstations running Windows NT 4.0 shows that the scheme is able to improve performance on network saturated multiprocessors.
AcknowledgmentsWe wish to thank Olicom A/S, in particular Tomasz Goldman and Kim R. Pedersen, for providing the necessary ATM hardware, for giving us access to their driver source codes, and for providing support in general. The project is funded in part by The Danish Natural Science Foundation and The Danish National Centre for IT Research.
|
|
This paper was originally published in the
Proceedings of the USENIX Windows NT Workshop,
August 11-13, 1997,
Seattle, Washington, USA
Last changed: 15 April 2002 aw |
|