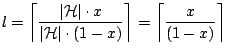We begin by using simulation to evaluate a naive heuristic called Random that we use as a basis for comparison. It is not a greedy
heuristic and does not reference the advertised
configurations. Instead, ![]() simply chooses at random a subset of
simply chooses at random a subset of
![]() of a given size containing
of a given size containing ![]() .
.
The first row of Table 3 shows the results of
Random using one run of our simulator. We set the size of
the cores to 5, i.e., Random chose 5 random hosts to form
a core. The coverage of 0.977 may seem high, but there are still many
cores that have uncovered attributes and choosing a core
size smaller than five results in even lower coverage. The load is 12, which is significantly higher than the lower bound of 5.2
|
Our first greedy heuristic Uniform (``uniform'' selection among
operating systems) operates as follows. First, it chooses a host with
a different operating system than ![]() to cover this
attribute. Then, for each attribute
to cover this
attribute. Then, for each attribute
![]() , it
chooses both a container
, it
chooses both a container
![]() and a sub-container
and a sub-container
![]() at
random. Finally, it chooses a host
at
random. Finally, it chooses a host ![]() at random from
at random from ![]() . If
. If
![]() then it includes
then it includes ![]() in Core
in Core![]() . Otherwise,
it tries again by choosing a new container
. Otherwise,
it tries again by choosing a new container ![]() , sub-container
, sub-container ![]() , and
host
, and
host ![]() at random. Uniform repeats this procedure
diff_OS times in an attempt to cover
at random. Uniform repeats this procedure
diff_OS times in an attempt to cover ![]() with Core
with Core![]() .
If it fails to cover
.
If it fails to cover ![]() , then the heuristic tries up
to same_OS times to cover
, then the heuristic tries up
to same_OS times to cover ![]() by choosing a
sub-container
by choosing a
sub-container
![]() at random and a host
at random and a host ![]() at random
from
at random
from ![]() .
.
The goal for having two steps, one with diff_OS and
another with same_OS, is to first exploit diversity
across operating systems, and then to exploit diversity among hosts
within the same operating system group. Referring back to
Figure 1, the set of prevalent services among
hosts running the same operating system varies across the different
operating systems. In the case the attribute cannot be
covered with hosts running other operating systems, the diversity
within an operating system group may be sufficient to find a host ![]() without attribute
without attribute ![]() .
.
In all of our simulations, we set diff_OS to 7 and same_OS to 4. After experimentation, these values have provided a good trade-off between number of useless tries and obtaining good coverage. However, we have yet to study how to in general choose good values of diff_OS and same_OS.
Pseudo-code for Uniform is as follows.

The second row of Table 3 shows the performance of
Uniform for a representative run of our simulator. The core size
is close to the minimum size of two, and the coverage is very close to
the ideal value of one. This means that using Uniform results in
significantly better capacity and improved resilience than Random. On the other hand, the load is very high: there is at least
one host that participates in 284 cores. The load is so high because
![]() chooses containers and sub-containers uniformly. When constructing
the cores for hosts of a given operating system, the other containers
are referenced roughly the same number of times. Thus, Uniform
considers hosts running less prevalent operating systems for inclusion
in cores a disproportionately large number of times. A similar argument
holds for hosts running less popular applications.
chooses containers and sub-containers uniformly. When constructing
the cores for hosts of a given operating system, the other containers
are referenced roughly the same number of times. Thus, Uniform
considers hosts running less prevalent operating systems for inclusion
in cores a disproportionately large number of times. A similar argument
holds for hosts running less popular applications.
This behavior suggests refining the heuristic to choose containers and
applications weighted on the popularity of their operating systems and
applications. Given a container ![]() , let
, let ![]() be the number of
distinct hosts in the sub-containers of
be the number of
distinct hosts in the sub-containers of ![]() , and given a set of
containers
, and given a set of
containers ![]() , let
, let ![]() be the sum of
be the sum of ![]() for all
for all ![]() .
The heuristic Weighted (``weighted'' OS selection) is the same
as Uniform except that for the first diff_OS
attempts,
.
