
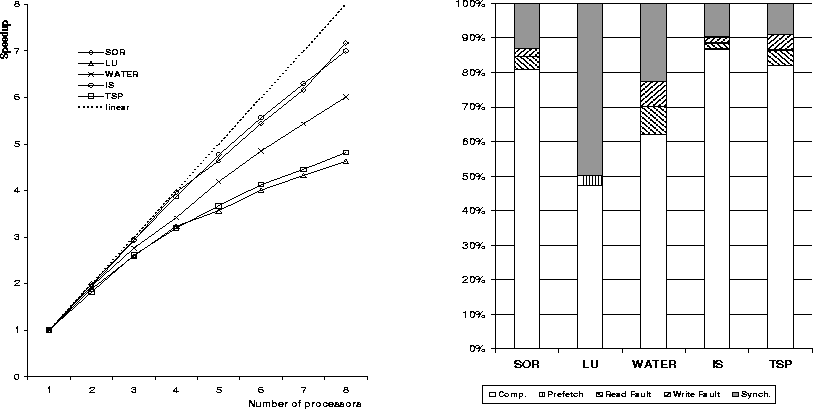
Figure 6 summarizes the speedups on MILLIPAGE for each of the applications, when executing on 1 to 8 processors.
When examining the results, one should keep in mind that
because of the FM polling problem and the
large-grain timers described in Section 3.5,
our system suffers from relatively high delays in servicing minipage
requests.
Since the resolution of the operating system timers is constrained
to 1 ms (and is extremely inaccurate, see Section
3.5.1 and [11]),
we experienced an average
delay of about 750 ![]() for minipage requests.
Only about a third of the delay comes from the DSM layer (see
Section 4.2 above), while the rest is due to the slow
response of the server thread: an average of more than 500
for minipage requests.
Only about a third of the delay comes from the DSM layer (see
Section 4.2 above), while the rest is due to the slow
response of the server thread: an average of more than 500 ![]() .
.
Despite the above, our initial experience with MILLIPAGE shows encouraging results. IS and SOR achieved speedups that are close to linear: the efficient resolution of false sharing led to a relatively small communication volume. WATER's performance was comparable to that achieved in reduced consistency systems. This performance was achieved by chunking molecules in larger minipages, a method that we describe later in this section.
LU achieved relatively good results, mainly due to the thin DSM layer which reduces the protocol overhead. In addition, in order to minimize the large minipage service delays explained above, we inserted two prefetch calls during the LU computation. We believe that this prefetch mechanism will not be needed once the FM polling problem is resolved, and/or the operating system timer resolution is refined.
False sharing was resolved in TSP, except for a single data race for updating the minimal tour found so far. Although the modification of this variable is protected by means of mutual exclusion, it is frequently read through an unprotected section. We changed a single code line in which this variable is updated, so that it pushes readable copies of the new value to all hosts. It is instructive to consider the minipage allocation size, which is equal to that of a tour element: 148 bytes. Providing granularity of 128 or 256 bytes (``cleaner'' numbers that divide a page size) may involve a large increase in false sharing due to the pattern in which TSP assigns tours to processors: two adjacent tours are often assigned to two different processors.
 |