To measure the prototype's backup performance, we used five personal
computers running Microsoft Windows NT, each with a 200 Mhz Pentium Pro
processor, 64 MB of RAM, and a 10 Mbps Ethernet card. The computers
were connected via a 10 Mbps Ethernet hub. We used the
(8,2)-Reed-Solomon erasure-correcting code, which tolerates the failure
of any 2 of 8 partners at the cost of using ![]() extra space,
and simulated 10 participating computers by running two instances of the
prototype software on each PC. Each instance was partnered with the
eight instances located on different PCs from it, so that all
communication between partners went through the network.
extra space,
and simulated 10 participating computers by running two instances of the
prototype software on each PC. Each instance was partnered with the
eight instances located on different PCs from it, so that all
communication between partners went through the network.
We instructed one partner to write either 100 MB or 1 GB of test
data stored on its local disk to its logical disk to simulate saving a
snapshot; during this time, the other partners were idle except for
processing write requests. The prototype uses the procedure described
in Section 2.3 with ![]() to write snapshots:
writes to partners occur in parallel, but are not pipelined with the
reading and preparing of the blocks to be written, and at most one write
is in progress at each partner at a time.
to write snapshots:
writes to partners occur in parallel, but are not pipelined with the
reading and preparing of the blocks to be written, and at most one write
is in progress at each partner at a time.
Using this unoptimised procedure, the prototype is able to write 100 MB in 12 minutes and 1 GB in 2 hours. This corresponds to a backup rate of 1.0 Mbps and a write rate of 1.3 Mbps (larger because of the redundancy blocks that must be written). Optimization would improve these rates, but since they are already larger than the bandwidth many Internet connections provide, it is not clear how useful this would be.
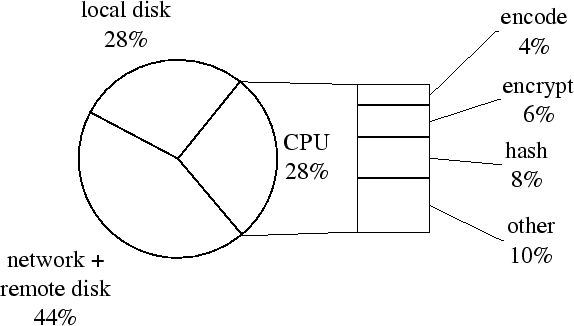
Figure 7 breaks down the contributions to the backup time made by the local disk (mostly reads), the remote-writing step (mostly network and partner delays), and the various CPU-intensive tasks. The remote-writing step consumes the largest portion (44%) of the total time, presumedly due to our allowing only one outstanding write to a given partner at a time. Hashing requires more time (8%) than encryption (6%) because it must be done twice for each block: once to generate the stored-block checksum and once to authenticate the write request containing that block to the partner. (Separate keys, and hence hashes, are required because the integrity key must be kept secret from the partner.)