The heuristic Weighted (``weighted'' OS selection) is the same
as Uniform except that for the first diff_OS
attempts, ![]() chooses a container
chooses a container ![]() with probability
with probability
![]() . Heuristic DWeighted (``doubly-weighted'' selection) takes this a step
further. Let
. Heuristic DWeighted (``doubly-weighted'' selection) takes this a step
further. Let ![]() be
be ![]() and
and ![]() be the size
of the union of
be the size
of the union of ![]() for all
for all ![]() . Heuristic DWeighted is the same as Weighted except that, when considering
attribute
. Heuristic DWeighted is the same as Weighted except that, when considering
attribute ![]() ,
, ![]() chooses a host from sub-container
chooses a host from sub-container ![]() with probability
with probability
![]() .
.
In the third and fourth rows of Table 3, we show a representative run of our simulator for both of these variations. The two variations result in comparable core sizes and coverage as Uniform, but significantly reduce the load. The load is still very high, though: at least one host ends up being assigned to over 80 cores.
Another approach to avoid a high load is to simply disallow it at the risk
of decreasing the coverage. That is, for some value of ![]() , once a
host
, once a
host ![]() is included in
is included in ![]() cores,
cores, ![]() is removed from the structure
of advertised configurations. Thus, the load of any host is
constrained to be no larger than
is removed from the structure
of advertised configurations. Thus, the load of any host is
constrained to be no larger than ![]() .
.
What is an effective value of ![]() that reduces load while still
providing good coverage? We answer this question by first
establishing a lower bound on the value of
that reduces load while still
providing good coverage? We answer this question by first
establishing a lower bound on the value of ![]() . Suppose that
. Suppose that ![]() is
the most prevalent attribute (either service or operating system)
among all attributes, and it is present in a fraction
is
the most prevalent attribute (either service or operating system)
among all attributes, and it is present in a fraction ![]() of the host
population. As a simple application of the pigeonhole principle, some
host must be in at least
of the host
population. As a simple application of the pigeonhole principle, some
host must be in at least ![]() cores, where
cores, where ![]() is defined as:
is defined as:
Thus, the value of ![]() cannot be smaller than
cannot be smaller than ![]() . Using
Table 2, we have that the most prevalent attribute (port
139) is present in 55.3% of the hosts. In this case,
. Using
Table 2, we have that the most prevalent attribute (port
139) is present in 55.3% of the hosts. In this case, ![]() .
.
Using simulation, we now evaluate our heuristics in terms of core
size, coverage, and load as a function of the load limit ![]() .
Figures 4-7 present the results of our
simulations. In these figures, we vary
.
Figures 4-7 present the results of our
simulations. In these figures, we vary ![]() from the minimum 2 through
a high load of 10. All the points shown in these graphs are the
averages of eight simulated runs with error bars (although they are
too narrow to be seen in some cases). For
Figures 4-6, we use the standard
error to determine the limits of the error bars, whereas for
Figure 7 we use the maximum and minimum observed among
our samples. When using load limit as a threshold, the order in which
hosts request cores from
from the minimum 2 through
a high load of 10. All the points shown in these graphs are the
averages of eight simulated runs with error bars (although they are
too narrow to be seen in some cases). For
Figures 4-6, we use the standard
error to determine the limits of the error bars, whereas for
Figure 7 we use the maximum and minimum observed among
our samples. When using load limit as a threshold, the order in which
hosts request cores from ![]() will produce different results. In
our experiments, we randomly choose eight different orders of
enumerating
will produce different results. In
our experiments, we randomly choose eight different orders of
enumerating ![]() for constructing cores. For each heuristic, each
run of the simulator uses a different order. Finally, we vary the
core size of Random using the load limit
for constructing cores. For each heuristic, each
run of the simulator uses a different order. Finally, we vary the
core size of Random using the load limit ![]() to illustrate its
effectiveness across a range of core sizes.
to illustrate its
effectiveness across a range of core sizes.
