
As in the experiments of the last section, two VSs (www1 and www2) were created and each was assigned half of the machine's CPU capacity. The first experiment (Apache insulation only) executes the FCGI outside the VS context of either site so that it could utilize all unused server capacity.
In the second round (dynamic FCGI-to-VS binding) we loaded the additional accept and socket gates to police access to the FCGI, which received its requests via TCP. The following classification rules were instantiated:
(accept, www[1|2], req = www[2|1]) => (www[2|1])
The accept rules cause the FCGI to change its resource binding
if it is executing in the VS context of www1 ( www2)
and receives a request from www2 (www1) to www2
(www1). Moreover, accept reorders requests in the order
of their VS's remaining resource share as explained in Section 4.
The default socket rule associates a new socket with its creator's
VS. This ensures that requests sent to the shared FCGI will have appropriate
TOS markings. To establish a baseline for optimal insulation, we replicated
the FCGI script in each VS context (replicated FCGI). This cannot be done
in real setups because many applications are not designed to be replicated.
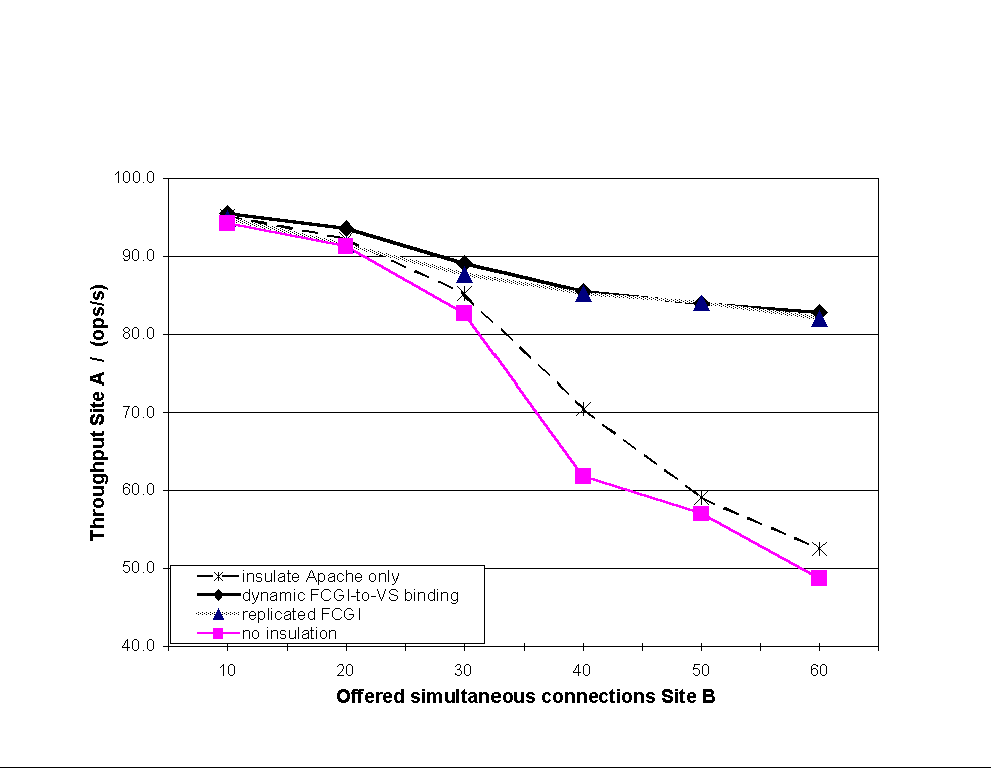 |
As Figure 12 shows, sharing the FCGI without the accept gate breaks the insulation between sites A and B (Apache insulation only); the performance of Site A decreases rapidly as the load on Site B increases. This effect can be traced back to the contention for the shared FCGI. With the accept gate (dynamic FCGI-to-VS binding), the performance of Site A drops at a much slower, nearly the pace for replicated FCGI. The benefit of using the accept gate is a performance improvement for the well-behaved site (well-behaved means that its clients do not overload the site) of approximately 60% under maximal load. Further experiments show that the accept gate for dynamic VS bindings performs almost as well as if the shared service were replicated for each VS (replicated FCGI). The ill-behaved Site B suffers from overloading its CPU share. This results in a 10% loss of aggregated performance compared to the ideal case of a replicated FCGI under peak load. The reason for this is that the ill-behaved site uses its resources mainly on serving static HTTP requests. Only when the number of queued-up FCGI requests is large will its FCGI requests be processed. During those times Site B operates mostly sequentially.
Without changing Apache this problem could not have been solved using RC's or any other approach presented in Section 2, because the resource binding for the FCGI must be dynamic, assuming it cannot be replicated.