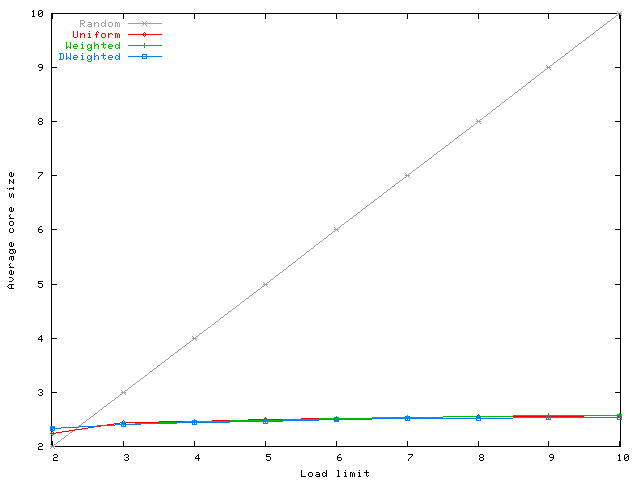
Figure 4 shows the average core size for the four
algorithms for different values of ![]() . According to this graph,
Uniform, Weighted, and DWeighted do not differ
much in terms of core size.
The average core size
of Random increases linearly with
. According to this graph,
Uniform, Weighted, and DWeighted do not differ
much in terms of core size.
The average core size
of Random increases linearly with ![]() by design.
by design.
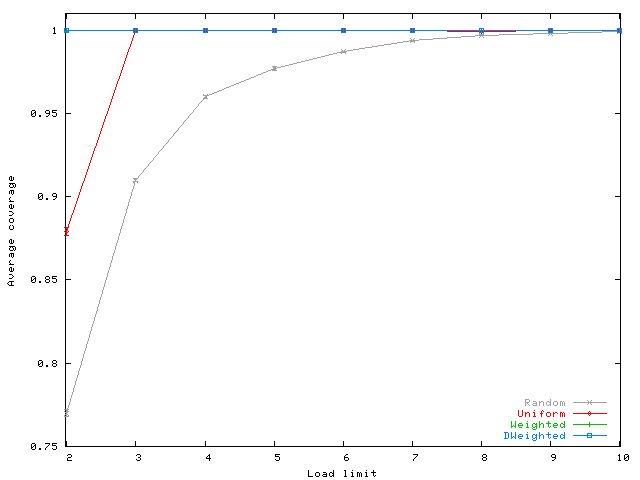
In Figure 5, we show results for coverage. Coverage
is slightly smaller than ![]() for Uniform, Weighted, and
DWeighted when
for Uniform, Weighted, and
DWeighted when ![]() is greater or equal to three. For
is greater or equal to three. For ![]() ,
Weighted and DWeighted still have coverage slightly
smaller than
,
Weighted and DWeighted still have coverage slightly
smaller than ![]() , but Uniform does significantly worse. Using
weighted selection is useful when
, but Uniform does significantly worse. Using
weighted selection is useful when ![]() is small. Random improves
coverage with increasing
is small. Random improves
coverage with increasing ![]() because the size of the cores
increases. Note that, to reach the same value of coverage obtained by
the other heuristics, Random requires a large core size of
because the size of the cores
increases. Note that, to reach the same value of coverage obtained by
the other heuristics, Random requires a large core size of ![]() .
.
There are two other important observations to make about this graph.
First, coverage is roughly the same for Uniform, Weighted,
and DWeighted when ![]() .
Second, as
.
Second, as ![]() continues to increase, there is a small decrease in
coverage. This is due to the nature of our traces and to the
random choices made by our algorithms. Ports such as 111
(portmapper, rpcbind) and 22 (sshd) are open on several of the
hosts with operating systems different than Windows. For small
values of
continues to increase, there is a small decrease in
coverage. This is due to the nature of our traces and to the
random choices made by our algorithms. Ports such as 111
(portmapper, rpcbind) and 22 (sshd) are open on several of the
hosts with operating systems different than Windows. For small
values of ![]() , these hosts rapidly reach their threshold.
Consequently, when hosts that do have these services as attributes
request a core, there are fewer hosts available with these same
attributes. On the other hand, for larger values of
, these hosts rapidly reach their threshold.
Consequently, when hosts that do have these services as attributes
request a core, there are fewer hosts available with these same
attributes. On the other hand, for larger values of ![]() , these
hosts are more available, thus slightly increasing the probability
that not all the attributes are covered for hosts executing an
operating system different than Windows. We observed this
phenomenon exactly with ports 22 and 111 in our traces.
, these
hosts are more available, thus slightly increasing the probability
that not all the attributes are covered for hosts executing an
operating system different than Windows. We observed this
phenomenon exactly with ports 22 and 111 in our traces.
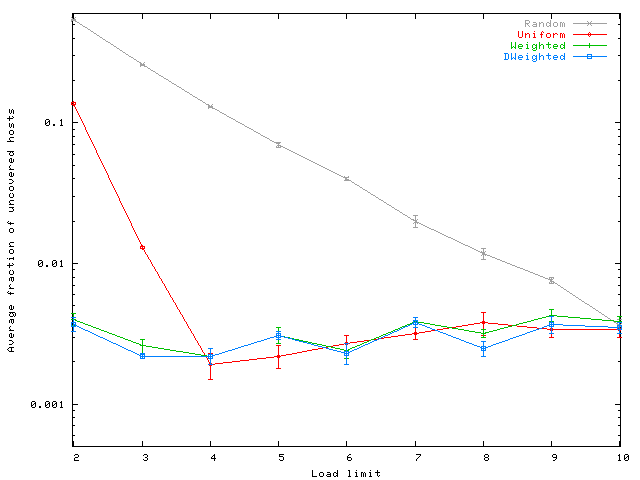
This same phenomenon can be observed in Figure 6. In this figure, we plot the average fraction of hosts that are not fully covered, which is an alternative way of visualizing coverage. We observe that there is a share of the population of hosts that are not fully covered, but this share is very small for Uniform and its variations. Such a set is likely to exist due to the non-deterministic choices we make in our heuristics when forming cores. These uncovered hosts, however, are not fully unprotected. From our simulation traces, we note the average number of uncovered attributes is very small for Uniform and its variations. In all runs, we have just a few hosts that do not have all their attributes covered, and in the majority of the instances there is just a single uncovered attribute.
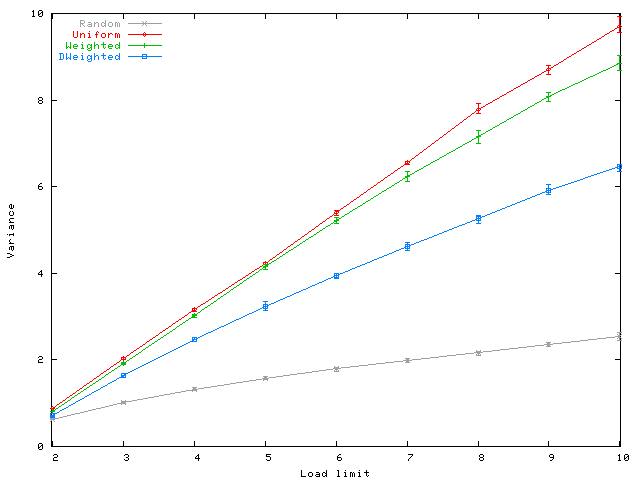
Finally, we show the resulting variance in load. Since the heuristics
limit each host to be in no more than ![]() cores, the maximum load
equals
cores, the maximum load
equals ![]() . The variance indicates how fairly the load is
spread among the hosts. As expected, Random does well, having
the lowest variance among all the algorithms and for all values of
. The variance indicates how fairly the load is
spread among the hosts. As expected, Random does well, having
the lowest variance among all the algorithms and for all values of
![]() . Ordering the greedy heuristics by their variance in load, we have
Uniform
. Ordering the greedy heuristics by their variance in load, we have
Uniform ![]() Weighted
Weighted ![]() DWeighted. This is
not surprising since we introduced the weighted selection exactly to
better balance the load. It is interesting to observe that for every
value of
DWeighted. This is
not surprising since we introduced the weighted selection exactly to
better balance the load. It is interesting to observe that for every
value of ![]() , the load variance obtained for Uniform is close to
, the load variance obtained for Uniform is close to
![]() . This means that there were several hosts not participating in any
core and several other hosts participating in
. This means that there were several hosts not participating in any
core and several other hosts participating in ![]() cores.
cores.
A larger variance in load may not be objectionable in practice as long
as a maximum load is enforced. Given the extra work of maintaining the
functions ![]() and
and ![]() , the heuristic Uniform with small
, the heuristic Uniform with small ![]() (L > 2) is the best choice for our application. However, should load
variance be an issue, we can use one of the other heuristics.
(L > 2) is the best choice for our application. However, should load
variance be an issue, we can use one of the other heuristics.